Segmental Advantage Estimation: Enhancing PPO for Long-Context LLM Training
作者: Xue Gong, Qi Yi, Ziyuan Nan, Guanhua Huang, Kejiao Li, Yuhao Jiang, Ruibin Xiong, Zenan Xu, Jiaming Guo, Shaohui Peng, Bo Zhou
分类: cs.LG, cs.AI
发布日期: 2026-01-12
💡 一句话要点
提出分段优势估计(SAE),提升PPO在长文本LLM稀疏奖励训练中的性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大型语言模型 近端策略优化 优势估计 稀疏奖励
📋 核心要点
- 在稀疏奖励的RLVR场景下,PPO的优势估计由于中间值预测不准确而产生偏差,影响训练效果。
- SAE通过将序列分割成信息丰富的子段,并仅在段转换处计算优势估计,从而减少偏差。
- 实验证明,SAE在最终得分、训练稳定性和样本效率方面均优于传统方法,且具有良好的泛化性。
📝 摘要(中文)
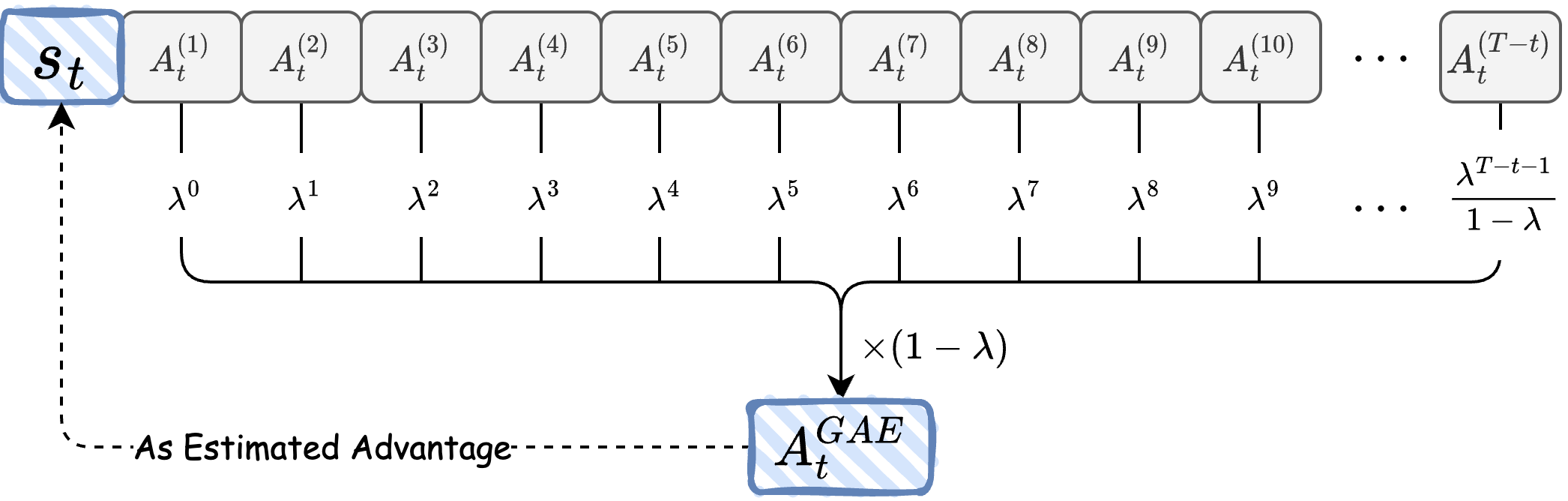
为了提升大型语言模型(LLM)在推理任务上的训练效果,研究人员越来越多地采用基于可验证奖励的强化学习(RLVR)。近端策略优化(PPO)为稳定的策略更新提供了一个原则性框架。然而,在稀疏奖励的RLVR机制中,PPO的实际应用受到不可靠的优势估计的阻碍。这是因为RLVR中的稀疏奖励导致不准确的中间值预测,进而通过广义优势估计(GAE)在每个token上聚合时引入显著偏差。为了解决这个问题,我们提出了分段优势估计(SAE),它减轻了GAE在RLVR中可能产生的偏差。我们的关键见解是,在每个token上聚合n步优势(如GAE中那样)是不必要的,并且常常引入过度的偏差,因为单个token携带的信息极少。相反,SAE首先使用低概率token作为启发式边界,将生成的序列划分为连贯的子段。然后,它仅从这些信息丰富的段转换中选择性地计算方差降低的优势估计,从而有效地过滤掉来自中间token的噪声。实验表明,SAE实现了卓越的性能,在最终得分、训练稳定性和样本效率方面都有显著提高。这些增益在多种模型尺寸上都表现出一致性,并且相关性分析证实了我们提出的优势估计器与近似的ground-truth优势实现了更高的相关性,证明了其卓越的性能。
🔬 方法详解
问题定义:论文旨在解决在稀疏奖励的强化学习场景下,使用PPO训练大型语言模型时,由于广义优势估计(GAE)对每个token进行优势估计而引入的偏差问题。现有方法的问题在于,在稀疏奖励环境下,中间token携带的信息量少,GAE对这些token的优势估计会引入噪声,导致训练不稳定和效果下降。
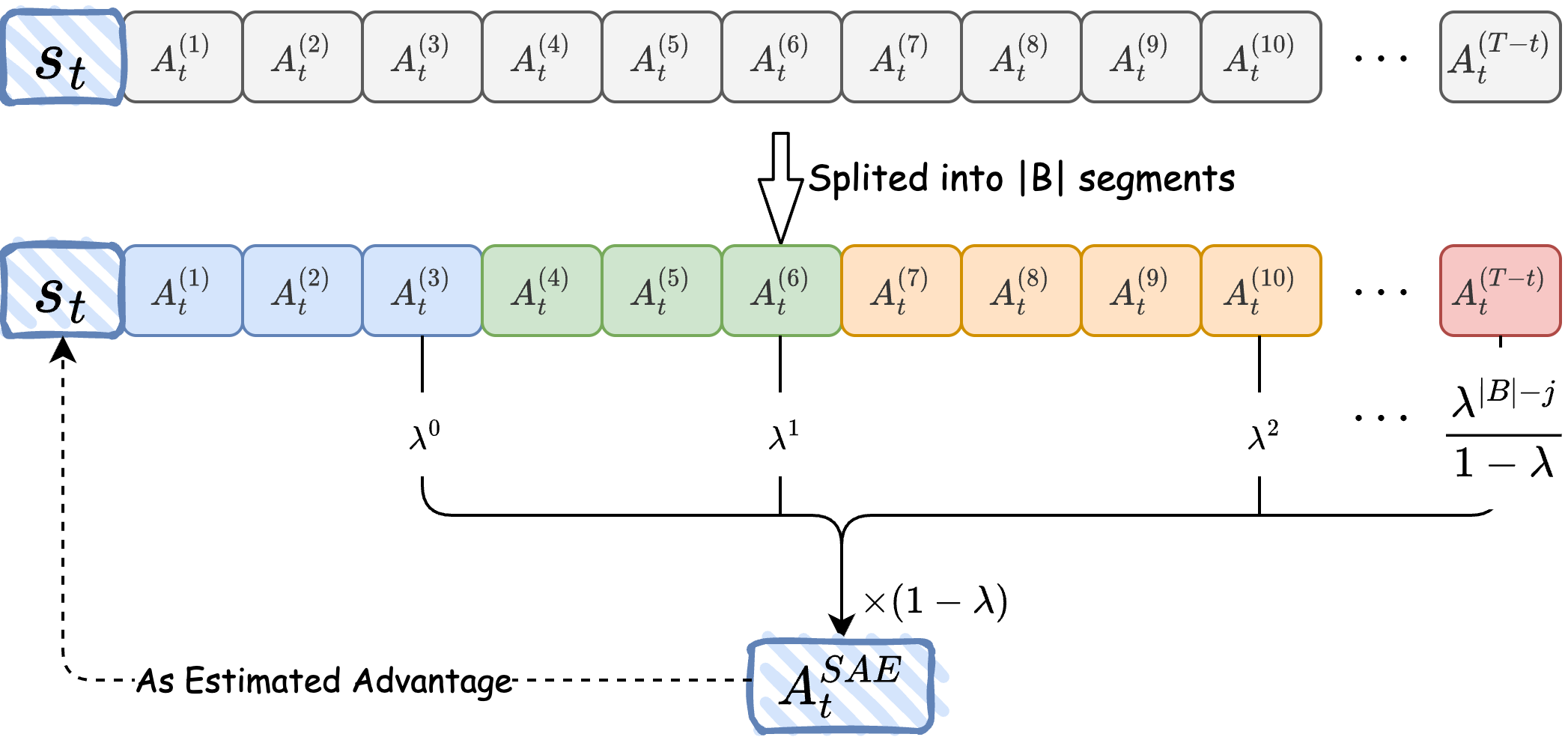
核心思路:论文的核心思路是,并非每个token都对优势估计有贡献,因此应该选择性地计算优势。具体来说,将序列分割成多个子段,只在子段的边界处进行优势估计,从而过滤掉中间token的噪声。这样可以减少优势估计的方差,提高训练的稳定性和效率。
技术框架:SAE的技术框架主要包含以下几个步骤:1) 使用低概率token作为启发式边界,将生成的序列分割成多个连贯的子段。2) 对于每个子段,计算其起始和结束位置。3) 仅在子段的起始和结束位置计算优势估计,而不是像GAE那样在每个token都计算。4) 使用计算得到的优势估计来更新策略。
关键创新:SAE的关键创新在于提出了分段优势估计的思想,即只在信息丰富的子段边界处进行优势估计,而不是在每个token都进行估计。这与传统的GAE方法有本质区别,GAE假设每个token都对优势估计有贡献,而SAE则认为只有部分token是重要的。
关键设计:SAE的关键设计包括:1) 如何选择合适的低概率token作为分割边界。论文中使用了启发式方法,选择概率低于某个阈值的token作为边界。2) 如何确定子段的长度。子段过短会导致计算量增加,子段过长则可能包含过多的噪声。3) 如何计算子段边界处的优势估计。可以使用标准的优势估计方法,如GAE或TD(λ)。
🖼️ 关键图片

📊 实验亮点
实验结果表明,SAE在多个模型尺寸上均取得了显著的性能提升,包括最终得分、训练稳定性和样本效率。相关性分析表明,SAE与近似的ground-truth优势具有更高的相关性,验证了其优势估计的准确性。具体性能数据未知,但论文强调了SAE在多个指标上的一致性提升。
🎯 应用场景
SAE可应用于各种需要使用强化学习训练大型语言模型的场景,尤其是在奖励稀疏的任务中,例如代码生成、复杂推理和对话生成等。该方法能够提高训练的稳定性和效率,从而降低训练成本,并提升模型的性能。
📄 摘要(原文)
Training Large Language Models (LLMs) for reasoning tasks is increasingly driven by Reinforcement Learning with Verifiable Rewards (RLVR), where Proximal Policy Optimization (PPO) provides a principled framework for stable policy updates. However, the practical application of PPO is hindered by unreliable advantage estimation in the sparse-reward RLVR regime. This issue arises because the sparse rewards in RLVR lead to inaccurate intermediate value predictions, which in turn introduce significant bias when aggregated at every token by Generalized Advantage Estimation (GAE). To address this, we introduce Segmental Advantage Estimation (SAE), which mitigates the bias that GAE can incur in RLVR. Our key insight is that aggregating $n$-step advantages at every token(as in GAE) is unnecessary and often introduces excessive bias, since individual tokens carry minimal information. Instead, SAE first partitions the generated sequence into coherent sub-segments using low-probability tokens as heuristic boundaries. It then selectively computes variance-reduced advantage estimates only from these information-rich segment transitions, effectively filtering out noise from intermediate tokens. Our experiments demonstrate that SAE achieves superior performance, with marked improvements in final scores, training stability, and sample efficiency. These gains are shown to be consistent across multiple model sizes, and a correlation analysis confirms that our proposed advantage estimator achieves a higher correlation with an approximate ground-truth advantage, justifying its superior performance.