Combining datasets with different ground truths using Low-Rank Adaptation to generalize image-based CNN models for photometric redshift prediction
作者: Vikram Seenivasan, Srinath Saikrishnan, Andrew Lizarraga, Jonathan Soriano, Bernie Boscoe, Tuan Do
分类: astro-ph.IM, cs.LG
发布日期: 2026-01-01
备注: 11 pages, 7 figures, 3 tables, Accepted to the Conference on Neural Information Processing Systems (NeurIPS), Machine Learning and the Physical Sciences (ML4PS) Workshop 2025
💡 一句话要点
提出低秩适应方法以结合不同真值数据集提升红移预测精度
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 低秩适应 红移预测 卷积神经网络 数据融合 天体物理 模型微调 迁移学习
📋 核心要点
- 现有的红移估计方法在数据稀缺和准确性方面存在挑战,尤其是光谱红移数据获取困难且时间成本高。
- 本研究提出使用低秩适应(LoRA)技术,通过微调基础模型来结合不同的红移真值数据集,提高模型的泛化能力。
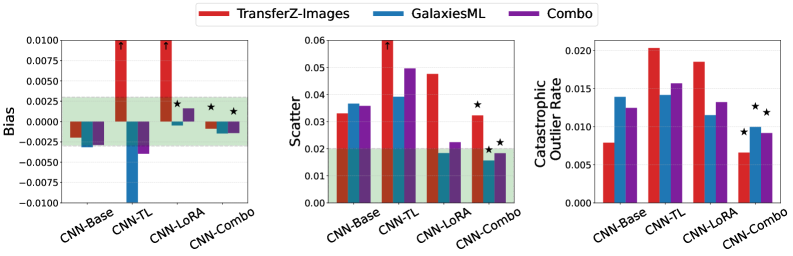
- 实验结果显示,LoRA方法在减少模型偏差和散射方面表现优异,相比传统迁移学习方法有显著提升。
📝 摘要(中文)
本研究展示了如何利用低秩适应(LoRA)技术结合不同的星系成像数据集,以提高基于卷积神经网络(CNN)的红移估计精度。LoRA是一种已在大语言模型中应用的技术,通过添加适配器网络来调整模型权重和偏置,从而高效微调大型基础模型。我们首先使用一个包含广泛星系类型但准确性较低的光度红移真值数据集训练基础模型,然后在光谱红移真值数据集上使用LoRA进行微调。光谱红移数据更为准确,但仅限于亮星系且获取时间较长,因此在大规模调查中较少可用。结合这两个数据集理想情况下可以产生更准确的模型。实验结果表明,LoRA模型的偏差减少约2.5倍,散射减少约2.2倍,且在结合数据集上重新训练的模型虽然泛化能力更强,但计算时间成本较高。我们的研究表明LoRA在天体物理回归模型微调中具有重要应用潜力。
🔬 方法详解
问题定义:本研究旨在解决红移估计中数据稀缺和准确性不足的问题。现有方法在使用光谱红移数据时面临获取难度大和时间成本高的挑战。
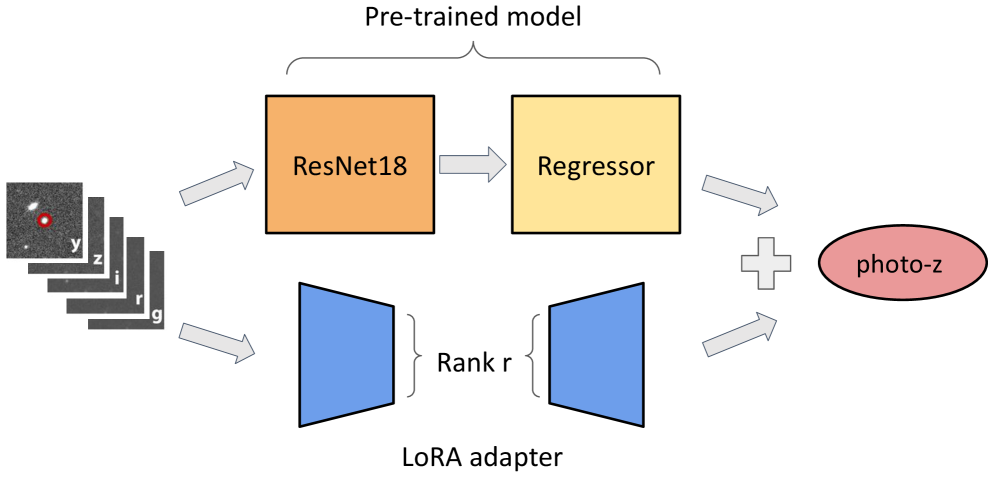
核心思路:论文提出利用低秩适应(LoRA)技术,通过在基础模型上添加适配器网络,结合不同的红移真值数据集进行微调,从而提高模型的泛化能力和准确性。
技术框架:整体流程包括首先在光度红移数据集上训练基础模型,然后在光谱红移数据集上使用LoRA进行微调。模型训练分为两个阶段,分别针对不同数据集的特点进行优化。
关键创新:LoRA的引入使得模型能够在不进行完全重训练的情况下,灵活适应不同的数据集,从而在天体物理领域实现更高效的模型微调。与传统的迁移学习方法相比,LoRA在减少模型偏差和散射方面表现更优。
关键设计:在模型训练中,LoRA通过调整适配器网络的参数来实现微调,损失函数设计上考虑了不同数据集的特性,以确保模型在两个数据集上的性能均衡。
🖼️ 关键图片

📊 实验亮点
实验结果表明,使用LoRA方法的模型相比传统迁移学习方法,偏差减少约2.5倍,散射减少约2.2倍。此外,虽然在结合数据集上重新训练的模型泛化能力更强,但计算时间成本显著增加,显示出LoRA在效率与效果之间的平衡。
🎯 应用场景
该研究的潜在应用领域包括天文学和宇宙学,尤其是在红移预测和星系分类等任务中。通过结合不同的数据集,研究者可以更有效地利用现有的天体物理模型,推动对宇宙结构和演化的理解。未来,LoRA技术可能在其他数据稀缺的科学领域中也展现出重要价值。
📄 摘要(原文)
In this work, we demonstrate how Low-Rank Adaptation (LoRA) can be used to combine different galaxy imaging datasets to improve redshift estimation with CNN models for cosmology. LoRA is an established technique for large language models that adds adapter networks to adjust model weights and biases to efficiently fine-tune large base models without retraining. We train a base model using a photometric redshift ground truth dataset, which contains broad galaxy types but is less accurate. We then fine-tune using LoRA on a spectroscopic redshift ground truth dataset. These redshifts are more accurate but limited to bright galaxies and take orders of magnitude more time to obtain, so are less available for large surveys. Ideally, the combination of the two datasets would yield more accurate models that generalize well. The LoRA model performs better than a traditional transfer learning method, with $\sim2.5\times$ less bias and $\sim$2.2$\times$ less scatter. Retraining the model on a combined dataset yields a model that generalizes better than LoRA but at a cost of greater computation time. Our work shows that LoRA is useful for fine-tuning regression models in astrophysics by providing a middle ground between full retraining and no retraining. LoRA shows potential in allowing us to leverage existing pretrained astrophysical models, especially for data sparse tasks.