SCALPEL: Selective Capability Ablation via Low-rank Parameter Editing for Large Language Model Interpretability Analysis
作者: Zihao Fu, Xufeng Duan, Zhenguang G. Cai
分类: cs.LG, cs.AI, cs.CL
发布日期: 2026-01-12
💡 一句话要点
SCALPEL:通过低秩参数编辑实现大语言模型选择性能力消融的可解释性分析
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 可解释性 能力消融 低秩参数编辑 LoRA 参数空间 选择性干预
📋 核心要点
- 现有方法假设能力与特定模块对应,忽略了能力分布性和模块多功能性,导致分析粒度粗糙。
- SCALPEL将能力表示为低秩参数子空间,通过低秩参数编辑实现选择性能力消融,避免影响其他能力。
- 实验表明SCALPEL能有效移除目标能力,同时保留通用能力,揭示了LLM中能力编码的低秩结构。
📝 摘要(中文)
大型语言模型在各个领域表现出色,但由于对其内部机制的理解不完整,限制了其在医疗保健、法律系统和自主决策中的部署。随着这些模型集成到高风险系统中,理解它们如何编码能力已成为可解释性研究的基础。传统方法通过梯度归因或激活分析来识别重要模块,假设特定能力映射到特定组件。然而,这过度简化了神经计算:模块可能同时贡献于多种能力,而单一能力可能分布在多个模块中。这些粗粒度分析无法捕捉细粒度的分布式能力编码。我们提出了SCALPEL(通过低秩参数编辑实现大语言模型选择性能力消融),该框架将能力表示为低秩参数子空间,而不是离散模块。我们的关键见解是,能力可以通过分布在层和模块中的低秩修改来表征,从而实现精确的能力移除,而不会影响其他能力。通过训练LoRA适配器来减少区分正确答案和错误答案的能力,同时保持通用语言建模质量,SCALPEL识别出负责特定能力的低秩表示,同时保持与其他能力的分离。来自BLiMP的跨多种能力和语言任务的实验表明,SCALPEL成功地移除了目标能力,同时保留了通用能力,从而提供了对参数空间中能力分布的细粒度见解。结果表明,能力表现出低秩结构,并且可以通过有针对性的参数空间干预来选择性地消融,从而提供对LLM中能力编码的细致理解。
🔬 方法详解
问题定义:现有的大语言模型可解释性分析方法,如梯度归因和激活分析,通常假设模型的能力与特定的模块或神经元直接对应。然而,这种假设过于简化了神经网络的复杂性,忽略了能力可能分布在多个模块中,而一个模块也可能参与多种能力的编码。因此,现有的方法无法进行细粒度的能力分析和消融,难以准确理解模型内部的能力表示。
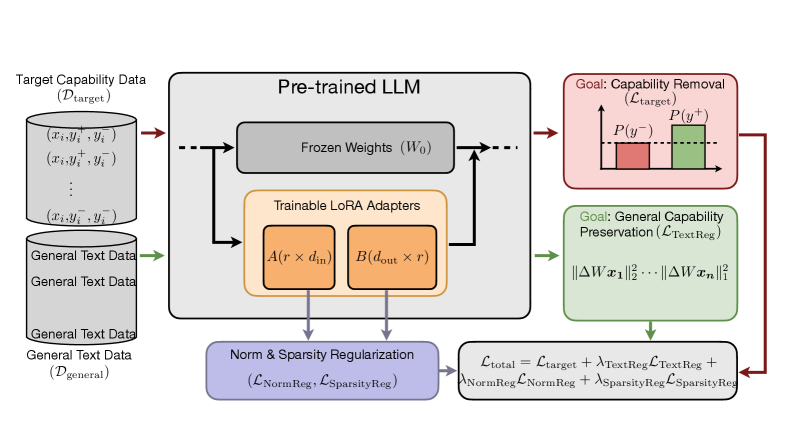
核心思路:SCALPEL的核心思路是将模型的能力表示为参数空间中的低秩子空间。该方法认为,一个特定的能力可以通过对模型参数进行低秩的修改来实现选择性的消融,而不会对模型的其他能力产生显著影响。通过找到并修改这些低秩子空间,可以实现对特定能力的精确控制和分析。
技术框架:SCALPEL框架主要包含以下几个步骤:1) 能力定义:明确需要分析和消融的目标能力。2) LoRA训练:使用LoRA(Low-Rank Adaptation)技术,训练一个LoRA适配器,其目标是降低模型区分正确答案和错误答案的能力,同时保持模型的通用语言建模能力。这个过程旨在找到与目标能力相关的低秩参数子空间。3) 参数编辑:将训练好的LoRA适配器的参数应用到原始模型中,从而实现对目标能力的消融。4) 能力评估:评估消融前后模型在目标能力和通用能力上的表现,验证消融的有效性和选择性。
关键创新:SCALPEL的关键创新在于将能力表示为低秩参数子空间,并利用LoRA技术进行选择性的参数编辑。与传统的模块消融方法相比,SCALPEL能够实现更细粒度的能力控制,避免了对其他能力的副作用。此外,SCALPEL还提供了一种新的视角来理解大语言模型内部的能力表示,即能力可能以低秩的形式分布在整个参数空间中。
关键设计:SCALPEL的关键设计包括:1) LoRA适配器的目标函数:目标函数旨在降低模型区分正确答案和错误答案的能力,同时使用语言建模损失来保持通用能力。2) 低秩分解的秩的选择:秩的大小决定了参数修改的范围和精度,需要根据具体的能力和模型进行调整。3) 消融后的能力评估指标:需要选择合适的指标来评估目标能力和通用能力的变化,以验证消融的有效性和选择性。
🖼️ 关键图片

📊 实验亮点
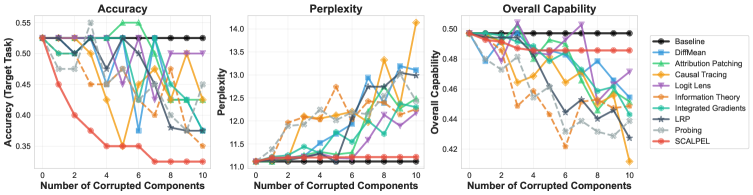
实验结果表明,SCALPEL能够成功地移除目标能力,同时保持模型的通用语言建模能力。在BLiMP数据集上的实验表明,SCALPEL在消融特定语言能力的同时,对其他语言能力的影响较小,验证了其选择性和有效性。该研究还揭示了不同能力在模型参数空间中的分布情况,为理解大语言模型的内部机制提供了新的见解。
🎯 应用场景
SCALPEL可用于评估和改进大型语言模型在安全关键领域的可靠性,例如医疗诊断和法律咨询。通过选择性地消除模型中的偏差或有害能力,可以提高模型的可信度和安全性。此外,该方法还可以用于理解不同能力在模型中的分布和相互作用,从而指导模型的设计和优化。
📄 摘要(原文)
Large language models excel across diverse domains, yet their deployment in healthcare, legal systems, and autonomous decision-making remains limited by incomplete understanding of their internal mechanisms. As these models integrate into high-stakes systems, understanding how they encode capabilities has become fundamental to interpretability research. Traditional approaches identify important modules through gradient attribution or activation analysis, assuming specific capabilities map to specific components. However, this oversimplifies neural computation: modules may contribute to multiple capabilities simultaneously, while single capabilities may distribute across multiple modules. These coarse-grained analyses fail to capture fine-grained, distributed capability encoding. We present SCALPEL (Selective Capability Ablation via Low-rank Parameter Editing for Large language models), a framework representing capabilities as low-rank parameter subspaces rather than discrete modules. Our key insight is that capabilities can be characterized by low-rank modifications distributed across layers and modules, enabling precise capability removal without affecting others. By training LoRA adapters to reduce distinguishing correct from incorrect answers while preserving general language modeling quality, SCALPEL identifies low-rank representations responsible for particular capabilities while remaining disentangled from others. Experiments across diverse capability and linguistic tasks from BLiMP demonstrate that SCALPEL successfully removes target capabilities while preserving general capabilities, providing fine-grained insights into capability distribution across parameter space. Results reveal that capabilities exhibit low-rank structure and can be selectively ablated through targeted parameter-space interventions, offering nuanced understanding of capability encoding in LLMs.