Reward-Preserving Attacks For Robust Reinforcement Learning
作者: Lucas Schott, Elies Gherbi, Hatem Hajri, Sylvain Lamprier
分类: cs.LG
发布日期: 2026-01-12
备注: 19 pages, 6 figures, 4 algorithms, preprint
💡 一句话要点
提出α-奖励保持攻击,提升强化学习在对抗环境下的鲁棒性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 对抗鲁棒性 对抗攻击 自适应攻击 深度强化学习
📋 核心要点
- 强化学习对抗鲁棒性面临挑战,现有方法难以平衡攻击强度与学习效果。
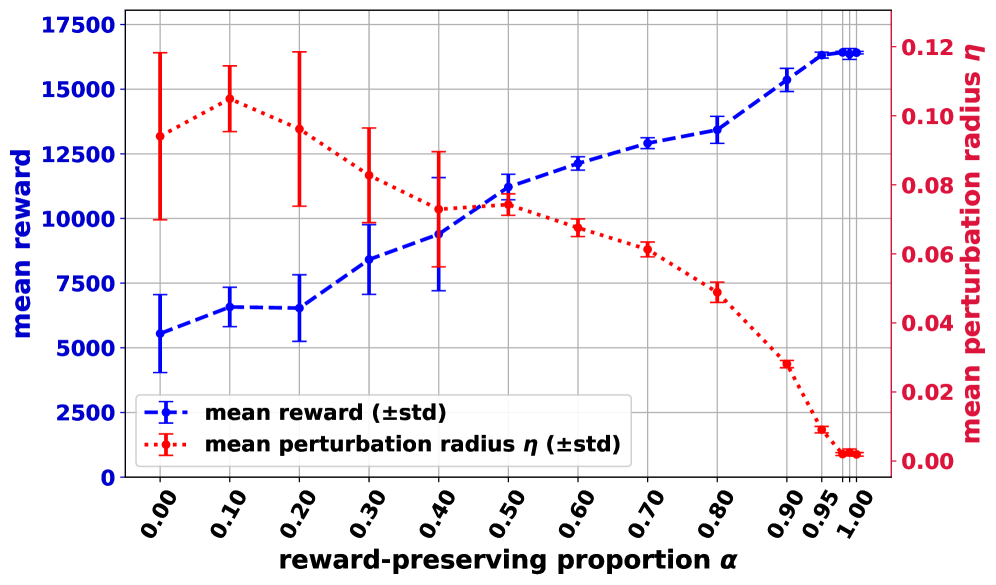
- 提出α-奖励保持攻击,自适应调整攻击强度,保证部分回报差距可实现。
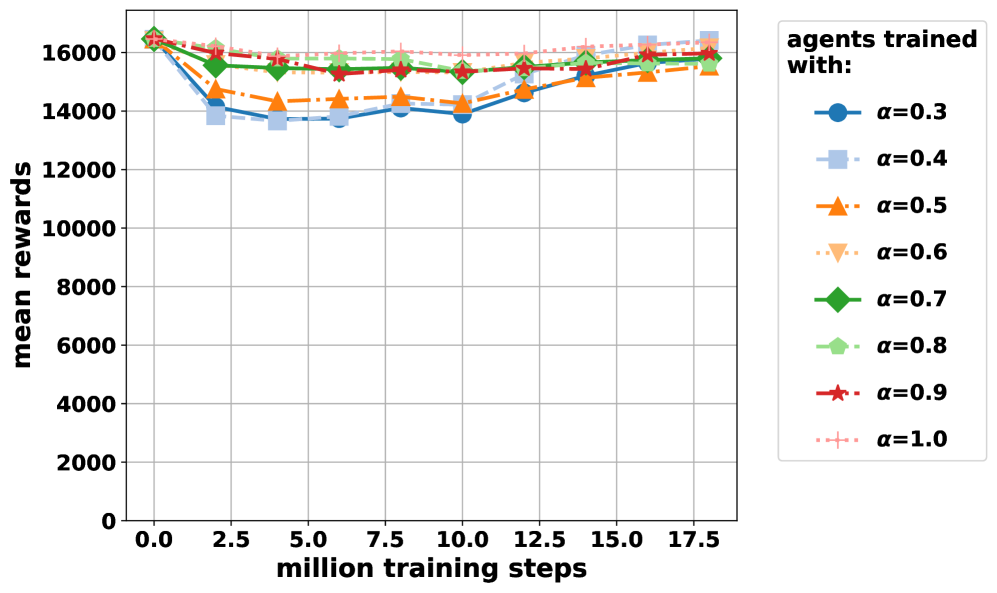
- 实验表明,该方法在保持名义性能的同时,显著提升了对抗环境下的鲁棒性。
📝 摘要(中文)
强化学习中的对抗鲁棒性是一个难题,因为扰动会影响整个轨迹:强攻击会破坏学习,而弱攻击几乎不能提高鲁棒性,并且适当的攻击强度因状态而异。我们提出了α-奖励保持攻击,它调整对抗者的强度,使得在每个状态下,名义回报与最坏情况回报之间的差距的α部分仍然可以实现。在深度强化学习中,我们使用基于梯度的攻击方向,并学习一个状态相关的幅度η≤η_B,该幅度通过一个评论家Q^π_α((s,a),η)来选择,该评论家在不同的半径上进行离线训练。这种自适应调整校准了攻击强度,并且在中间α值下,提高了跨半径的鲁棒性,同时保持了名义性能,优于固定半径和随机半径的基线。
🔬 方法详解
问题定义:强化学习在对抗环境下的鲁棒性问题,具体而言,如何在存在对抗扰动的情况下,保证智能体能够学习到有效的策略。现有方法的痛点在于,过强的攻击会直接破坏学习过程,导致智能体无法收敛;而过弱的攻击则无法有效提升智能体的鲁棒性,难以应对真实世界中可能出现的各种扰动。此外,不同状态下所需的攻击强度也不同,固定强度的攻击难以达到最优效果。
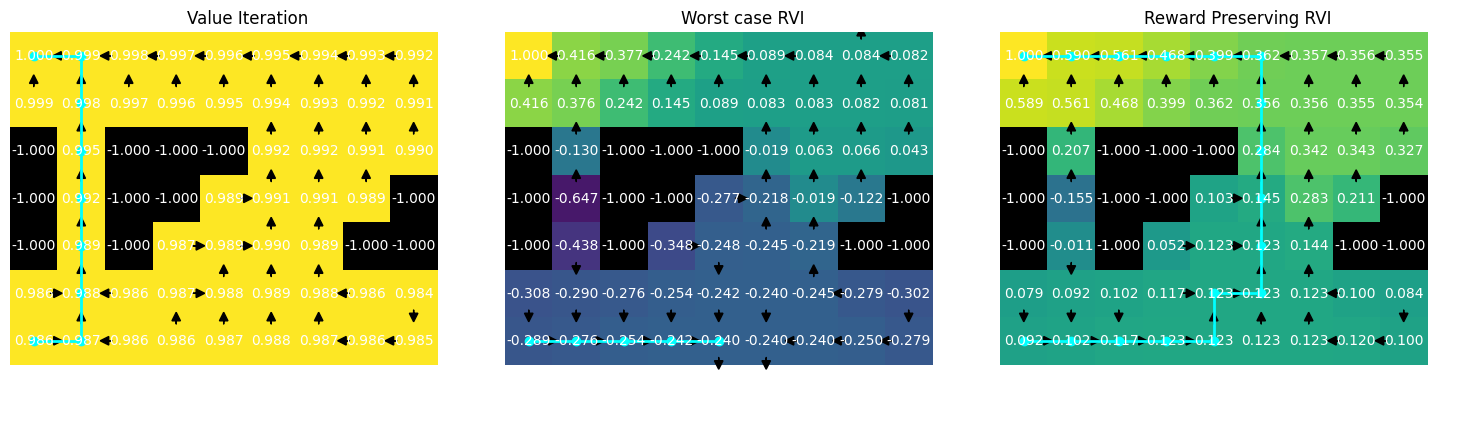
核心思路:论文的核心解决思路是提出一种自适应的攻击策略,称为α-奖励保持攻击。该策略的核心思想是,在每个状态下,调整对抗者的攻击强度,使得智能体仍然能够实现名义回报与最坏情况回报之间差距的α部分。通过这种方式,可以保证攻击的强度既不会过强以至于破坏学习,也不会过弱以至于无法提升鲁棒性。
技术框架:整体框架包含一个智能体和一个对抗者。智能体负责学习策略,对抗者负责生成扰动。对抗者的攻击强度由一个状态相关的幅度η控制,该幅度通过一个评论家网络Q^π_α((s,a),η)来选择。评论家网络的目标是评估在给定状态、动作和攻击幅度下,智能体能够获得的期望回报。智能体和对抗者通过交替训练的方式进行学习,智能体学习最大化期望回报,对抗者学习最小化期望回报,同时保证回报差距的α部分仍然可以实现。
关键创新:最重要的技术创新点在于提出了α-奖励保持攻击的思想,通过自适应地调整攻击强度,实现了在保持名义性能的同时,显著提升了对抗鲁棒性。与现有方法相比,该方法能够更好地平衡攻击强度与学习效果,并且能够适应不同状态下所需的攻击强度。
关键设计:关键的设计包括:1) 使用基于梯度的攻击方向,以保证攻击的有效性;2) 使用评论家网络Q^π_α((s,a),η)来评估不同攻击幅度下的期望回报,从而实现自适应的攻击强度调整;3) 使用离线训练的方式训练评论家网络,以提高训练效率和稳定性;4) 通过调整参数α来控制攻击的保守程度,从而在名义性能和鲁棒性之间进行权衡。
🖼️ 关键图片
📊 实验亮点
实验结果表明,提出的α-奖励保持攻击方法在多个强化学习任务中都取得了显著的性能提升。与固定半径和随机半径的基线方法相比,该方法在保持名义性能的同时,显著提高了对抗环境下的鲁棒性。例如,在某个任务中,该方法可以将智能体的鲁棒性提高到原来的两倍以上。
🎯 应用场景
该研究成果可应用于各种需要在对抗环境下运行的强化学习系统,例如自动驾驶、机器人控制、网络安全等。通过提高智能体在对抗环境下的鲁棒性,可以有效防止恶意攻击,保证系统的安全性和可靠性。此外,该方法还可以用于评估和改进现有强化学习算法的鲁棒性。
📄 摘要(原文)
Adversarial robustness in RL is difficult because perturbations affect entire trajectories: strong attacks can break learning, while weak attacks yield little robustness, and the appropriate strength varies by state. We propose $α$-reward-preserving attacks, which adapt the strength of the adversary so that an $α$ fraction of the nominal-to-worst-case return gap remains achievable at each state. In deep RL, we use a gradient-based attack direction and learn a state-dependent magnitude $η\le η_{\mathcal B}$ selected via a critic $Q^π_α((s,a),η)$ trained off-policy over diverse radii. This adaptive tuning calibrates attack strength and, with intermediate $α$, improves robustness across radii while preserving nominal performance, outperforming fixed- and random-radius baselines.