Reinforcement Learning for Micro-Level Claims Reserving
作者: Benjamin Avanzi, Ronald Richman, Bernard Wong, Mario Wüthrich, Yagebu Xie
分类: q-fin.RM, cs.LG, stat.ML
发布日期: 2026-01-12
💡 一句话要点
提出基于强化学习的微观索赔准备金方法,提升未决赔案负债预测精度与稳定性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 索赔准备金 马尔可夫决策过程 精算 Soft Actor-Critic
📋 核心要点
- 传统索赔准备金模型通常作为一次性预测器训练,仅从已结算的索赔中学习,忽略了未决赔案的信息。
- 论文提出一种基于强化学习的个体索赔准备金方法,通过智能体与环境交互,学习在赔案发展过程中逐步更新未决赔案负债。
- 实验表明,该方法在索赔级别的准确性和总体未决赔案负债性能方面表现出色,尤其是在不成熟的索赔部分。
📝 摘要(中文)
本文将个体索赔准备金问题建模为索赔级别的马尔可夫决策过程,其中智能体在赔案发展过程中连续更新未决赔案负债(OCL)的估计值,使用连续动作和奖励函数来平衡准确性和准备金修订的稳定性。该强化学习(RL)方法的一个关键优势在于,它可以从所有观察到的索赔轨迹中学习,包括在估值时仍未决的赔案,从而避免了仅在最终结果上训练的监督方法中固有的样本量减少和选择偏差。此外,本文还引入了精算使用所需的实用组件,包括新索赔的初始化、通过滚动结算方案进行时间一致性调整,以及用于减轻由大型索赔的稀有性驱动的投资组合层面低估的重要性加权机制。在CAS和SPLICE合成一般保险数据集上,所提出的Soft Actor-Critic实现提供了具有竞争力的索赔级别准确性和强大的总体OCL性能,特别是对于驱动大部分负债的不成熟索赔部分。
🔬 方法详解
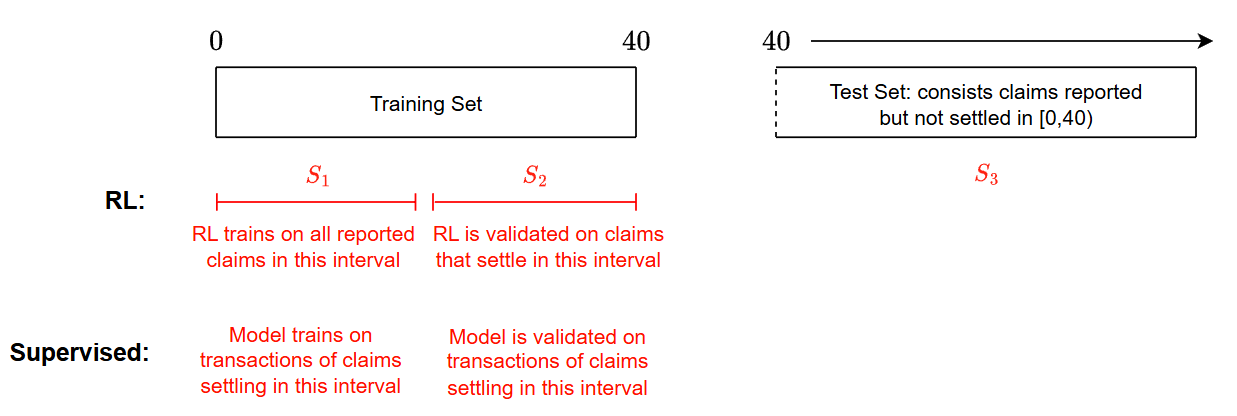
问题定义:传统索赔准备金模型主要面临两个痛点。一是大多数模型被训练为一次性预测器,忽略了赔案发展过程中的动态信息。二是这些模型通常只使用已结算的索赔数据进行训练,导致样本量减少,并可能引入选择偏差,因为未决赔案的信息被忽略。
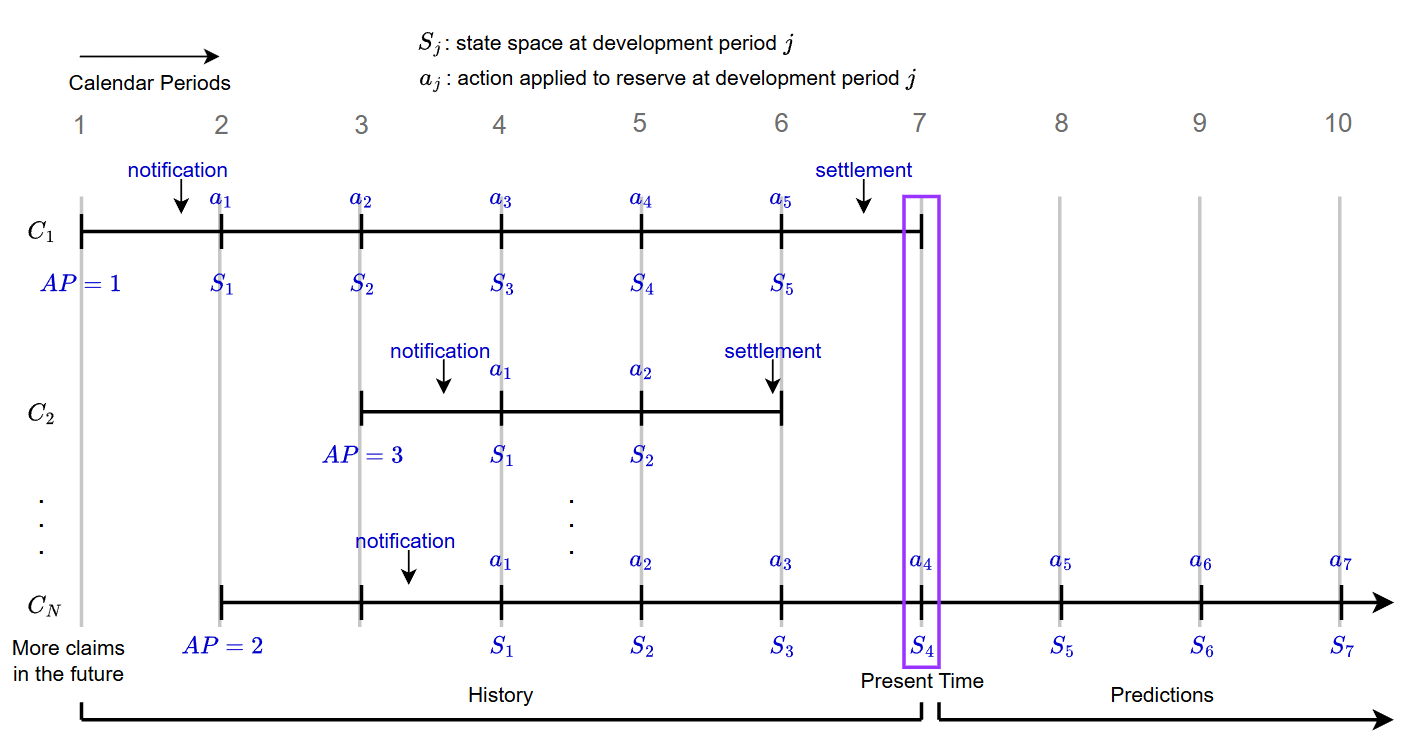
核心思路:论文的核心思路是将个体索赔准备金问题建模为一个马尔可夫决策过程(MDP)。智能体通过与环境(赔案发展过程)交互,学习如何逐步更新未决赔案负债(OCL)的估计值。这种方法允许智能体从所有观察到的索赔轨迹中学习,包括未决赔案,从而克服了传统方法的局限性。通过精心设计的奖励函数,可以平衡预测的准确性和准备金修订的稳定性。
技术框架:整体框架包含以下几个主要模块:1) 环境:模拟赔案的发展过程,提供状态信息(例如,已发生的赔付金额、索赔类型等)。2) 智能体:根据当前状态,选择一个连续动作(即对OCL的调整)。3) 奖励函数:根据智能体的动作和实际赔付情况,给予奖励或惩罚,引导智能体学习最优策略。4) Soft Actor-Critic (SAC):使用SAC算法训练智能体,SAC是一种off-policy的强化学习算法,能够有效地处理连续动作空间,并具有较好的探索能力。
关键创新:该论文的关键创新在于将强化学习应用于个体索赔准备金问题,并设计了一套完整的解决方案,包括状态表示、动作空间、奖励函数和训练策略。与传统的监督学习方法相比,该方法能够利用所有可用的索赔数据,并学习到赔案发展过程中的动态信息。此外,论文还针对精算应用的需求,引入了新索赔的初始化、时间一致性调整和重要性加权机制。
关键设计:1) 状态表示:状态包括已发生的赔付金额、索赔类型、索赔发生时间等信息。2) 动作空间:动作是连续的,表示对OCL的调整幅度。3) 奖励函数:奖励函数的设计旨在平衡预测的准确性和准备金修订的稳定性。例如,可以使用预测误差的负值作为奖励,同时对大幅度的准备金修订进行惩罚。4) 重要性加权:为了解决大型索赔的稀有性导致的投资组合层面低估问题,论文引入了重要性加权机制,对大型索赔的损失函数赋予更高的权重。
🖼️ 关键图片

📊 实验亮点
在CAS和SPLICE合成数据集上的实验结果表明,所提出的Soft Actor-Critic实现提供了具有竞争力的索赔级别准确性和强大的总体OCL性能。尤其是在不成熟的索赔部分,该方法的性能提升显著,这对于保险公司来说至关重要,因为不成熟的索赔通常驱动大部分负债。
🎯 应用场景
该研究成果可应用于保险公司的索赔准备金管理,帮助精算师更准确地估计未决赔案负债,优化资本配置,并提高财务报告的可靠性。此外,该方法还可以扩展到其他需要动态预测和决策的领域,例如风险管理、信用评估等。
📄 摘要(原文)
Outstanding claim liabilities are revised repeatedly as claims develop, yet most modern reserving models are trained as one-shot predictors and typically learn only from settled claims. We formulate individual claims reserving as a claim-level Markov decision process in which an agent sequentially updates outstanding claim liability (OCL) estimates over development, using continuous actions and a reward design that balances accuracy with stable reserve revisions. A key advantage of this reinforcement learning (RL) approach is that it can learn from all observed claim trajectories, including claims that remain open at valuation, thereby avoiding the reduced sample size and selection effects inherent in supervised methods trained on ultimate outcomes only. We also introduce practical components needed for actuarial use -- initialisation of new claims, temporally consistent tuning via a rolling-settlement scheme, and an importance-weighting mechanism to mitigate portfolio-level underestimation driven by the rarity of large claims. On CAS and SPLICE synthetic general insurance datasets, the proposed Soft Actor-Critic implementation delivers competitive claim-level accuracy and strong aggregate OCL performance, particularly for the immature claim segments that drive most of the liability.