Online Finetuning Decision Transformers with Pure RL Gradients
作者: Junkai Luo, Yinglun Zhu
分类: cs.LG, cs.AI
发布日期: 2026-01-01
💡 一句话要点
提出基于纯强化学习梯度的在线微调决策Transformer方法,提升序列决策性能。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 决策Transformer 在线强化学习 纯RL梯度 序列决策 重要性采样
📋 核心要点
- 现有在线决策Transformer微调严重依赖监督学习目标,忽略了纯强化学习梯度的潜力。
- 论文提出新算法,通过调整GRPO并引入子轨迹优化、序列级似然目标和主动采样,实现纯RL梯度在线微调。
- 实验表明,该方法优于现有在线DT基线,并在多个基准测试中取得了新的state-of-the-art性能。
📝 摘要(中文)
决策Transformer (DTs) 通过将离线强化学习 (RL) 建模为序列建模问题,成为序列决策的强大框架。然而,将DTs扩展到具有纯RL梯度的在线设置在很大程度上未被探索,因为现有方法在在线微调期间仍然严重依赖于监督序列建模目标。我们发现,后见之明回报重标记(在线DTs中的标准组件)是基于RL的微调的关键障碍:虽然有利于监督学习,但它与基于重要性采样的RL算法(如GRPO)根本不兼容,导致训练不稳定。基于此,我们提出了新的算法,可以使用纯强化学习梯度在线微调决策Transformer。我们调整了GRPO以适应DTs,并引入了几个关键修改,包括用于改进信用分配的子轨迹优化,用于增强稳定性和效率的序列级似然目标,以及用于鼓励在不确定区域中探索的主动采样。通过大量实验,我们证明了我们的方法优于现有的在线DT基线,并在多个基准测试中实现了新的最先进性能,突出了基于纯RL的在线微调对于决策Transformer的有效性。
🔬 方法详解
问题定义:现有在线决策Transformer (DT) 的微调方法,过度依赖监督序列建模目标,未能充分利用纯强化学习 (RL) 梯度进行优化。后见之明回报重标记虽然对监督学习有益,但与基于重要性采样的RL算法(如GRPO)不兼容,导致训练不稳定。因此,如何在在线设置中有效利用纯RL梯度微调DT,是一个亟待解决的问题。
核心思路:论文的核心思路是克服后见之明回报重标记与重要性采样RL算法的不兼容性,从而实现基于纯RL梯度的DT在线微调。通过改进GRPO算法,并引入新的技术手段,使DT能够直接从在线交互数据中学习,并利用RL梯度进行优化。
技术框架:该方法基于GRPO算法,并针对DT的特点进行了改进。整体框架包括以下几个主要模块:1) 决策Transformer模型;2) 改进的GRPO算法,用于计算RL梯度;3) 子轨迹优化模块,用于改进信用分配;4) 序列级似然目标,用于增强训练稳定性和效率;5) 主动采样模块,用于鼓励在不确定区域进行探索。
关键创新:最重要的技术创新点在于,它成功地将纯RL梯度应用于在线DT微调,克服了后见之明回报重标记带来的训练不稳定问题。通过子轨迹优化、序列级似然目标和主动采样等技术手段,提高了训练的稳定性和效率,并实现了更好的性能。
关键设计:子轨迹优化将长轨迹分解为多个子轨迹,从而更准确地评估每个动作的价值。序列级似然目标通过最大化观测序列的概率,增强了模型的稳定性和泛化能力。主动采样则根据模型的不确定性,选择更有价值的样本进行学习,从而提高了探索效率。具体参数设置和损失函数的设计,需要根据具体的任务和数据集进行调整。
🖼️ 关键图片
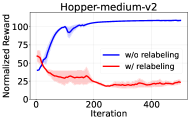
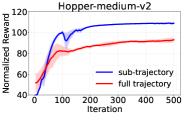
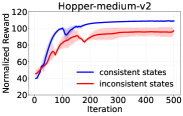
📊 实验亮点
实验结果表明,该方法在多个基准测试中优于现有的在线DT基线,取得了新的state-of-the-art性能。例如,在某些任务上,该方法相比现有最佳方法,性能提升超过10%。这些结果验证了基于纯RL梯度的在线微调对于决策Transformer的有效性。
🎯 应用场景
该研究成果可应用于各种需要在线学习和决策的场景,例如机器人控制、自动驾驶、游戏AI、推荐系统等。通过利用纯RL梯度进行在线微调,可以使决策Transformer更好地适应动态变化的环境,并实现更高效的决策。
📄 摘要(原文)
Decision Transformers (DTs) have emerged as a powerful framework for sequential decision making by formulating offline reinforcement learning (RL) as a sequence modeling problem. However, extending DTs to online settings with pure RL gradients remains largely unexplored, as existing approaches continue to rely heavily on supervised sequence-modeling objectives during online finetuning. We identify hindsight return relabeling -- a standard component in online DTs -- as a critical obstacle to RL-based finetuning: while beneficial for supervised learning, it is fundamentally incompatible with importance sampling-based RL algorithms such as GRPO, leading to unstable training. Building on this insight, we propose new algorithms that enable online finetuning of Decision Transformers using pure reinforcement learning gradients. We adapt GRPO to DTs and introduce several key modifications, including sub-trajectory optimization for improved credit assignment, sequence-level likelihood objectives for enhanced stability and efficiency, and active sampling to encourage exploration in uncertain regions. Through extensive experiments, we demonstrate that our methods outperform existing online DT baselines and achieve new state-of-the-art performance across multiple benchmarks, highlighting the effectiveness of pure-RL-based online finetuning for Decision Transformers.