Safeguarding LLM Fine-tuning via Push-Pull Distributional Alignment
作者: Haozhong Wang, Zhuo Li, Yibo Yang, He Zhao, Hongyuan Zha, Dandan Guo
分类: cs.LG, cs.AI
发布日期: 2026-01-12
💡 一句话要点
提出基于最优传输的SOT框架,提升LLM微调过程中的安全性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 安全微调 最优传输 分布对齐 安全对齐 权重学习 对抗样本防御
📋 核心要点
- 现有LLM微调安全防御方法依赖启发式实例评估,忽略数据分布的全局几何结构,无法有效排除有害模式。
- 论文提出Safety Optimal Transport (SOT)框架,将安全微调转化为分布对齐问题,利用最优传输理论。
- 实验证明SOT能显著提升模型安全性,同时保持下游任务性能,实现更好的安全性和实用性平衡。
📝 摘要(中文)
大型语言模型(LLM)固有的安全对齐在微调过程中容易受到侵蚀,即使使用看似无害的数据集也是如此。现有的防御方法试图通过数据选择来缓解这个问题,但它们通常依赖于启发式的、实例级别的评估,忽略了数据分布的全局几何结构,并且未能明确地排斥有害模式。为了解决这个问题,我们引入了安全最优传输(SOT),这是一个新颖的框架,它将安全微调从实例级别的过滤挑战重新定义为基于最优传输(OT)的分布级别对齐任务。其核心是一种双参考“推-拉”权重学习机制:SOT通过主动将下游分布拉向可信的安全锚点,同时将其推离一般的有害参考,来优化样本重要性。这建立了一个强大的几何安全边界,有效地净化了训练数据。在不同的模型系列和领域中进行的大量实验表明,SOT显著提高了模型的安全性,同时保持了具有竞争力的下游性能,与基线相比,实现了卓越的安全-效用权衡。
🔬 方法详解
问题定义:论文旨在解决LLM在微调过程中安全性下降的问题。现有方法主要集中在实例级别的过滤,缺乏对数据分布全局几何结构的考虑,容易受到对抗样本的攻击,并且无法有效地识别和排除潜在的有害模式。因此,如何设计一种能够从分布层面保证LLM微调安全性的方法是本文要解决的核心问题。
核心思路:论文的核心思路是将安全微调问题转化为一个分布对齐问题,通过最优传输理论,将微调后的模型分布与一个安全分布对齐,同时远离一个有害分布。这种“推-拉”机制能够有效地建立一个几何安全边界,从而净化训练数据,提高模型的安全性。
技术框架:SOT框架主要包含以下几个关键模块:1) 安全锚点(Safe Anchor):代表一个可信的安全分布,用于引导微调过程。2) 有害参考(Harmful Reference):代表一个有害分布,用于避免模型学习到有害模式。3) 最优传输模块:利用最优传输理论,计算微调后的模型分布与安全锚点和有害参考之间的距离,并根据这些距离调整样本的权重。4) 权重学习模块:根据最优传输模块的输出,学习每个样本的重要性权重,用于指导微调过程。
关键创新:SOT的关键创新在于将安全微调问题从实例级别提升到分布级别,并利用最优传输理论来建立一个几何安全边界。与现有方法相比,SOT能够更好地捕捉数据分布的全局信息,从而更有效地识别和排除有害模式。此外,SOT的“推-拉”机制能够同时考虑安全和有害两个方面,从而更加鲁棒。
关键设计:SOT的关键设计包括:1) 安全锚点的选择:安全锚点可以是一个预训练的、经过安全对齐的模型,或者是一个人工构建的安全数据集。2) 有害参考的选择:有害参考可以是一个包含有害样本的数据集,或者是一个对抗攻击生成的样本集。3) 最优传输距离的计算:论文采用了Sinkhorn算法来计算最优传输距离,该算法具有高效性和可扩展性。4) 权重学习策略:论文设计了一种基于最优传输距离的权重学习策略,使得模型能够更加关注安全样本,同时忽略有害样本。
🖼️ 关键图片


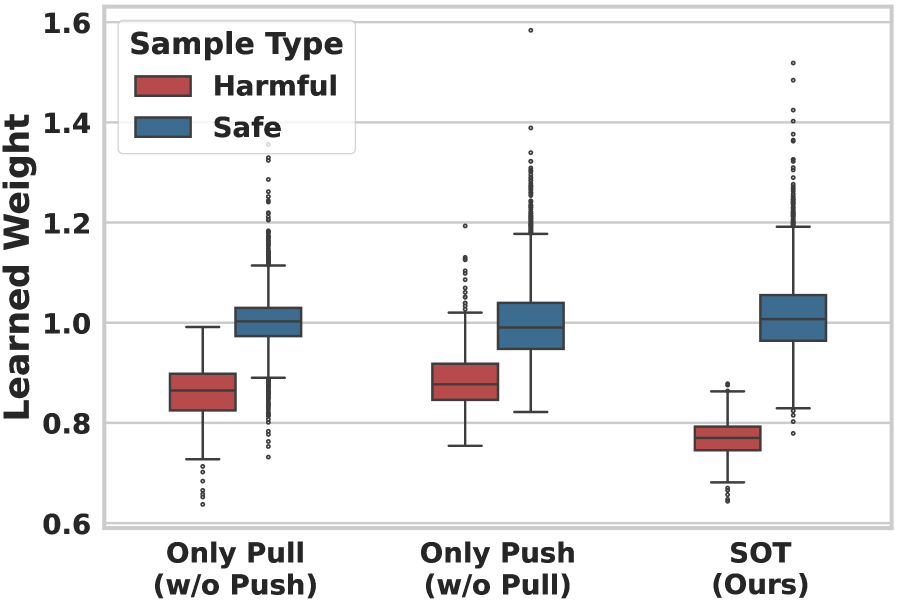
📊 实验亮点
实验结果表明,SOT框架在多个数据集和模型上都取得了显著的性能提升。例如,在某些安全基准测试中,SOT能够将模型的安全性提高10%以上,同时保持下游任务的性能与基线方法相当甚至更好。与现有的数据过滤方法相比,SOT在安全性和实用性之间取得了更好的平衡。
🎯 应用场景
该研究成果可应用于各种需要安全保障的LLM微调场景,例如:金融、医疗、法律等领域。通过SOT框架,可以有效防止模型在微调过程中学习到有害信息,从而提高模型的可靠性和安全性。此外,该方法还可以用于构建更加安全可信的AI系统,促进人工智能技术的健康发展。
📄 摘要(原文)
The inherent safety alignment of Large Language Models (LLMs) is prone to erosion during fine-tuning, even when using seemingly innocuous datasets. While existing defenses attempt to mitigate this via data selection, they typically rely on heuristic, instance-level assessments that neglect the global geometry of the data distribution and fail to explicitly repel harmful patterns. To address this, we introduce Safety Optimal Transport (SOT), a novel framework that reframes safe fine-tuning from an instance-level filtering challenge to a distribution-level alignment task grounded in Optimal Transport (OT). At its core is a dual-reference ``push-pull'' weight-learning mechanism: SOT optimizes sample importance by actively pulling the downstream distribution towards a trusted safe anchor while simultaneously pushing it away from a general harmful reference. This establishes a robust geometric safety boundary that effectively purifies the training data. Extensive experiments across diverse model families and domains demonstrate that SOT significantly enhances model safety while maintaining competitive downstream performance, achieving a superior safety-utility trade-off compared to baselines.