Dynamic Bayesian Optimization Framework for Instruction Tuning in Partial Differential Equation Discovery
作者: Junqi Qu, Yan Zhang, Shangqian Gao, Shibo Li
分类: cs.LG
发布日期: 2025-12-31
💡 一句话要点
NeuroSymBO:动态贝叶斯优化指令调优偏微分方程发现
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 偏微分方程发现 大型语言模型 指令调优 贝叶斯优化 符号回归
📋 核心要点
- 现有方法在偏微分方程发现中依赖静态提示,导致LLM输出对提示语措辞敏感,模型易陷入次优解。
- NeuroSymBO将提示工程视为序列决策问题,通过动态选择指令来适应生成过程的演变状态。
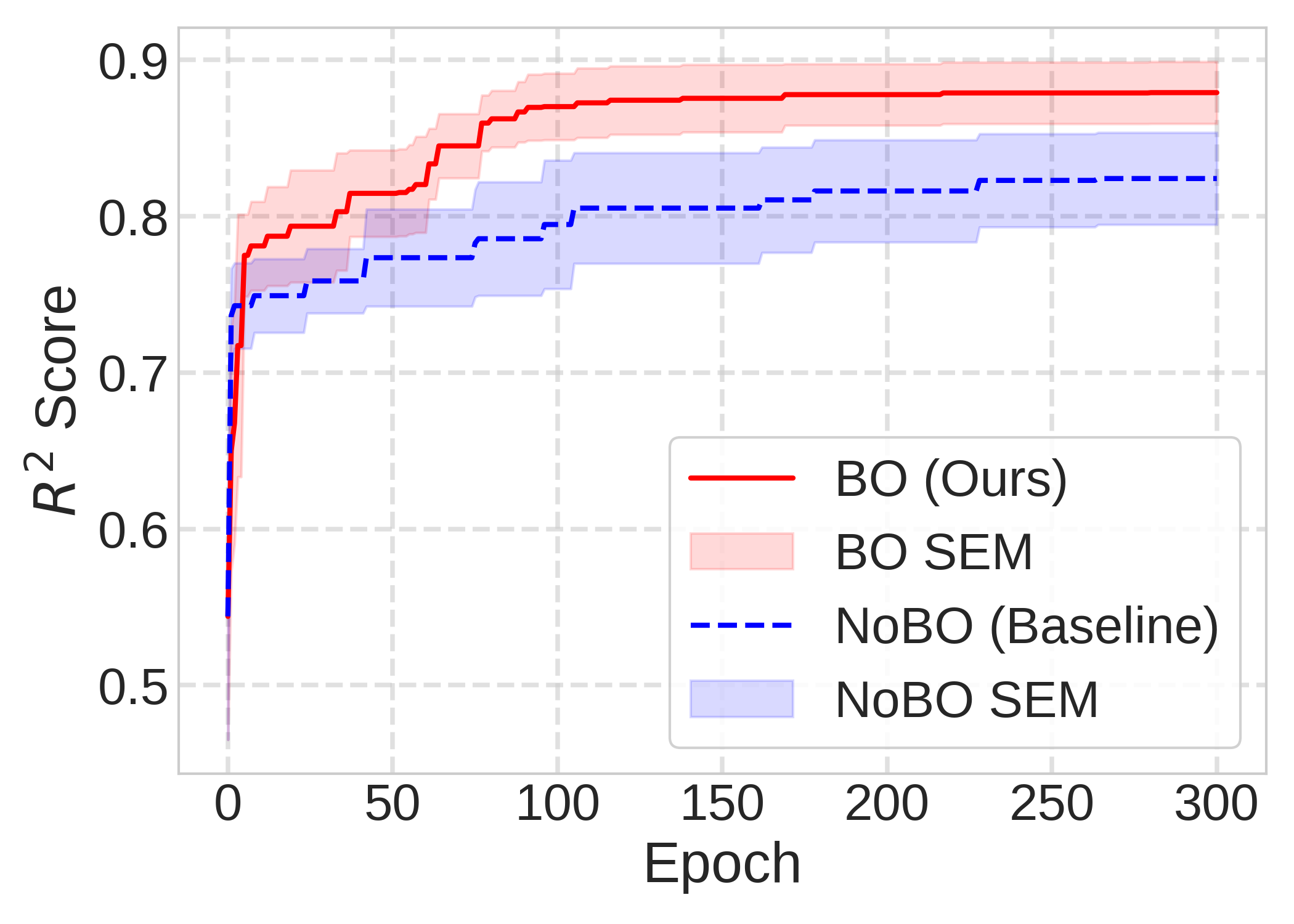
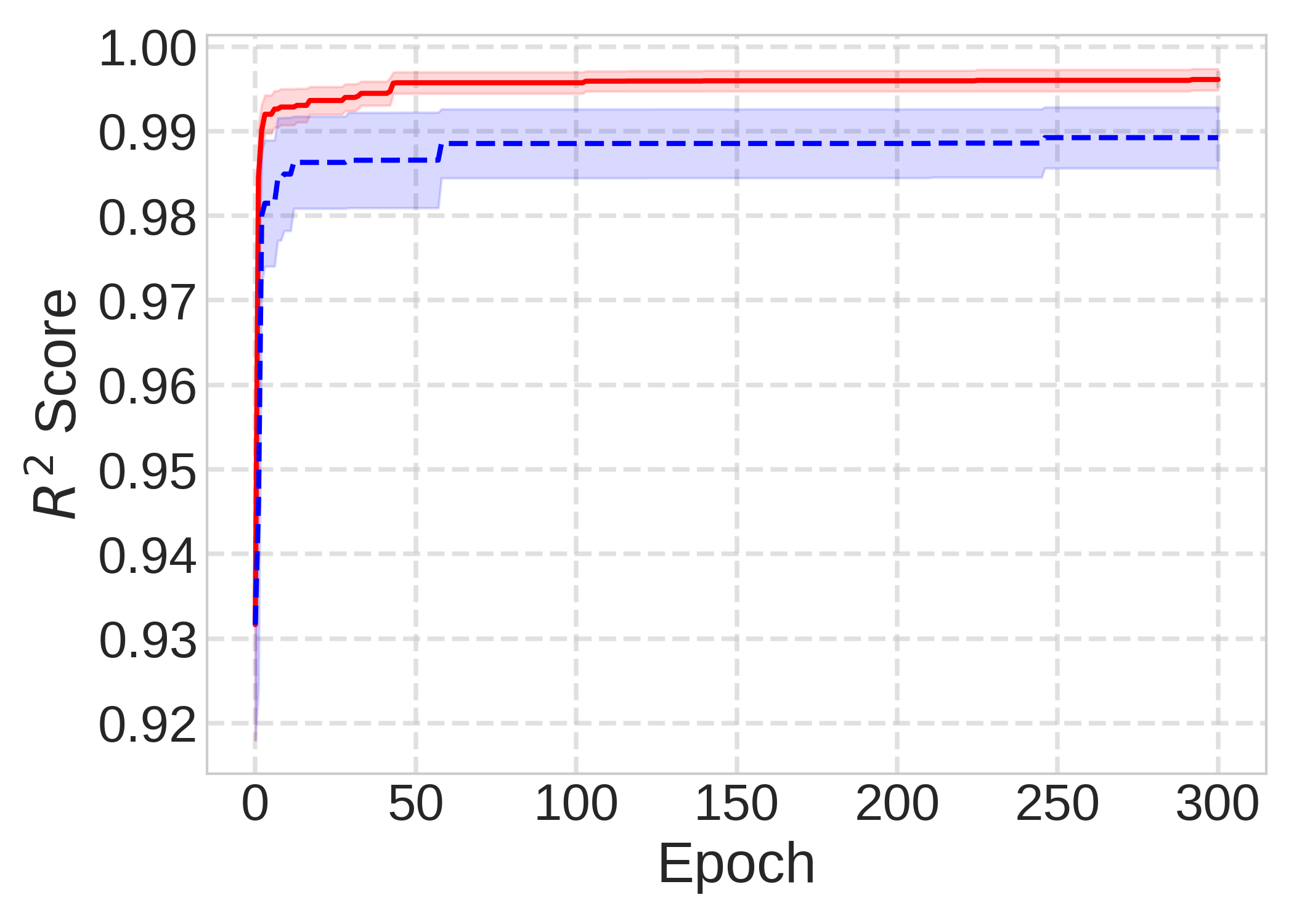
- 实验表明,NeuroSymBO在偏微分方程发现任务中显著优于固定提示,实现了更高的恢复率和更精简的解。
📝 摘要(中文)
大型语言模型(LLMs)在方程发现方面展现出潜力,但其输出对提示语措辞高度敏感,我们称之为指令脆性。静态提示无法适应多步生成过程的演变状态,导致模型停滞在次优解。为了解决这个问题,我们提出了NeuroSymBO,它将提示工程重新定义为一个序列决策问题。我们的方法维护一个离散的推理策略库,并使用贝叶斯优化,基于数值反馈在每个步骤选择最优指令。在偏微分方程发现基准上的实验表明,自适应指令选择显著优于固定提示,以更精简的解决方案实现了更高的恢复率。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在偏微分方程(PDE)发现中存在的“指令脆性”问题。现有方法依赖于静态的提示语,无法根据生成过程的中间状态进行调整,导致模型容易陷入局部最优,难以发现正确的方程形式。这种对提示语的敏感性限制了LLM在科学发现领域的应用。
核心思路:论文的核心思路是将提示工程重新建模为一个序列决策问题。在多步生成过程中,不再使用固定的提示语,而是根据当前模型的输出和数值反馈,动态地选择最合适的指令。这种自适应的指令选择策略能够引导模型逐步逼近正确的解。
技术框架:NeuroSymBO框架包含以下几个主要模块:1) 推理策略库:维护一个离散的指令集合,每个指令代表一种不同的推理策略。2) 贝叶斯优化器:使用贝叶斯优化算法来选择每个步骤的最优指令。优化目标是基于数值反馈(例如,方程的残差)来评估生成方程的质量。3) 状态表示:将当前模型的输出和数值反馈编码为状态向量,作为贝叶斯优化器的输入。4) 方程生成器:使用LLM根据选定的指令生成候选方程。整个流程是一个迭代过程,直到满足停止条件或达到最大迭代次数。
关键创新:该方法最重要的创新点在于将静态的提示工程转变为动态的指令选择过程。通过贝叶斯优化,NeuroSymBO能够根据模型的中间状态自适应地调整指令,从而克服了传统方法中指令脆性的问题。这种动态指令选择策略使得LLM能够更好地探索解空间,发现更准确、更精简的方程。
关键设计:推理策略库的设计至关重要,需要包含多样化的推理策略,以覆盖不同的方程形式和求解方法。贝叶斯优化器的选择也需要仔细考虑,以平衡探索和利用,快速找到最优指令。状态表示的设计需要能够充分捕捉模型的输出和数值反馈的信息。此外,还需要设计合适的奖励函数,以指导贝叶斯优化器选择能够生成高质量方程的指令。
🖼️ 关键图片

📊 实验亮点
实验结果表明,NeuroSymBO在PDE发现基准上显著优于固定提示方法,实现了更高的方程恢复率。与固定提示相比,NeuroSymBO能够发现更精简的方程形式,表明其具有更强的泛化能力。具体性能提升数据在论文中有详细展示,证明了动态指令选择策略的有效性。
🎯 应用场景
该研究成果可应用于科学发现、工程设计等领域,帮助研究人员利用大型语言模型自动发现偏微分方程,加速科学研究进程。通过动态指令调优,可以提高方程发现的准确性和效率,降低对人工提示工程的依赖,具有重要的实际应用价值和潜力。未来可扩展到其他类型的方程发现和符号回归任务。
📄 摘要(原文)
Large Language Models (LLMs) show promise for equation discovery, yet their outputs are highly sensitive to prompt phrasing, a phenomenon we term instruction brittleness. Static prompts cannot adapt to the evolving state of a multi-step generation process, causing models to plateau at suboptimal solutions. To address this, we propose NeuroSymBO, which reframes prompt engineering as a sequential decision problem. Our method maintains a discrete library of reasoning strategies and uses Bayesian Optimization to select the optimal instruction at each step based on numerical feedback. Experiments on PDE discovery benchmarks show that adaptive instruction selection significantly outperforms fixed prompts, achieving higher recovery rates with more parsimonious solutions.