Many Minds from One Model: Bayesian-Inspired Transformers for Population Diversity
作者: Diji Yang, Yi Zhang
分类: cs.LG, cs.CL
发布日期: 2025-12-31 (更新: 2026-01-15)
💡 一句话要点
提出Population Bayesian Transformers,从单一预训练LLM中采样多样化模型实例,提升生成多样性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Transformer 大型语言模型 贝叶斯方法 模型多样性 零样本学习 强化学习 文本生成 群体智能
📋 核心要点
- 现有Transformer模型训练为单一思维模式,缺乏多样性,限制了其在复杂任务中的表现。
- B-Trans通过在归一化层注入随机性,构建贝叶斯后验代理,从预训练LLM中采样多样化模型实例。
- 实验表明,B-Trans在零样本生成和强化学习任务中,提升了响应多样性并改善了任务性能。
📝 摘要(中文)
尽管Transformer模型规模庞大且性能卓越,但通常被训练成单一思维的系统:优化过程产生确定性的参数集,代表关于数据的单一功能假设。受人类群体智能涌现于个体多样性行为的类比启发,我们提出了Population Bayesian Transformers (B-Trans),它能够从单个预训练LLM中采样出多样化且连贯的Transformer大型语言模型实例(以下简称“mind”)。B-Trans通过直接将随机性注入到归一化层中,引入了一种受贝叶斯启发的后验代理,避免了训练完整贝叶斯神经网络的过高成本。从这个代理中采样会产生一个具有多样化行为的模型群体,同时保持一般的能力。在生成每个响应期间,我们从随机分布中采样一个单一实现并保持其固定,从而确保时间一致性和推理连贯性。在零样本生成和可验证奖励强化学习(RLVR)上的实验表明,与确定性基线相比,B-Trans有效地利用了随机模型的多样性,从而产生卓越的响应多样性,同时实现了更好的任务性能。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)通常训练成确定性的单一模型,缺乏多样性。这种单一性限制了模型在需要创造性或探索性任务中的表现,例如开放式生成或强化学习中的策略探索。现有方法训练完整贝叶斯神经网络成本过高,难以应用到大型LLM上。
核心思路:B-Trans的核心思路是模拟人类群体智能,即通过多个具有不同“思维”的个体协同工作来解决问题。论文通过在Transformer模型的归一化层中引入随机性,创建一个近似的贝叶斯后验分布,从而可以从中采样出多个不同的模型实例(“minds”)。每个“mind”代表一种不同的参数配置,从而产生不同的行为。
技术框架:B-Trans的技术框架主要包括以下几个步骤:1) 使用预训练的LLM作为基础模型。2) 在模型的归一化层(例如LayerNorm)中引入随机变量,将其参数化为一个可学习的分布(例如高斯分布)。3) 在推理时,从该分布中采样一个随机值,并将其应用于归一化层。4) 对于每个输入,采样一个固定的随机值,以保证生成过程中的时间一致性和推理连贯性。
关键创新:B-Trans的关键创新在于提出了一种轻量级的贝叶斯近似方法,通过在归一化层注入随机性,避免了训练完整贝叶斯神经网络的巨大计算成本。这种方法允许从单个预训练LLM中采样出多个具有不同行为的模型实例,从而实现群体智能。与现有方法相比,B-Trans不需要额外的训练数据或复杂的优化过程。
关键设计:B-Trans的关键设计包括:1) 随机变量的分布选择:论文使用高斯分布来参数化归一化层的参数,并学习其均值和方差。2) 随机变量的采样方式:在生成每个响应时,从高斯分布中采样一个固定的随机值,并将其应用于整个生成过程,以保证时间一致性。3) 损失函数的设计:论文使用标准的语言模型损失函数来训练B-Trans,并添加一个正则化项来鼓励模型的多样性(具体正则化项未知)。
🖼️ 关键图片
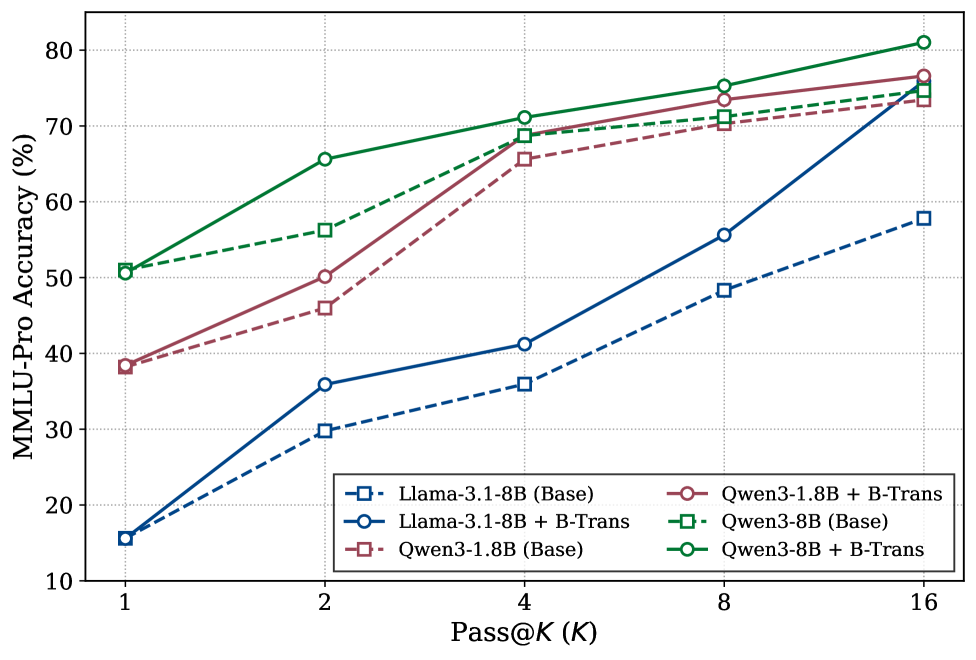
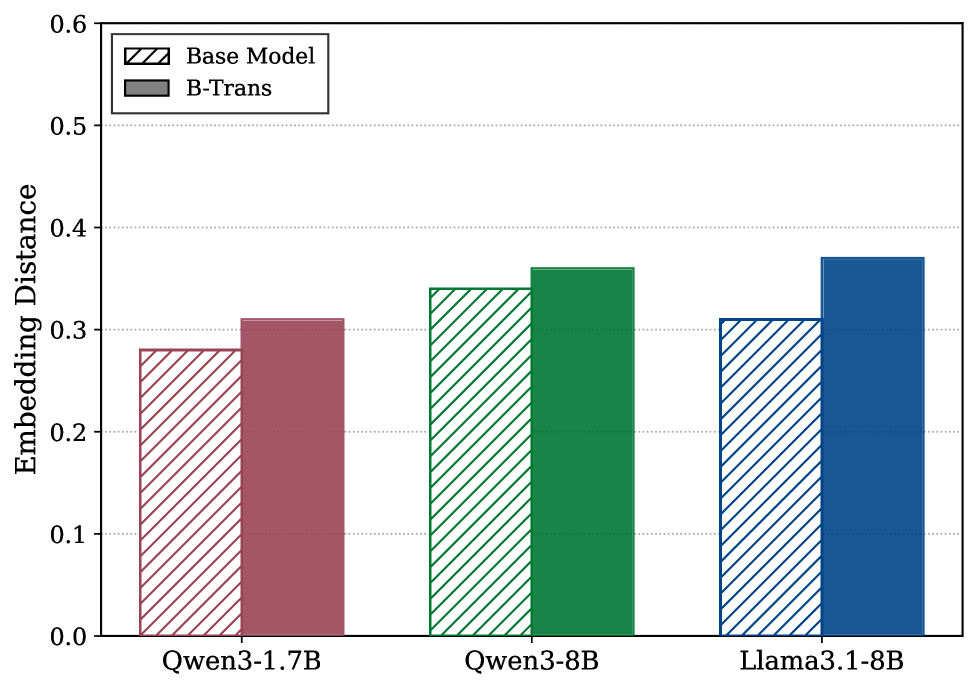
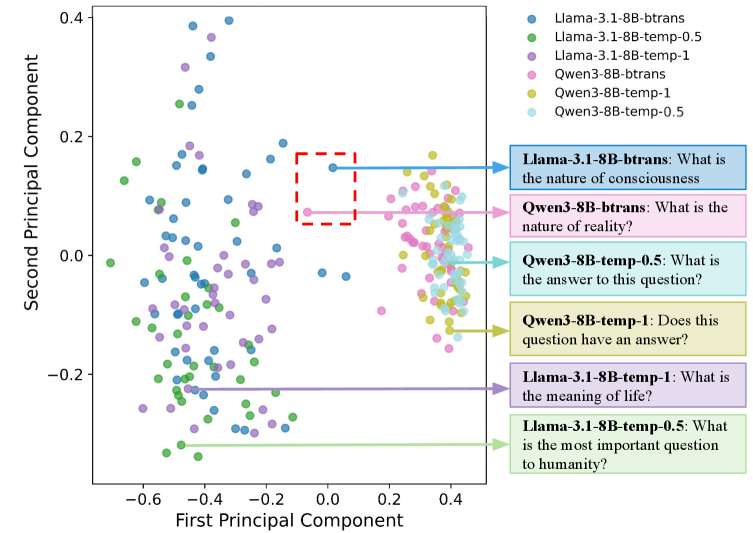
📊 实验亮点
实验结果表明,B-Trans在零样本生成任务中,显著提高了生成文本的多样性,同时保持了较高的生成质量。在可验证奖励强化学习(RLVR)任务中,B-Trans相比于确定性基线,取得了更好的任务性能。具体性能数据未知,但论文强调了B-Trans在多样性和性能上的双重优势。
🎯 应用场景
B-Trans具有广泛的应用前景,例如:1) 开放式文本生成:可以生成更多样化和创造性的文本内容。2) 强化学习:可以用于策略探索,提高强化学习算法的性能。3) 对抗性攻击:可以用于生成更鲁棒的模型,抵抗对抗性攻击。4) 个性化推荐:可以根据用户的不同偏好,生成个性化的推荐结果。未来,B-Trans可以与其他技术结合,例如知识图谱、多模态学习等,进一步提升其性能和应用范围。
📄 摘要(原文)
Despite their scale and success, modern transformers are usually trained as single-minded systems: optimization produces a deterministic set of parameters, representing a single functional hypothesis about the data. Motivated by the analogy to human populations, in which population-level intelligence emerges from diverse individual behaviors, we propose Population Bayesian Transformers (B-Trans), which enable sampling diverse yet coherent transformer large language model instances (hereafter referred to as a 'mind') from a single pre-trained LLM. B-Trans introduces a Bayesian-inspired posterior proxy by injecting stochasticity directly into normalization layers, avoiding the prohibitive cost of training full Bayesian neural networks. Sampling from this proxy yields a population of minds with diverse behaviors while maintaining general competence. During the generation of each response, we sample a single realization from the random distribution and hold it fixed, ensuring temporal consistency and reasoning coherence. Experiments on zero-shot generation and Reinforcement Learning with Verifiable Rewards (RLVR) demonstrate that B-Trans effectively leverages the stochastic model diversity, yielding superior response diversity while achieving better task performance compared to deterministic baselines.