On the Non-decoupling of Supervised Fine-tuning and Reinforcement Learning in Post-training
作者: Xueyan Niu, Bo Bai, Wei Han, Weixi Zhang
分类: cs.LG, cs.AI, cs.IT
发布日期: 2026-01-12
💡 一句话要点
证明了后训练中监督微调与强化学习无法解耦,避免性能损失
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 后训练 监督微调 强化学习 解耦 理论分析 Qwen3 目标优化
📋 核心要点
- 现有方法在大型语言模型后训练中交替使用SFT和RL,但缺乏二者是否可以解耦的理论依据。
- 论文从理论上证明了SFT和RL在后训练中无法解耦,无论先后顺序都会导致性能下降。
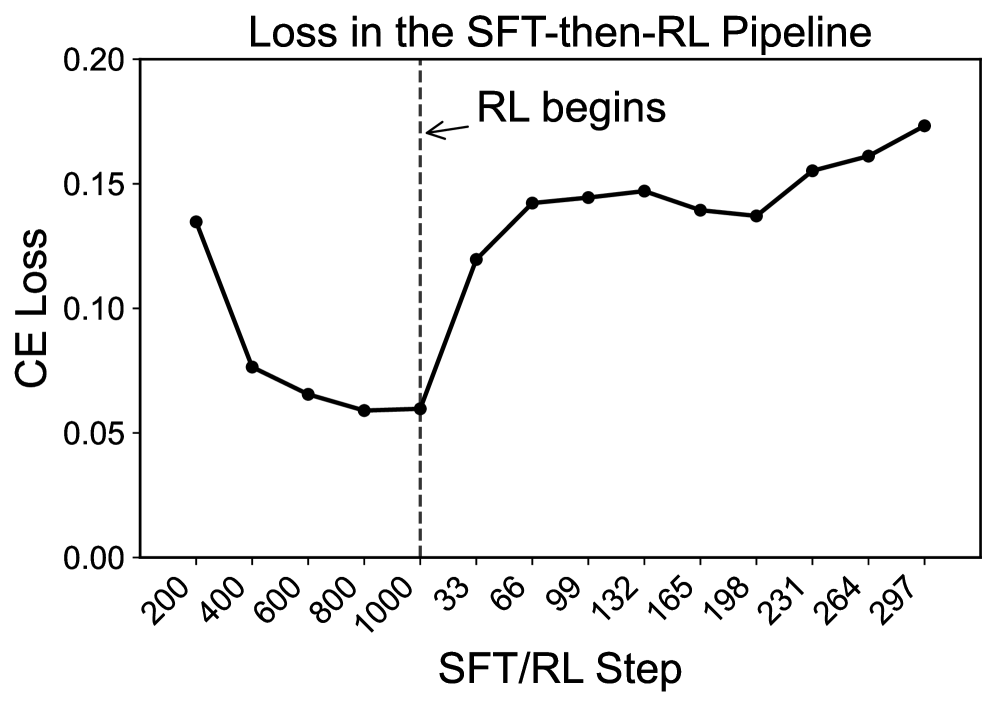
- 在Qwen3-0.6B上的实验验证了理论预测,表明解耦SFT和RL会导致性能损失。
📝 摘要(中文)
大型语言模型的后训练通常交替使用监督微调(SFT)和强化学习(RL)。这两种方法具有不同的目标:SFT最小化模型输出与专家响应之间的交叉熵损失,而RL最大化源于人类偏好或基于规则的验证器的奖励信号。现代推理模型已广泛采用交替进行SFT和RL训练的做法。然而,目前尚无关于它们是否可以解耦的理论解释。本文证明了按任何顺序解耦都是不可能的:(1)SFT-then-RL耦合:在SFT最优性下,RL会增加SFT损失;(2)RL-then-SFT耦合:SFT会降低RL获得的奖励。在Qwen3-0.6B上的实验证实了预测的性能下降,验证了SFT和RL不能在后训练中分离,否则会损失先前的性能。
🔬 方法详解
问题定义:论文旨在解决大型语言模型后训练中,监督微调(SFT)和强化学习(RL)是否可以解耦的问题。现有方法通常交替使用SFT和RL,但缺乏理论依据,无法确定这种耦合方式是否必要,以及是否存在更优的训练策略。如果可以解耦,则可以独立优化SFT和RL,从而简化训练流程并提高效率。
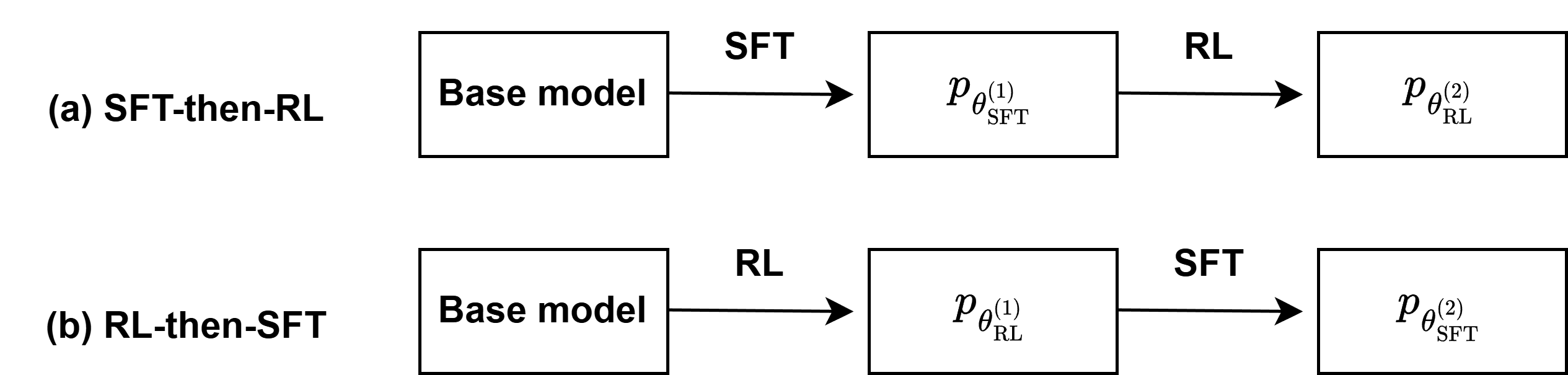
核心思路:论文的核心思路是通过理论分析证明SFT和RL在后训练中是相互影响的,无法解耦。具体来说,论文证明了两种情况:一是先进行SFT再进行RL,RL会增加SFT的损失;二是先进行RL再进行SFT,SFT会降低RL获得的奖励。这表明SFT和RL的目标存在冲突,需要耦合训练才能达到最佳性能。
技术框架:论文主要采用理论分析的方法,没有提出新的模型架构或训练算法。其技术框架可以概括为:首先,对SFT和RL的目标函数进行数学建模;然后,通过优化理论和梯度分析,证明SFT和RL之间的相互影响;最后,通过实验验证理论分析的结论。
关键创新:论文最重要的技术创新点在于从理论上证明了SFT和RL在后训练中无法解耦。这一结论挑战了现有方法中交替使用SFT和RL的实践,并为未来的研究提供了新的方向。例如,可以探索如何更好地耦合SFT和RL,以提高模型的性能。
关键设计:论文的关键设计在于对SFT和RL的目标函数进行了合理的建模,并利用优化理论和梯度分析工具,推导出了SFT和RL之间的相互影响关系。此外,论文还设计了实验来验证理论分析的结论,实验结果与理论预测相符,进一步增强了论文的可信度。
🖼️ 关键图片
📊 实验亮点
论文在Qwen3-0.6B上进行了实验,验证了理论分析的结论。实验结果表明,无论是先进行SFT再进行RL,还是先进行RL再进行SFT,都会导致性能下降。这证实了SFT和RL在后训练中无法解耦,需要耦合训练才能达到最佳性能。具体的性能下降幅度在论文中进行了详细的量化分析。
🎯 应用场景
该研究成果对大型语言模型的后训练具有指导意义。它表明,在进行SFT和RL时,需要考虑二者之间的相互影响,不能简单地将它们解耦。未来的研究可以探索更有效的耦合SFT和RL的方法,以提高模型的性能和效率。此外,该研究也为其他机器学习任务中的多目标优化问题提供了借鉴。
📄 摘要(原文)
Post-training of large language models routinely interleaves supervised fine-tuning (SFT) with reinforcement learning (RL). These two methods have different objectives: SFT minimizes the cross-entropy loss between model outputs and expert responses, while RL maximizes reward signals derived from human preferences or rule-based verifiers. Modern reasoning models have widely adopted the practice of alternating SFT and RL training. However, there is no theoretical account of whether they can be decoupled. We prove that decoupling is impossible in either order: (1) SFT-then-RL coupling: RL increases SFT loss under SFT optimality and (2) RL-then-SFT coupling: SFT lowers the reward achieved by RL. Experiments on Qwen3-0.6B confirm the predicted degradation, verifying that SFT and RL cannot be separated without loss of prior performance in the post-training