Reverse Flow Matching: A Unified Framework for Online Reinforcement Learning with Diffusion and Flow Policies
作者: Zeyang Li, Sunbochen Tang, Navid Azizan
分类: cs.LG, eess.SY
发布日期: 2026-01-13
💡 一句话要点
提出反向流匹配(RFM)框架,统一扩散和流策略的在线强化学习训练。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 扩散模型 流模型 在线学习 反向流匹配
📋 核心要点
- 在线强化学习中,扩散和流策略训练面临缺乏目标分布直接样本的挑战,现有方法如噪声期望和梯度期望缺乏统一理论框架。
- 论文提出反向流匹配(RFM)框架,将训练目标视为后验均值估计问题,并利用Langevin Stein算子减少重要性采样方差。
- RFM统一了噪声期望和梯度期望方法,并扩展到流策略,通过结合Q值和Q梯度信息,提升了训练效率和稳定性。
📝 摘要(中文)
扩散和流策略因其强大的表达能力在在线强化学习(RL)中越来越受欢迎,但如何高效地训练它们仍然是一个关键挑战。在线RL的一个根本困难是缺乏来自目标分布的直接样本;相反,目标是由Q函数定义的未归一化的玻尔兹曼分布。为了解决这个问题,针对扩散策略提出了两个看似不同的方法族:噪声期望族(利用噪声的加权平均作为训练目标)和梯度期望族(采用Q函数梯度的加权平均)。然而,这些目标在形式上如何关联,或者它们是否可以被综合成一个更一般的公式,仍然不清楚。在本文中,我们提出了一个统一的框架,即反向流匹配(RFM),它严格地解决了在没有直接目标样本的情况下训练扩散和流模型的问题。通过采用反向推断的视角,我们将训练目标定义为给定中间噪声样本的后验均值估计问题。至关重要的是,我们引入了Langevin Stein算子来构建零均值控制变量,从而推导出了一类通用的估计器,可以有效地减少重要性采样的方差。我们表明,现有的噪声期望和梯度期望方法是这个更广泛的类中的两个特定实例。这种统一的观点产生了两个关键的进步:它将针对玻尔兹曼分布的能力从扩散策略扩展到流策略,并能够有原则地结合Q值和Q梯度信息,从而推导出最优的、最小方差的估计器,从而提高训练效率和稳定性。我们实例化RFM以在在线RL中训练流策略,并证明与扩散策略基线相比,在连续控制基准上性能有所提高。
🔬 方法详解
问题定义:在线强化学习中,训练扩散模型或流模型策略时,由于无法直接从目标分布(由Q函数定义的玻尔兹曼分布)中采样,导致训练目标难以确定。现有的噪声期望和梯度期望方法虽然有效,但缺乏统一的理论基础,且各自存在局限性,例如方差较高,难以优化。
核心思路:论文的核心思路是将策略训练问题转化为一个后验均值估计问题。具体来说,给定一个中间噪声样本,目标是估计在给定该噪声样本的情况下,真实状态的后验分布的均值。通过这种反向推断的视角,可以将不同的训练目标统一起来,并利用统计学方法来优化估计过程。
技术框架:RFM框架主要包含以下几个阶段:1) 定义一个从数据空间到噪声空间的扩散过程(或流过程)。2) 在该过程中,给定一个中间噪声样本,定义一个反向过程,用于估计后验分布。3) 利用Langevin Stein算子构建零均值控制变量,以减少重要性采样的方差。4) 基于后验均值估计,设计损失函数,用于训练扩散模型或流模型。
关键创新:RFM的关键创新在于:1) 提出了一个统一的框架,可以同时处理扩散模型和流模型。2) 将策略训练问题转化为后验均值估计问题,从而可以使用统计学方法来优化训练过程。3) 利用Langevin Stein算子构建零均值控制变量,有效地减少了重要性采样的方差。4) 能够有原则地结合Q值和Q梯度信息,从而推导出最优的、最小方差的估计器。
关键设计:RFM的关键设计包括:1) 选择合适的扩散过程或流过程。2) 设计合适的Langevin Stein算子,以构建有效的控制变量。3) 设计合适的损失函数,以优化后验均值估计。4) 在训练过程中,需要平衡Q值和Q梯度信息的权重,以获得最佳的性能。
🖼️ 关键图片
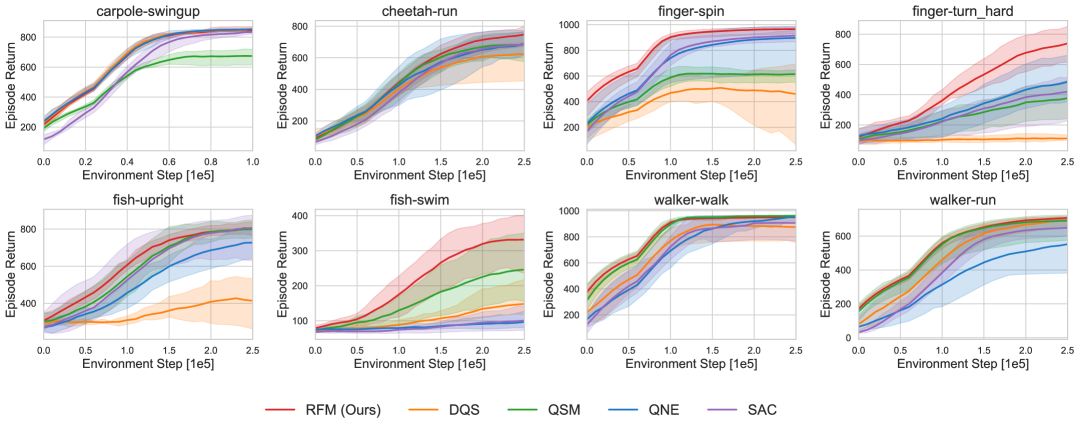
📊 实验亮点
实验结果表明,RFM在连续控制基准测试中,使用流策略训练时,性能优于现有的扩散策略基线。这证明了RFM框架的有效性,以及其在训练流策略方面的优势。
🎯 应用场景
该研究成果可广泛应用于机器人控制、自动驾驶、游戏AI等需要在线强化学习的领域。通过更高效、稳定地训练扩散和流策略,可以提升智能体在复杂环境中的决策能力,实现更智能化的控制。
📄 摘要(原文)
Diffusion and flow policies are gaining prominence in online reinforcement learning (RL) due to their expressive power, yet training them efficiently remains a critical challenge. A fundamental difficulty in online RL is the lack of direct samples from the target distribution; instead, the target is an unnormalized Boltzmann distribution defined by the Q-function. To address this, two seemingly distinct families of methods have been proposed for diffusion policies: a noise-expectation family, which utilizes a weighted average of noise as the training target, and a gradient-expectation family, which employs a weighted average of Q-function gradients. Yet, it remains unclear how these objectives relate formally or if they can be synthesized into a more general formulation. In this paper, we propose a unified framework, reverse flow matching (RFM), which rigorously addresses the problem of training diffusion and flow models without direct target samples. By adopting a reverse inferential perspective, we formulate the training target as a posterior mean estimation problem given an intermediate noisy sample. Crucially, we introduce Langevin Stein operators to construct zero-mean control variates, deriving a general class of estimators that effectively reduce importance sampling variance. We show that existing noise-expectation and gradient-expectation methods are two specific instances within this broader class. This unified view yields two key advancements: it extends the capability of targeting Boltzmann distributions from diffusion to flow policies, and enables the principled combination of Q-value and Q-gradient information to derive an optimal, minimum-variance estimator, thereby improving training efficiency and stability. We instantiate RFM to train a flow policy in online RL, and demonstrate improved performance on continuous-control benchmarks compared to diffusion policy baselines.