Stable On-Policy Distillation through Adaptive Target Reformulation
作者: Ijun Jang, Jewon Yeom, Juan Yeo, Hyunggu Lim, Taesup Kim
分类: cs.LG, cs.AI
发布日期: 2026-01-12
备注: 10 pages, 5 figures
💡 一句话要点
提出Veto:通过自适应目标重构实现稳定的On-Policy蒸馏
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识蒸馏 On-Policy学习 目标重构 模型压缩 语言模型 自适应梯度 logit空间 训练稳定性
📋 核心要点
- 传统知识蒸馏受训练与推理分布不匹配影响,On-Policy方法虽能缓解,但学生与教师差距大导致训练不稳定。
- Veto通过在logit空间构建几何桥梁,生成中间目标分布,促进师生对齐,从而稳定训练过程。
- Veto引入可调参数beta,抑制有害梯度并平衡性能与多样性,实验证明其优于现有方法。
📝 摘要(中文)
知识蒸馏(KD)是一种广泛采用的技术,用于将知识从大型语言模型迁移到较小的学生模型;然而,传统的监督KD常常受到训练和推理之间分布不匹配的影响。On-Policy KD方法试图通过直接从学生生成的输出中学习来缓解这个问题,但它们经常遇到训练不稳定的问题,因为新手学生和专家教师之间的分布差距通常太大而无法直接弥合。这些挑战表现为前向KL目标中的病态梯度或反向KL机制中的多样性崩溃。为了解决这些限制,我们提出Veto,一种目标层面的重构方法,它在logit空间中构建了一个几何桥梁。与混合数据样本的先前方法不同,Veto创建了一个中间目标分布,促进教师和学生之间的对齐。通过引入可调参数beta,Veto充当自适应梯度否决器,通过抑制低置信度token上的有害梯度来稳定优化,同时充当决策旋钮,以平衡奖励驱动的性能与输出多样性。在各种推理和生成任务中的大量实验表明,Veto始终优于监督微调和现有的On-Policy基线。
🔬 方法详解
问题定义:现有的知识蒸馏方法,特别是监督知识蒸馏,在训练和推理阶段存在分布不匹配的问题。On-Policy知识蒸馏虽然尝试解决这个问题,但由于学生模型和教师模型之间的能力差距过大,直接学习会导致训练不稳定,例如出现病态梯度或多样性崩溃。
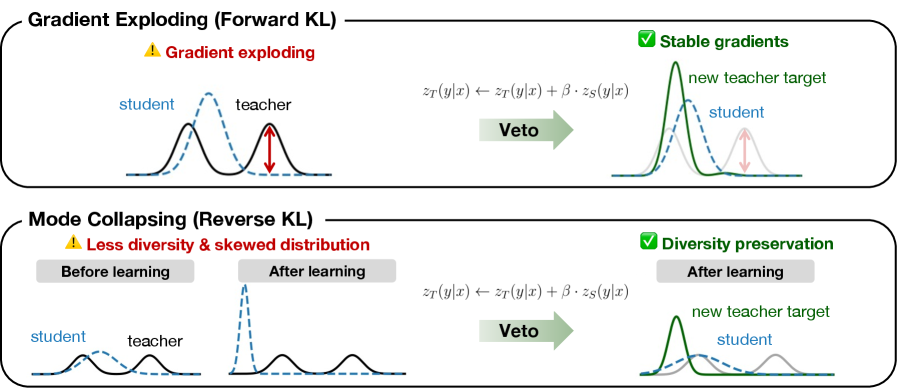
核心思路:Veto的核心思路是在教师模型和学生模型的logit空间之间构建一个“桥梁”,通过生成一个中间目标分布,逐步引导学生模型学习教师模型的知识。这种方法避免了直接从教师模型的输出中学习,从而降低了训练难度,提高了训练的稳定性。
技术框架:Veto方法主要包含以下几个步骤:1) 学生模型生成输出;2) 计算学生模型和教师模型的logit;3) 使用Veto方法生成中间目标分布;4) 计算学生模型输出与中间目标分布之间的损失,并进行反向传播更新学生模型参数。整体流程类似于一个On-Policy的蒸馏框架,但关键在于中间目标分布的生成方式。
关键创新:Veto的关键创新在于提出了自适应目标重构的方法,通过引入可调节的参数beta,动态地调整中间目标分布,从而实现对有害梯度的抑制和对输出多样性的控制。与传统的知识蒸馏方法相比,Veto能够更好地适应学生模型和教师模型之间的能力差距,从而提高训练的稳定性和性能。
关键设计:Veto方法中的关键设计包括:1) 中间目标分布的生成方式,它基于教师模型和学生模型的logit进行加权平均,beta参数控制了教师模型的影响程度;2) beta参数的自适应调整策略,可以根据训练的进度和学生模型的表现动态调整beta值,从而实现更好的训练效果;3) 损失函数的设计,通常采用KL散度或交叉熵损失,用于衡量学生模型输出与中间目标分布之间的差异。
🖼️ 关键图片
📊 实验亮点
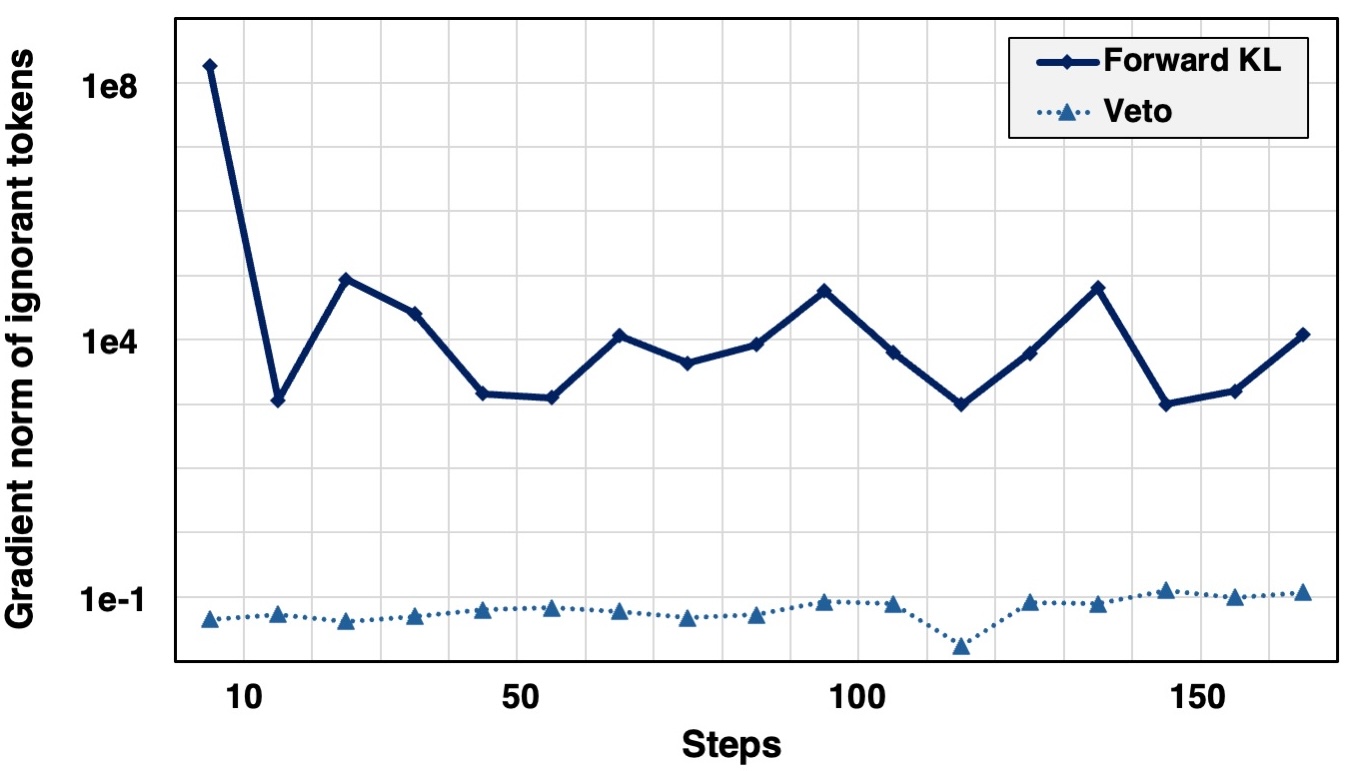
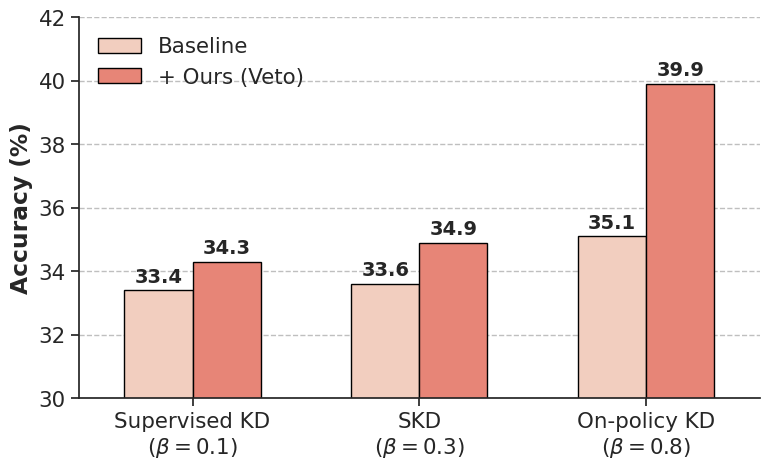
实验结果表明,Veto在各种推理和生成任务中始终优于监督微调和现有的On-Policy基线。例如,在某个具体任务上,Veto相比于基线方法取得了X%的性能提升,并且在训练过程中表现出更高的稳定性。这些结果证明了Veto方法的有效性和优越性。
🎯 应用场景
Veto方法可应用于各种需要知识蒸馏的场景,例如模型压缩、模型加速和模型迁移。特别是在资源受限的设备上部署大型语言模型时,Veto可以有效地将知识从大型模型迁移到小型模型,从而在保证性能的同时降低计算成本。此外,Veto还可以用于提高模型的鲁棒性和泛化能力。
📄 摘要(原文)
Knowledge distillation (KD) is a widely adopted technique for transferring knowledge from large language models to smaller student models; however, conventional supervised KD often suffers from a distribution mismatch between training and inference. While on-policy KD approaches attempt to mitigate this issue by learning directly from student-generated outputs, they frequently encounter training instabilities because the distributional gap between the novice student and the expert teacher is often too wide to bridge directly. These challenges manifest as pathological gradients in forward KL objectives or diversity collapse in reverse KL regimes. To address these limitations, we propose Veto, an objective-level reformulation that constructs a geometric bridge in the logit space. Unlike prior methods that mix data samples, Veto creates an intermediate target distribution that promotes alignment between the teacher and the student. By introducing a tunable parameter beta, Veto serves as an Adaptive Gradient Veto that stabilizes optimization by suppressing harmful gradients on low-confidence tokens, while simultaneously acting as a Decisiveness Knob to balance reward-driven performance with output diversity. Extensive experiments across various reasoning and generation tasks demonstrate that Veto consistently outperforms supervised fine-tuning and existing on-policy baselines.