d3LLM: Ultra-Fast Diffusion LLM using Pseudo-Trajectory Distillation
作者: Yu-Yang Qian, Junda Su, Lanxiang Hu, Peiyuan Zhang, Zhijie Deng, Peng Zhao, Hao Zhang
分类: cs.LG, cs.AI
发布日期: 2026-01-12
🔗 代码/项目: GITHUB
💡 一句话要点
提出d3LLM,通过伪轨迹蒸馏加速扩散语言模型,实现精度与并行性的平衡。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 扩散语言模型 并行解码 伪轨迹蒸馏 知识蒸馏 多块解码 KV-cache AUP指标 文本生成
📋 核心要点
- 扩散语言模型面临精度和并行性的权衡,现有方法往往只关注效率或性能,无法兼顾。
- d3LLM通过伪轨迹蒸馏在训练时提升模型早期解码的置信度,推理时采用多块解码和KV-cache刷新。
- 实验结果表明,d3LLM在精度损失不大的情况下,解码速度比现有扩散模型快10倍,比自回归模型快5倍。
📝 摘要(中文)
扩散语言模型(dLLM)提供了超越自回归(AR) LLM的能力,例如并行解码和随机顺序生成。然而,在实践中实现这些优势并非易事,因为dLLM本质上面临着精度-并行性的权衡。尽管人们对此越来越感兴趣,但现有方法通常只关注硬币的一面,要么针对效率,要么针对性能。为了解决这个限制,我们提出了d3LLM(伪蒸馏扩散大型语言模型),在精度和并行性之间取得了平衡:(i)在训练期间,我们引入伪轨迹蒸馏来教导模型哪些token可以在早期步骤中自信地解码,从而提高并行性;(ii)在推理期间,我们采用基于熵的多块解码和KV-cache刷新机制,以实现高并行性,同时保持精度。为了更好地评估dLLM,我们还引入了AUP(并行性下的准确率),这是一个联合衡量准确率和并行性的新指标。实验表明,我们的d3LLM比vanilla LLaDA/Dream快10倍,比AR模型快5倍,而精度没有明显下降。我们的代码可在https://github.com/hao-ai-lab/d3LLM获得。
🔬 方法详解
问题定义:扩散语言模型(dLLM)虽然具有并行解码和随机顺序生成等优势,但其精度和并行性之间存在固有的矛盾。现有方法要么侧重于提高效率,要么侧重于提升性能,无法同时优化这两个方面。因此,如何设计一种既能保持较高精度,又能充分利用并行计算能力的dLLM是一个关键问题。
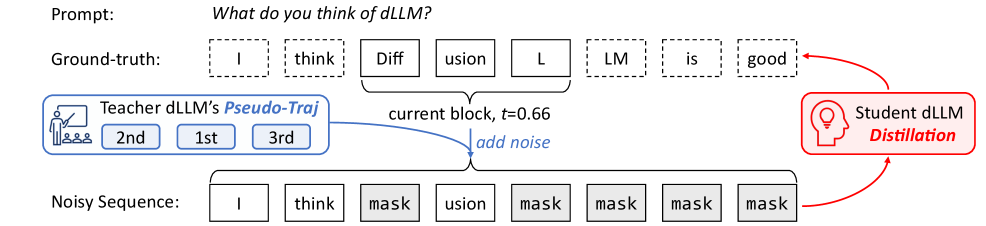
核心思路:d3LLM的核心思路是通过伪轨迹蒸馏来引导模型学习在早期解码步骤中预测哪些token是可靠的。通过这种方式,模型可以在推理时更早地确定部分token,从而增加并行解码的机会。同时,采用基于熵的多块解码和KV-cache刷新机制,进一步提升并行性和精度。
技术框架:d3LLM的整体框架包含训练和推理两个阶段。在训练阶段,使用伪轨迹蒸馏方法,利用教师模型的输出作为伪标签,指导学生模型学习。在推理阶段,首先使用基于熵的多块解码策略,将文本分成多个块并行解码。然后,使用KV-cache刷新机制,更新解码过程中使用的键值缓存,以提高解码的准确性。
关键创新:d3LLM的关键创新在于提出了伪轨迹蒸馏方法。与传统的蒸馏方法不同,伪轨迹蒸馏不仅关注最终的输出结果,还关注中间解码步骤的输出。通过学习教师模型在中间步骤的输出,学生模型可以更好地理解解码过程,从而提高并行解码的效率。此外,AUP指标的提出,为dLLM的评估提供了一个更全面的视角。
关键设计:在伪轨迹蒸馏中,损失函数的设计至关重要。论文可能采用了KL散度或交叉熵等损失函数,来衡量学生模型和教师模型在中间步骤输出的差异。在多块解码中,块大小的选择会影响并行度和精度,需要根据具体任务进行调整。KV-cache刷新机制的具体实现方式(例如,刷新频率、刷新策略)也会影响最终的性能。
🖼️ 关键图片


📊 实验亮点
实验结果表明,d3LLM在保证精度没有明显下降的情况下,实现了显著的加速。具体来说,d3LLM比vanilla LLaDA/Dream快10倍,比自回归模型快5倍。此外,论文还提出了AUP指标,为评估dLLM的性能提供了一个新的标准。
🎯 应用场景
d3LLM具有广泛的应用前景,例如可以应用于需要快速响应的对话系统、实时翻译、以及对生成速度有较高要求的文本生成任务。其并行解码的特性使其能够充分利用硬件资源,提高生成效率。未来,d3LLM有望在自然语言处理领域发挥更大的作用。
📄 摘要(原文)
Diffusion large language models (dLLMs) offer capabilities beyond those of autoregressive (AR) LLMs, such as parallel decoding and random-order generation. However, realizing these benefits in practice is non-trivial, as dLLMs inherently face an accuracy-parallelism trade-off. Despite increasing interest, existing methods typically focus on only one-side of the coin, targeting either efficiency or performance. To address this limitation, we propose d3LLM (Pseudo-Distilled Diffusion Large Language Model), striking a balance between accuracy and parallelism: (i) during training, we introduce pseudo-trajectory distillation to teach the model which tokens can be decoded confidently at early steps, thereby improving parallelism; (ii) during inference, we employ entropy-based multi-block decoding with a KV-cache refresh mechanism to achieve high parallelism while maintaining accuracy. To better evaluate dLLMs, we also introduce AUP (Accuracy Under Parallelism), a new metric that jointly measures accuracy and parallelism. Experiments demonstrate that our d3LLM achieves up to 10$\times$ speedup over vanilla LLaDA/Dream and 5$\times$ speedup over AR models without much accuracy drop. Our code is available at https://github.com/hao-ai-lab/d3LLM.