Beyond Variance: Knowledge-Aware LLM Compression via Fisher-Aligned Subspace Diagnostics
作者: Ibne Farabi Shihab, Sanjeda Akter, Anuj Sharma
分类: cs.LG, cs.AI
发布日期: 2026-01-12
💡 一句话要点
提出FASC:通过Fisher对齐子空间诊断实现知识感知的LLM压缩
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型压缩 知识感知 Fisher信息矩阵 子空间选择 梯度敏感性 模型部署 依赖违反分数
📋 核心要点
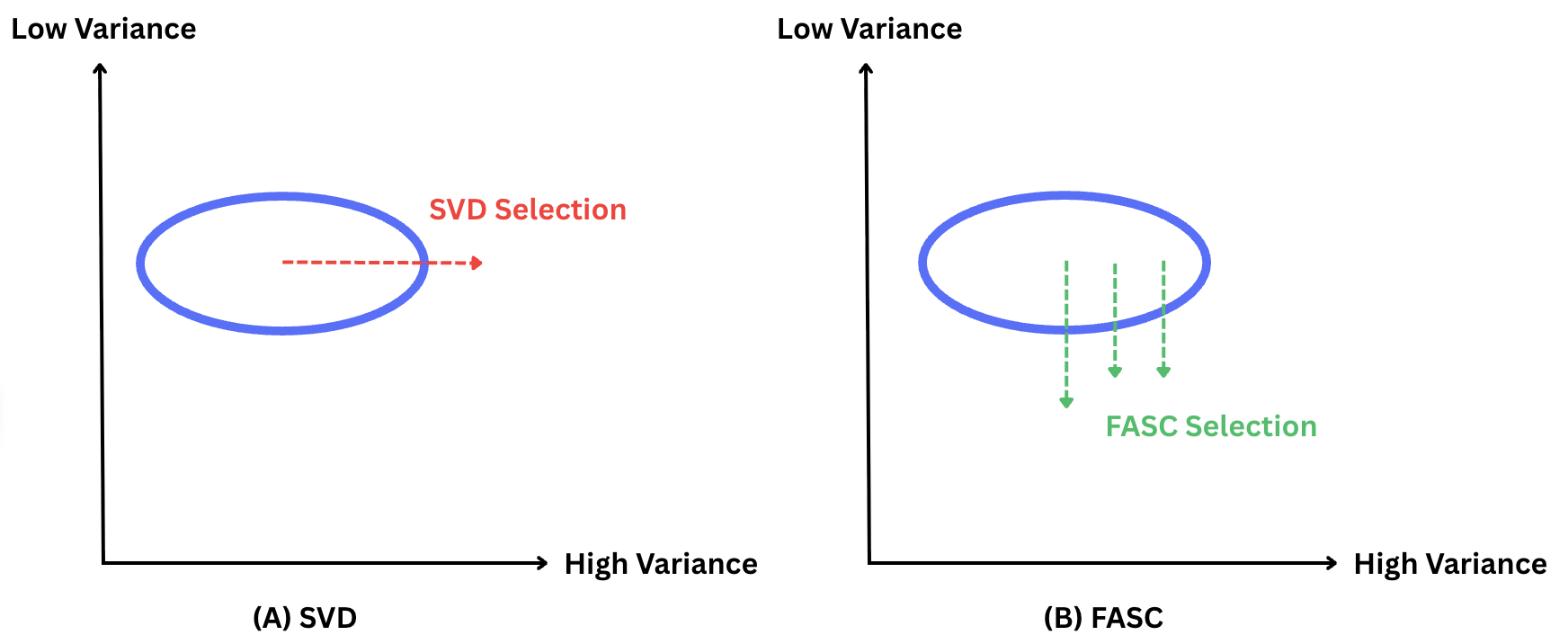
- 现有LLM压缩方法(如SVD)忽略了维度对事实知识的影响,导致压缩后知识保留不佳。
- FASC通过建模激活-梯度耦合,利用Fisher信息矩阵识别对事实知识至关重要的维度。
- 实验表明,FASC在知识密集型任务上显著优于传统方法,提升了压缩模型的知识保留能力。
📝 摘要(中文)
后训练激活压缩对于在资源受限的硬件上部署大型语言模型(LLM)至关重要。然而,诸如奇异值分解(SVD)之类的标准方法是梯度盲的:它们保留高方差维度,而忽略了它们对事实知识保留的影响。我们引入了Fisher对齐子空间压缩(FASC),这是一个知识感知的压缩框架,它通过直接建模激活-梯度耦合来选择子空间,从而最小化损失函数的二阶替代。FASC利用Fisher信息矩阵来识别对事实知识至关重要的维度,这些维度通常位于低方差但高梯度敏感性的子空间中。我们提出了依赖违反分数( {ho})作为一种通用诊断指标,用于量化激活-梯度耦合,揭示事实知识在Transformer架构中的存储位置。在Mistral-7B和Llama-3-8B上的大量实验表明,与基于方差的方法相比,FASC在50%的秩缩减下,在知识密集型基准(MMLU,LAMA)上保留了6-8%的准确率,有效地使7B模型能够匹配13B未压缩模型的事实召回率。我们的分析表明, {ho}是存储知识的基本信号,只有当模型在训练期间内化事实关联时,才会出现高- {ho}层。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在资源受限设备上部署的问题,具体而言,是如何在压缩模型大小的同时,尽可能地保留模型中存储的事实知识。现有方法,如奇异值分解(SVD),主要关注激活值的方差,倾向于保留高方差的维度,而忽略了这些维度对模型知识表达的重要性,导致压缩后模型在知识密集型任务上的性能显著下降。
核心思路:论文的核心思路是,模型的知识并非均匀分布在所有激活维度上,而是集中在对梯度变化敏感的特定子空间中。因此,压缩时应该优先保留这些对知识表达至关重要的维度,即使它们的方差可能较低。通过建模激活值和梯度之间的耦合关系,可以更准确地识别这些关键维度。
技术框架:FASC框架主要包含以下几个步骤:1) 计算Fisher信息矩阵,用于估计每个激活维度对模型损失的影响;2) 使用Fisher信息矩阵对激活空间进行子空间选择,优先保留对知识表达贡献最大的维度;3) 对模型进行压缩,例如通过降低激活值的秩;4) 使用依赖违反分数( {ho})作为诊断指标,量化激活-梯度耦合,评估压缩效果。
关键创新:论文的关键创新在于提出了Fisher对齐子空间压缩(FASC)方法,该方法利用Fisher信息矩阵来指导LLM的压缩过程,从而更好地保留模型中存储的事实知识。与传统的基于方差的压缩方法不同,FASC关注激活值和梯度之间的耦合关系,能够识别对知识表达至关重要的低方差但高梯度敏感性的子空间。此外,论文还提出了依赖违反分数( {ho})作为一种通用诊断指标,用于量化激活-梯度耦合。
关键设计:Fisher信息矩阵的计算是FASC的关键步骤,论文可能采用了近似计算方法以降低计算复杂度。依赖违反分数( {ho})的具体计算公式和阈值选择也是重要的设计细节。此外,子空间选择的具体算法,例如如何根据Fisher信息矩阵选择保留哪些维度,也是影响压缩效果的关键因素。损失函数的设计可能也考虑了知识保留的约束。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在50%的秩缩减下,FASC在知识密集型基准(MMLU,LAMA)上比基于方差的方法提高了6-8%的准确率。更重要的是,使用FASC压缩后的7B模型能够达到与未压缩的13B模型相当的事实召回率,这充分证明了FASC在知识保留方面的优势。
🎯 应用场景
该研究成果可应用于各种需要部署大型语言模型的场景,尤其是在资源受限的边缘设备上,例如移动设备、嵌入式系统和物联网设备。通过FASC压缩,可以在保证模型性能的同时,显著降低模型大小和计算复杂度,从而实现LLM在这些设备上的高效部署。此外,该方法还可以用于模型蒸馏和知识迁移等任务。
📄 摘要(原文)
Post-training activation compression is essential for deploying Large Language Models (LLMs) on resource-constrained hardware. However, standard methods like Singular Value Decomposition (SVD) are gradient-blind: they preserve high-variance dimensions regardless of their impact on factual knowledge preservation. We introduce Fisher-Aligned Subspace Compression (FASC), a knowledge-aware compression framework that selects subspaces by directly modeling activation-gradient coupling, minimizing a second-order surrogate of the loss function. FASC leverages the Fisher Information Matrix to identify dimensions critical for factual knowledge, which often reside in low-variance but high-gradient-sensitivity subspaces. We propose the Dependence Violation Score (\r{ho}) as a general-purpose diagnostic metric that quantifies activation-gradient coupling, revealing where factual knowledge is stored within transformer architectures. Extensive experiments on Mistral-7B and Llama-3-8B demonstrate that FASC preserves 6-8% more accuracy on knowledge-intensive benchmarks (MMLU, LAMA) compared to variance-based methods at 50% rank reduction, effectively enabling a 7B model to match the factual recall of a 13B uncompressed model. Our analysis reveals that \r{ho} serves as a fundamental signal of stored knowledge, with high-\r{ho} layers emerging only when models internalize factual associations during training.