Stagewise Reinforcement Learning and the Geometry of the Regret Landscape
作者: Chris Elliott, Einar Urdshals, David Quarel, Matthew Farrugia-Roberts, Daniel Murfet
分类: cs.LG
发布日期: 2026-01-12
备注: 50 pages, 14 figures
💡 一句话要点
基于后悔函数几何的阶段性强化学习理论,揭示策略演化中的贝叶斯相变
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 奇异学习理论 贝叶斯相变 后悔函数 局部学习系数
📋 核心要点
- 现有深度强化学习缺乏对策略演化过程的理论理解,难以解释训练过程中策略的阶段性变化。
- 论文提出基于奇异学习理论的框架,利用后悔函数的几何性质,通过局部学习系数(LLC)来刻画策略演化。
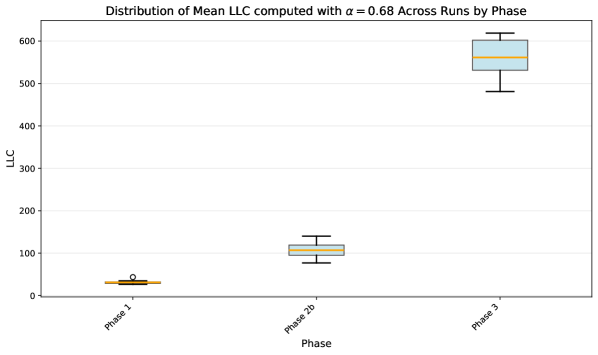
- 实验表明,LLC能够有效检测强化学习中的贝叶斯相变,即使在策略表现相似的状态下也能捕捉到算法的内在变化。
📝 摘要(中文)
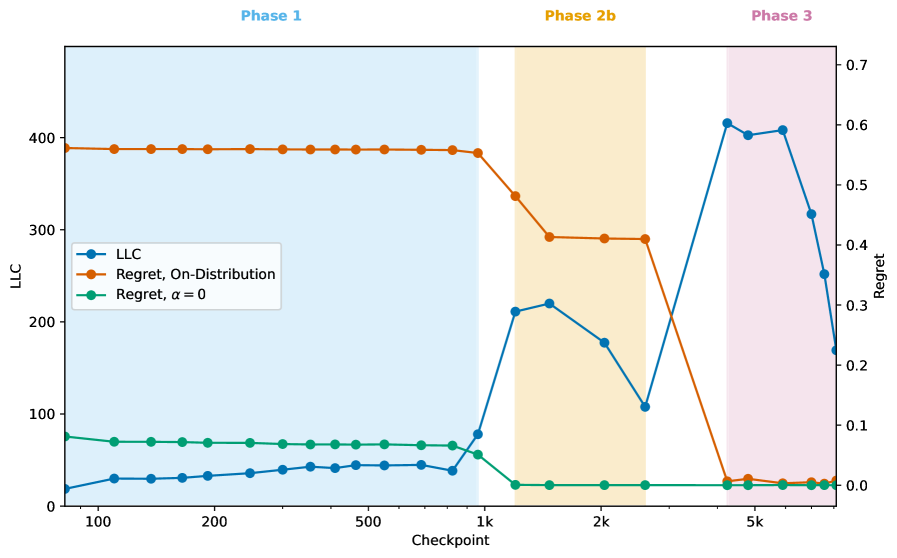
奇异学习理论将贝叶斯学习描述为精度和复杂度之间不断演变的权衡,随着样本量的增加,解决方案在性质上发生转变。本文将该理论扩展到深度强化学习,证明策略上的广义后验分布的集中程度由局部学习系数(LLC)控制,LLC是后悔函数几何的不变量。该理论预测,强化学习中的贝叶斯相变应从具有高后悔值的简单策略过渡到具有低后悔值的复杂策略。我们在一个网格世界环境中验证了这一预测,该环境表现出阶段性的策略发展:SGD训练中的相变表现为“相反的阶梯”,即后悔值急剧下降,而LLC增加。值得注意的是,即使在策略在后悔值方面看起来相同的状态子集上估计LLC,它也能检测到相变,这表明它捕获了底层算法的变化,而不仅仅是性能的变化。
🔬 方法详解
问题定义:论文旨在解决深度强化学习中策略演化过程缺乏理论指导的问题。现有方法难以解释训练过程中策略的阶段性变化,例如,策略从简单到复杂的演变,以及性能突然提升的现象。理解这些变化有助于更好地设计强化学习算法,并提高其稳定性和效率。
核心思路:论文的核心思路是将奇异学习理论应用于深度强化学习,利用后悔函数的几何性质来刻画策略的演化。具体来说,论文证明策略上的广义后验分布的集中程度由局部学习系数(LLC)控制,而LLC是后悔函数几何的不变量。通过分析LLC的变化,可以预测和解释强化学习中的贝叶斯相变。
技术框架:论文的技术框架主要包括以下几个部分:1) 定义强化学习问题,包括状态空间、动作空间、奖励函数等;2) 引入奇异学习理论,定义广义后验分布和局部学习系数(LLC);3) 证明LLC与后悔函数几何之间的关系,即LLC是后悔函数几何的不变量;4) 提出基于LLC的贝叶斯相变预测方法;5) 在网格世界环境中进行实验验证。
关键创新:论文最重要的技术创新点在于将奇异学习理论应用于深度强化学习,并证明了局部学习系数(LLC)是后悔函数几何的不变量。这一发现为理解和预测强化学习中的策略演化提供了新的视角和工具。与现有方法相比,该方法能够更深入地理解算法的内在变化,而不仅仅是关注性能指标。
关键设计:论文的关键设计包括:1) 使用广义后验分布来刻画策略的不确定性;2) 定义局部学习系数(LLC)作为衡量策略复杂度的指标;3) 设计网格世界环境,使其能够表现出阶段性的策略发展;4) 使用SGD算法进行策略训练,并监测LLC和后悔值的变化。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在网格世界环境中,SGD训练中的相变表现为“相反的阶梯”,即后悔值急剧下降,而LLC增加。更重要的是,即使在策略在后悔值方面看起来相同的状态子集上估计LLC,它也能检测到相变,这表明LLC捕获了底层算法的变化,而不仅仅是性能的变化。
🎯 应用场景
该研究成果可应用于各种强化学习任务,例如机器人控制、游戏AI、自动驾驶等。通过理解策略演化过程,可以设计更有效的强化学习算法,提高算法的稳定性和泛化能力。此外,该研究还可以帮助我们更好地理解人类学习的过程,并开发更智能的AI系统。
📄 摘要(原文)
Singular learning theory characterizes Bayesian learning as an evolving tradeoff between accuracy and complexity, with transitions between qualitatively different solutions as sample size increases. We extend this theory to deep reinforcement learning, proving that the concentration of the generalized posterior over policies is governed by the local learning coefficient (LLC), an invariant of the geometry of the regret function. This theory predicts that Bayesian phase transitions in reinforcement learning should proceed from simple policies with high regret to complex policies with low regret. We verify this prediction empirically in a gridworld environment exhibiting stagewise policy development: phase transitions over SGD training manifest as "opposing staircases" where regret decreases sharply while the LLC increases. Notably, the LLC detects phase transitions even when estimated on a subset of states where the policies appear identical in terms of regret, suggesting it captures changes in the underlying algorithm rather than just performance.