PRPO: Aligning Process Reward with Outcome Reward in Policy Optimization
作者: Ruiyi Ding, Yongxuan Lv, Xianhui Meng, Jiahe Song, Chao Wang, Chen Jiang, Yuan Cheng
分类: cs.LG, cs.AI
发布日期: 2026-01-12
备注: 8 pages, 2 figures
💡 一句话要点
PRPO:对齐过程奖励与结果奖励,提升策略优化效果
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 策略优化 过程奖励 结果奖励 多步推理 语言模型
📋 核心要点
- 多步推理任务中,语言模型策略优化面临奖励稀疏问题,难以有效指导中间推理步骤。
- PRPO通过结合结果奖励的可靠性和过程奖励的细粒度指导,实现更有效的策略优化。
- 实验表明,PRPO在MATH500数据集上显著提升了模型准确率,且计算效率高。
📝 摘要(中文)
针对大型语言模型在多步推理任务中策略优化面临的稀疏奖励问题,本文提出了过程相对策略优化(PRPO)方法。现有方法如GRPO将单一归一化的结果奖励分配给所有token,对中间推理步骤的指导有限。过程奖励模型(PRM)虽然提供密集反馈,但单独使用时存在过早崩溃的风险。PRPO在无Critic框架下,结合了结果可靠性和过程级别的指导。它基于语义线索分割推理序列,将PRM分数归一化为token级别的优势函数,并通过位置参数偏移将它们的分布与结果优势函数对齐。在MATH500数据集上,PRPO仅使用八次rollout且无需价值网络,就将Qwen2.5-Math-1.5B的准确率从61.2%提升至64.4%,展示了在无Critic优化中高效的细粒度信用分配。
🔬 方法详解
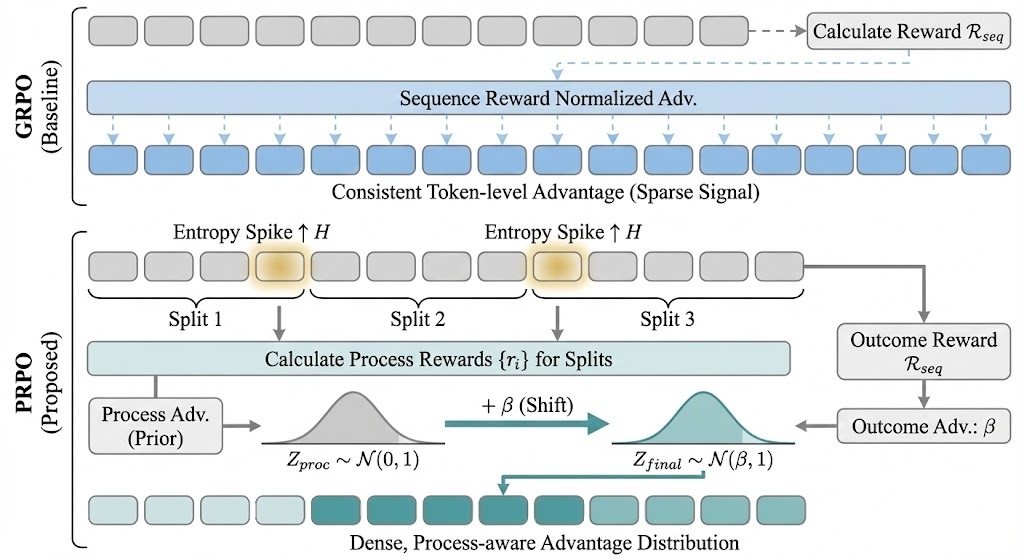
问题定义:现有的大型语言模型策略优化方法,尤其是在多步推理任务中,面临着奖励信号稀疏的问题。例如,GRPO方法将最终结果的奖励(outcome reward)简单地分配给所有生成的token,忽略了中间推理步骤的质量,导致模型难以学习到正确的推理过程。另一方面,虽然过程奖励模型(PRM)可以提供更密集的奖励信号,但如果单独使用,容易导致模型过早崩溃,即模型倾向于生成低奖励的早期token,从而导致输出被截断。
核心思路:PRPO的核心思路是将结果奖励的可靠性与过程奖励的细粒度指导相结合。具体来说,PRPO利用过程奖励模型(PRM)提供token级别的奖励信号,同时通过与结果奖励进行对齐,避免PRM可能导致的过早崩溃问题。这种结合使得模型既能学习到正确的推理过程,又能保证最终结果的可靠性。
技术框架:PRPO的整体框架包括以下几个主要步骤:1) 序列分割:根据语义线索将推理序列分割成多个片段。2) 过程奖励归一化:将PRM提供的过程奖励分数归一化为token级别的优势函数。3) 优势函数对齐:通过位置参数偏移,将过程奖励优势函数的分布与结果奖励优势函数的分布对齐。4) 策略优化:利用对齐后的优势函数进行策略优化,更新语言模型的参数。
关键创新:PRPO的关键创新在于提出了一个无Critic的框架,该框架能够有效地结合过程奖励和结果奖励,从而实现更高效的策略优化。与传统的需要训练价值网络的方法不同,PRPO直接利用过程奖励模型提供的奖励信号,并通过优势函数对齐的方式,避免了价值网络带来的额外计算开销和训练难度。
关键设计:PRPO的关键设计包括:1) 语义线索分割:使用启发式规则或预训练模型来识别推理序列中的语义分割点,例如,可以根据关键词或短语来划分序列。2) 过程奖励归一化:使用softmax函数或其他归一化方法将PRM分数转换为token级别的优势函数,确保优势函数的取值范围在合理范围内。3) 优势函数对齐:通过调整过程奖励优势函数的位置参数(例如,均值),使其与结果奖励优势函数的分布尽可能接近。具体来说,可以使用最小化KL散度或其他距离度量的方法来确定最佳的位置参数偏移量。
🖼️ 关键图片
📊 实验亮点
实验结果表明,PRPO在MATH500数据集上取得了显著的性能提升。具体来说,使用Qwen2.5-Math-1.5B模型,PRPO仅使用八次rollout且无需价值网络,就将准确率从61.2%提升至64.4%,超过了GRPO方法。这表明PRPO能够更有效地利用过程奖励信息,实现更高效的策略优化。
🎯 应用场景
PRPO方法具有广泛的应用前景,可以应用于各种需要多步推理的自然语言处理任务,例如数学问题求解、代码生成、对话系统等。通过提供更细粒度的奖励信号,PRPO可以帮助语言模型学习到更有效的推理策略,从而提高任务完成的准确性和效率。此外,PRPO的无Critic框架也使其更易于部署和应用。
📄 摘要(原文)
Policy optimization for large language models often suffers from sparse reward signals in multi-step reasoning tasks. Critic-free methods like GRPO assign a single normalized outcome reward to all tokens, providing limited guidance for intermediate reasoning . While Process Reward Models (PRMs) offer dense feedback, they risk premature collapse when used alone, as early low-reward tokens can drive policies toward truncated outputs. We introduce Process Relative Policy Optimization (PRPO), which combines outcome reliability with process-level guidance in a critic-free framework. PRPO segments reasoning sequences based on semantic clues, normalizes PRM scores into token-level advantages, and aligns their distribution with outcome advantages through location-parameter shift. On MATH500, PRPO improves Qwen2.5-Math-1.5B accuracy from 61.2% to 64.4% over GRPO using only eight rollouts and no value network, demonstrating efficient fine-grained credit assignment within critic-free optimization.