Scalable Multiagent Reinforcement Learning with Collective Influence Estimation
作者: Zhenglong Luo, Zhiyong Chen, Aoxiang Liu, Ke Pan
分类: cs.LG
发布日期: 2026-01-13
💡 一句话要点
提出基于集体影响估计网络(CIEN)的可扩展多智能体强化学习框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多智能体强化学习 集体影响估计 可扩展性 通信受限 机器人协作
📋 核心要点
- 现有MARL方法依赖频繁的信息交换,限制了在通信受限的实际机器人系统中的应用。
- 提出CIEN框架,通过建模智能体对任务对象的集体影响,实现高效协作,无需显式信息交换。
- 实验表明,该方法在通信受限环境下实现了稳定高效的协调,并提高了真实机器人平台的鲁棒性和部署可行性。
📝 摘要(中文)
多智能体强化学习(MARL)在解决复杂协作任务方面具有巨大潜力,但现有方法通常依赖于智能体之间频繁交换动作或状态信息来实现有效协调,这在实际机器人系统中难以满足。一种常见的解决方案是引入估计器网络来建模其他智能体的行为并预测其动作;然而,这种设计导致估计器网络的规模和计算成本随着智能体数量的增加而迅速增长,从而限制了大规模系统的可扩展性。为了解决这些挑战,本文提出了一种基于集体影响估计网络(CIEN)的多智能体学习框架。通过显式地建模其他智能体对任务对象的集体影响,每个智能体可以仅从其局部观察和任务对象的状态推断关键的交互信息,从而在没有显式动作信息交换的情况下实现高效协作。所提出的框架有效地避免了网络随着团队规模的增加而扩展;此外,可以在不修改现有智能体的网络结构的情况下合并新的智能体,从而表现出强大的可扩展性。基于软演员-评论家(SAC)算法的多智能体协作任务的实验结果表明,该方法在通信受限的环境下实现了稳定高效的协调。此外,使用集体影响建模训练的策略被部署在真实的机器人平台上,实验结果表明,该方法显著提高了鲁棒性和部署可行性,并降低了对通信基础设施的依赖。
🔬 方法详解
问题定义:现有MARL方法在解决多智能体协作任务时,通常需要智能体之间频繁交换动作或状态信息,这在通信受限或大规模系统中变得不可行。此外,使用估计器网络预测其他智能体的行为会导致网络规模和计算成本随着智能体数量的增加而迅速增长,限制了系统的可扩展性。
核心思路:该论文的核心思路是通过建模其他智能体对任务对象的集体影响,使每个智能体能够仅从局部观察和任务对象的状态推断关键的交互信息,从而实现高效协作,而无需显式地交换动作信息。这种方法避免了网络规模随着智能体数量的增加而线性增长的问题,提高了系统的可扩展性。
技术框架:该框架包含多个智能体和一个任务对象。每个智能体都有一个策略网络,用于根据局部观察和任务对象的状态选择动作。此外,每个智能体还使用一个集体影响估计网络(CIEN)来估计其他智能体对任务对象的集体影响。CIEN的输入是任务对象的状态和智能体的局部观察,输出是集体影响的估计值。智能体的策略网络使用集体影响的估计值来调整其动作,从而实现协作。
关键创新:该论文最重要的技术创新点是提出了集体影响估计网络(CIEN),它能够显式地建模其他智能体对任务对象的集体影响。与现有方法相比,CIEN不需要智能体之间交换动作信息,并且其规模不随智能体数量的增加而线性增长,从而提高了系统的可扩展性。
关键设计:CIEN的网络结构可以根据具体任务进行设计。在实验中,作者使用了一个多层感知机(MLP)作为CIEN的网络结构。损失函数的设计目标是使CIEN的输出能够准确地估计其他智能体对任务对象的集体影响。作者使用了一种基于时间差分(TD)误差的损失函数来训练CIEN。此外,作者还使用了一种基于软演员-评论家(SAC)算法的策略优化方法来训练智能体的策略网络。
🖼️ 关键图片


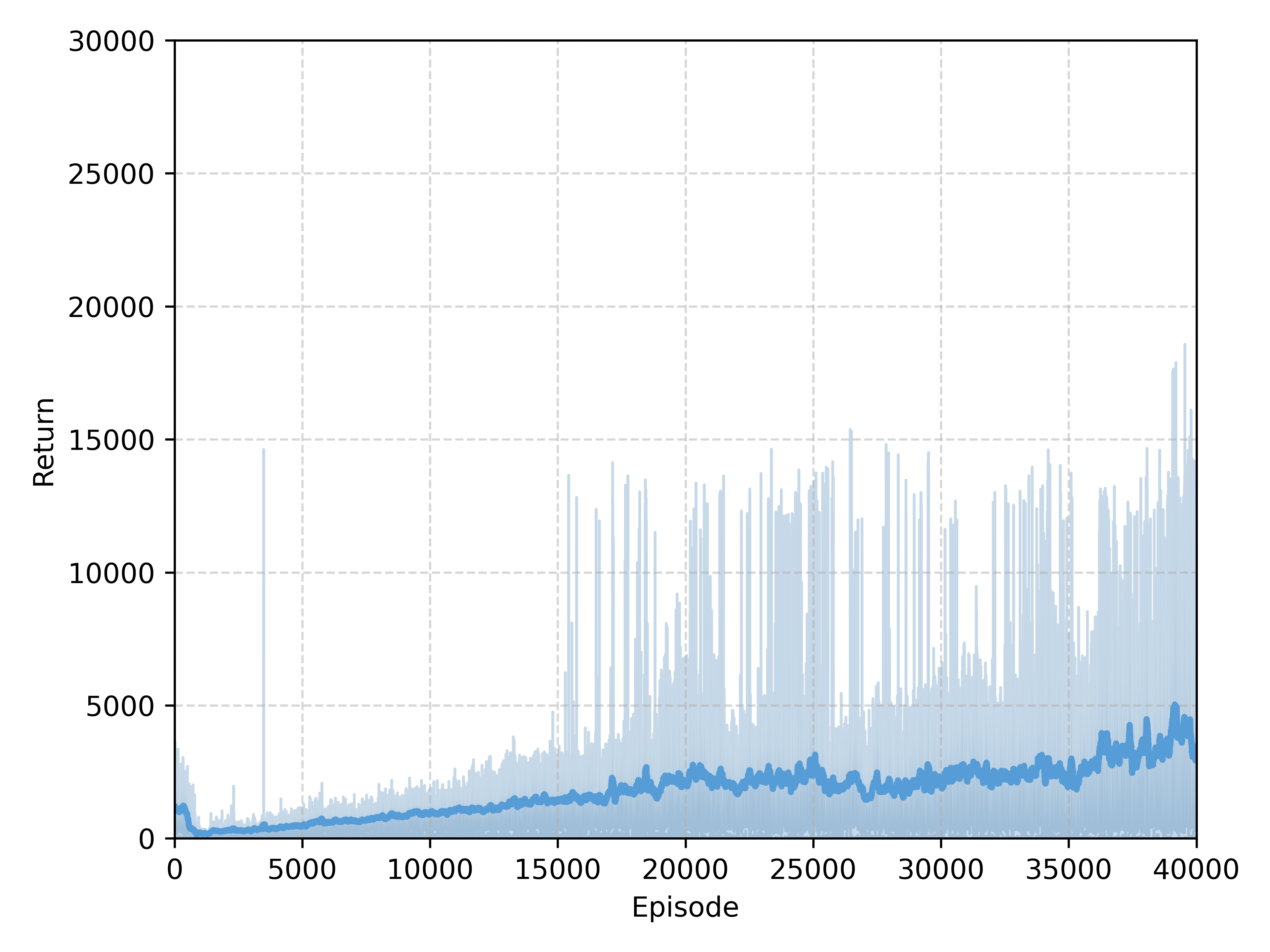
📊 实验亮点
实验结果表明,所提出的方法在通信受限的环境下实现了稳定高效的协调。与基线方法相比,该方法在多智能体协作任务中取得了显著的性能提升。此外,将训练好的策略部署在真实的机器人平台上,实验结果表明,该方法显著提高了鲁棒性和部署可行性,并降低了对通信基础设施的依赖。
🎯 应用场景
该研究成果可应用于各种多智能体协作任务,例如多机器人协同搬运、自动驾驶车辆编队行驶、以及智能交通控制等领域。通过降低对通信基础设施的依赖,并提高系统的可扩展性,该方法有望推动多智能体系统在实际场景中的广泛应用,并提升系统的鲁棒性和效率。
📄 摘要(原文)
Multiagent reinforcement learning (MARL) has attracted considerable attention due to its potential in addressing complex cooperative tasks. However, existing MARL approaches often rely on frequent exchanges of action or state information among agents to achieve effective coordination, which is difficult to satisfy in practical robotic systems. A common solution is to introduce estimator networks to model the behaviors of other agents and predict their actions; nevertheless, such designs cause the size and computational cost of the estimator networks to grow rapidly with the number of agents, thereby limiting scalability in large-scale systems. To address these challenges, this paper proposes a multiagent learning framework augmented with a Collective Influence Estimation Network (CIEN). By explicitly modeling the collective influence of other agents on the task object, each agent can infer critical interaction information solely from its local observations and the task object's states, enabling efficient collaboration without explicit action information exchange. The proposed framework effectively avoids network expansion as the team size increases; moreover, new agents can be incorporated without modifying the network structures of existing agents, demonstrating strong scalability. Experimental results on multiagent cooperative tasks based on the Soft Actor-Critic (SAC) algorithm show that the proposed method achieves stable and efficient coordination under communication-limited environments. Furthermore, policies trained with collective influence modeling are deployed on a real robotic platform, where experimental results indicate significantly improved robustness and deployment feasibility, along with reduced dependence on communication infrastructure.