Coverage Improvement and Fast Convergence of On-policy Preference Learning
作者: Juno Kim, Jihun Yun, Jason D. Lee, Kwang-Sung Jun
分类: cs.LG
发布日期: 2026-01-13
备注: 46 pages, 2 figures, 2 tables
💡 一句话要点
提出覆盖改进原则,加速在线偏好学习语言模型对齐的收敛
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 在线偏好学习 语言模型对齐 覆盖改进原则 直接策略优化 奖励提炼 G-最优设计 上下文bandit 快速收敛
📋 核心要点
- 现有离线偏好学习算法在语言模型对齐方面存在性能瓶颈,而在线算法表现更优,但缺乏理论解释。
- 论文提出“覆盖改进原则”,证明在线策略学习通过不断改进数据覆盖,加速模型收敛到目标策略。
- 实验结果表明,在线DPO和提出的奖励提炼算法优于离线算法,并在迭代过程中性能稳定提升。
📝 摘要(中文)
本文针对语言模型对齐的在线策略偏好学习算法,如在线直接策略优化(DPO),其性能显著优于离线算法。论文通过分析采样策略在在线训练中的覆盖演变,为这一现象提供了理论解释。提出了“覆盖改进原则”:在足够大的批次下,每次更新都会进入目标周围覆盖更均匀的区域,使后续数据更具信息量,从而实现快速收敛。在具有Bradley-Terry偏好和线性softmax策略类的上下文bandit环境中,证明了在线DPO在批次大小超过广义覆盖阈值时,收敛速度呈指数级。相反,任何仅限于初始策略离线样本的学习器都会遭受较慢的极小极大速率,导致总样本复杂度的显著差异。受此分析的启发,进一步提出了一种基于新型“优先”G-最优设计的混合采样器,消除了对覆盖的依赖,并保证在两轮内收敛。最后,为通用函数类设置中的奖励提炼开发了基于原则的在线方案,并在基于偏差的覆盖概念下展示了更快的无噪声速率。实验证实,在线DPO和所提出的奖励提炼算法优于其离线对应算法,并在迭代中享受稳定、单调的性能提升。
🔬 方法详解
问题定义:论文旨在解决在线偏好学习算法(如DPO)在语言模型对齐中优于离线算法的现象缺乏理论解释的问题。现有离线算法的痛点在于,它们受限于初始策略生成的数据,无法充分探索策略空间,导致收敛速度慢,性能提升有限。
核心思路:论文的核心思路是提出“覆盖改进原则”,即在线策略学习算法通过不断更新策略,使得采样数据在目标策略周围的覆盖范围越来越好,从而使后续数据包含更多有用的信息,加速收敛。这种思路强调了在线学习中数据分布动态变化的重要性。
技术框架:论文的技术框架主要包含以下几个部分:1) 理论分析:在上下文bandit环境中,使用Bradley-Terry偏好和线性softmax策略类,证明了在线DPO的指数级收敛速度。2) 混合采样器设计:提出基于“优先”G-最优设计的混合采样器,以消除对覆盖的依赖,保证快速收敛。3) 奖励提炼方案:为通用函数类设置开发了基于原则的在线奖励提炼方案。
关键创新:论文最重要的技术创新点在于提出了“覆盖改进原则”,并从理论上证明了其有效性。此外,基于“优先”G-最优设计的混合采样器也是一个创新点,它能够消除对覆盖的依赖,实现更快的收敛。与现有方法的本质区别在于,论文强调了在线学习中数据分布动态变化的重要性,并提出了相应的理论和算法。
关键设计:论文的关键设计包括:1) 广义覆盖阈值的定义,用于确定在线DPO的收敛速度。2) “优先”G-最优设计的具体实现,用于构建混合采样器。3) 基于偏差的覆盖概念,用于分析奖励提炼方案的性能。具体的参数设置和损失函数等细节在论文中进行了详细描述(未知)。
🖼️ 关键图片
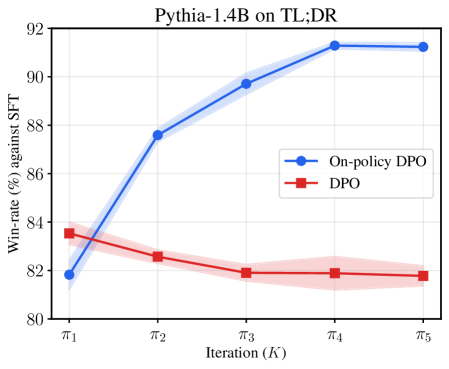
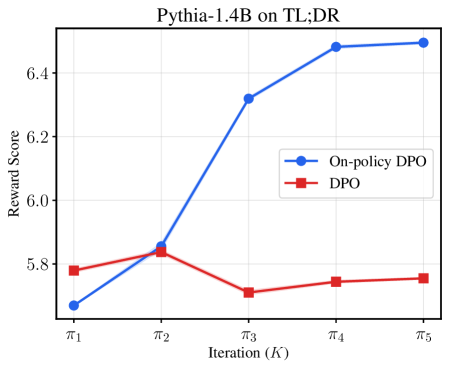
📊 实验亮点
论文通过实验验证了在线DPO和提出的奖励提炼算法优于离线算法,并在迭代过程中性能稳定提升。具体的性能数据和提升幅度在论文中进行了详细展示(未知)。实验结果表明,在线学习算法能够更有效地利用数据,实现更快的收敛和更好的性能。
🎯 应用场景
该研究成果可应用于各种需要语言模型对齐的场景,例如对话系统、文本生成、机器翻译等。通过利用在线偏好学习算法,可以更有效地训练语言模型,使其更好地符合人类的偏好和意图,从而提升用户体验和应用效果。此外,该研究提出的覆盖改进原则和混合采样器设计,也可以为其他在线学习算法的设计提供借鉴。
📄 摘要(原文)
Online on-policy preference learning algorithms for language model alignment such as online direct policy optimization (DPO) can significantly outperform their offline counterparts. We provide a theoretical explanation for this phenomenon by analyzing how the sampling policy's coverage evolves throughout on-policy training. We propose and rigorously justify the \emph{coverage improvement principle}: with sufficient batch size, each update moves into a region around the target where coverage is uniformly better, making subsequent data increasingly informative and enabling rapid convergence. In the contextual bandit setting with Bradley-Terry preferences and linear softmax policy class, we show that on-policy DPO converges exponentially in the number of iterations for batch size exceeding a generalized coverage threshold. In contrast, any learner restricted to offline samples from the initial policy suffers a slower minimax rate, leading to a sharp separation in total sample complexity. Motivated by this analysis, we further propose a simple hybrid sampler based on a novel \emph{preferential} G-optimal design, which removes dependence on coverage and guarantees convergence in just two rounds. Finally, we develop principled on-policy schemes for reward distillation in the general function class setting, and show faster noiseless rates under an alternative deviation-based notion of coverage. Experimentally, we confirm that on-policy DPO and our proposed reward distillation algorithms outperform their off-policy counterparts and enjoy stable, monotonic performance gains across iterations.