Dynamic Large Concept Models: Latent Reasoning in an Adaptive Semantic Space
作者: Xingwei Qu, Shaowen Wang, Zihao Huang, Kai Hua, Fan Yin, Rui-Jie Zhu, Jundong Zhou, Qiyang Min, Zihao Wang, Yizhi Li, Tianyu Zhang, He Xing, Zheng Zhang, Yuxuan Song, Tianyu Zheng, Zhiyuan Zeng, Chenghua Lin, Ge Zhang, Wenhao Huang
分类: cs.LG, cs.AI
发布日期: 2025-12-31 (更新: 2026-01-05)
💡 一句话要点
提出动态大概念模型(DLCM),通过自适应语义空间中的潜在推理提升LLM效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 动态概念模型 大语言模型 语义边界检测 压缩感知 分层语言建模
📋 核心要点
- 现有LLM对所有token进行统一计算,忽略了语言信息密度不均的问题,导致算力分配不合理。
- DLCM通过学习语义边界,将token压缩到概念空间,并在该空间进行推理,从而更有效地利用计算资源。
- 实验表明,DLCM在固定FLOPs下,通过重新分配计算资源,在多个零样本基准测试中取得了显著的性能提升。
📝 摘要(中文)
大型语言模型(LLM)对所有token应用统一的计算,然而语言的信息密度高度不均匀。这种token统一的模式在局部可预测的跨度上浪费了算力,而对语义关键的转换分配的计算不足。我们提出了动态大概念模型(DLCM),这是一个分层语言建模框架,它从潜在表示中学习语义边界,并将计算从token转移到压缩的概念空间,在概念空间中推理更有效。DLCM端到端地发现变长概念,而不依赖于预定义的语言单元。分层压缩从根本上改变了缩放行为。我们引入了第一个压缩感知缩放定律,它解耦了token级别的容量、概念级别的推理容量和压缩率,从而能够在固定的FLOPs下进行有原则的计算分配。为了稳定地训练这种异构架构,我们进一步开发了一种解耦的μP参数化,它支持跨宽度和压缩方案的零样本超参数迁移。在实际设置(R=4,对应于每个概念平均四个token)中,DLCM将大约三分之一的推理计算重新分配到一个更高容量的推理骨干网络中,在匹配的推理FLOPs下,在12个零样本基准测试中实现了+2.69%的平均改进。
🔬 方法详解
问题定义:现有大型语言模型(LLM)在处理语言时,对所有token采用相同的计算量,没有考虑到语言本身信息密度的差异。这意味着模型在处理冗余或易于预测的token时浪费了计算资源,而在处理语义关键的token时计算资源又不足,从而限制了模型的整体性能。
核心思路:DLCM的核心思想是将token级别的计算转移到概念级别的计算。它通过学习潜在表示中的语义边界,将多个token压缩成一个“概念”,然后在压缩后的概念空间中进行推理。这种做法类似于人类阅读时对文本进行分块理解,从而更高效地提取关键信息。通过这种方式,DLCM能够更有效地利用计算资源,提升模型性能。
技术框架:DLCM包含以下几个主要模块:1) 概念编码器:将输入token序列编码成潜在表示。2) 语义边界检测器:基于潜在表示学习语义边界,将token序列分割成变长的概念。3) 概念压缩器:将每个概念压缩成一个向量表示。4) 推理骨干网络:在压缩后的概念空间中进行推理。整个框架采用端到端的方式进行训练,无需预定义的语言单元。
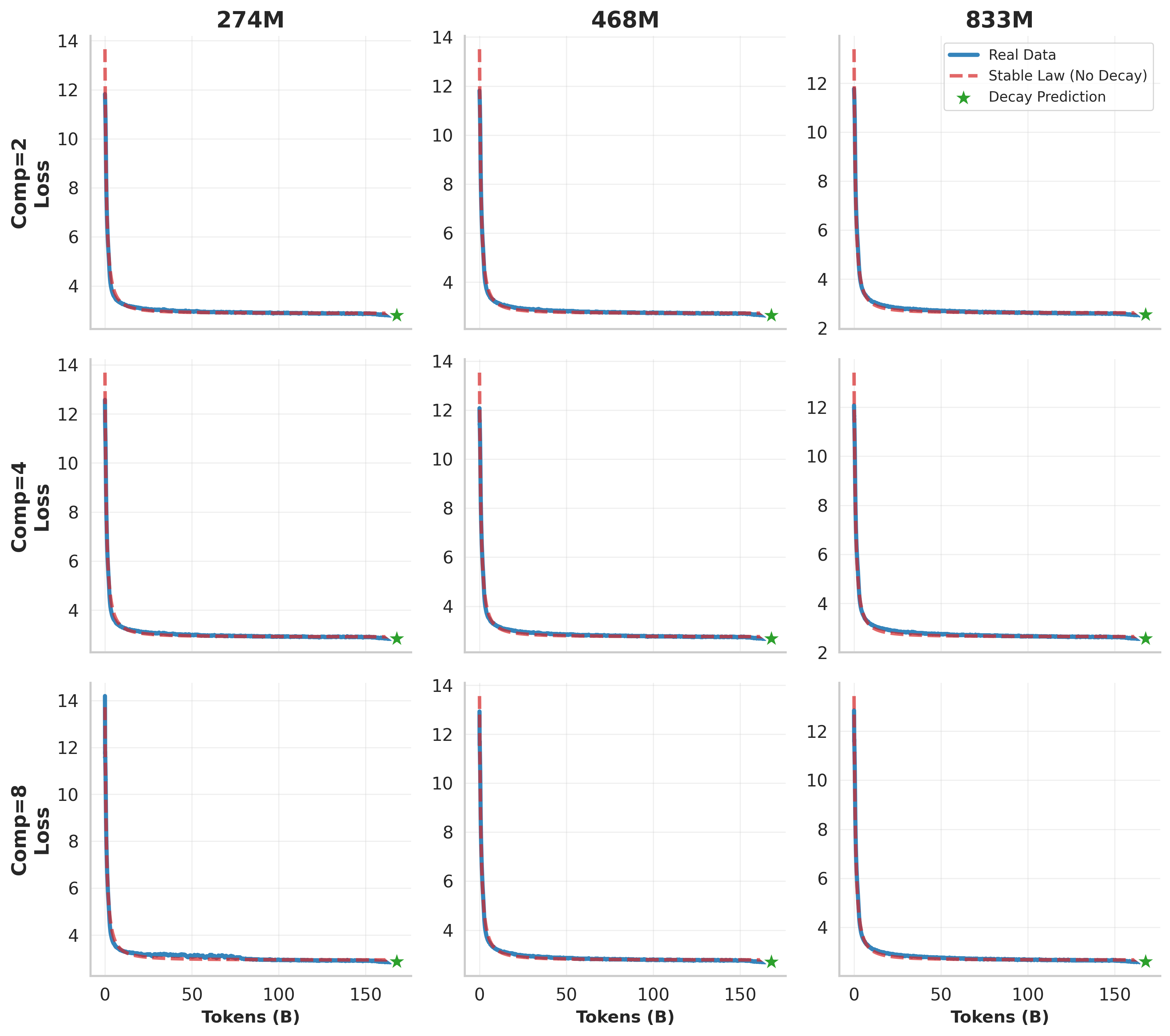
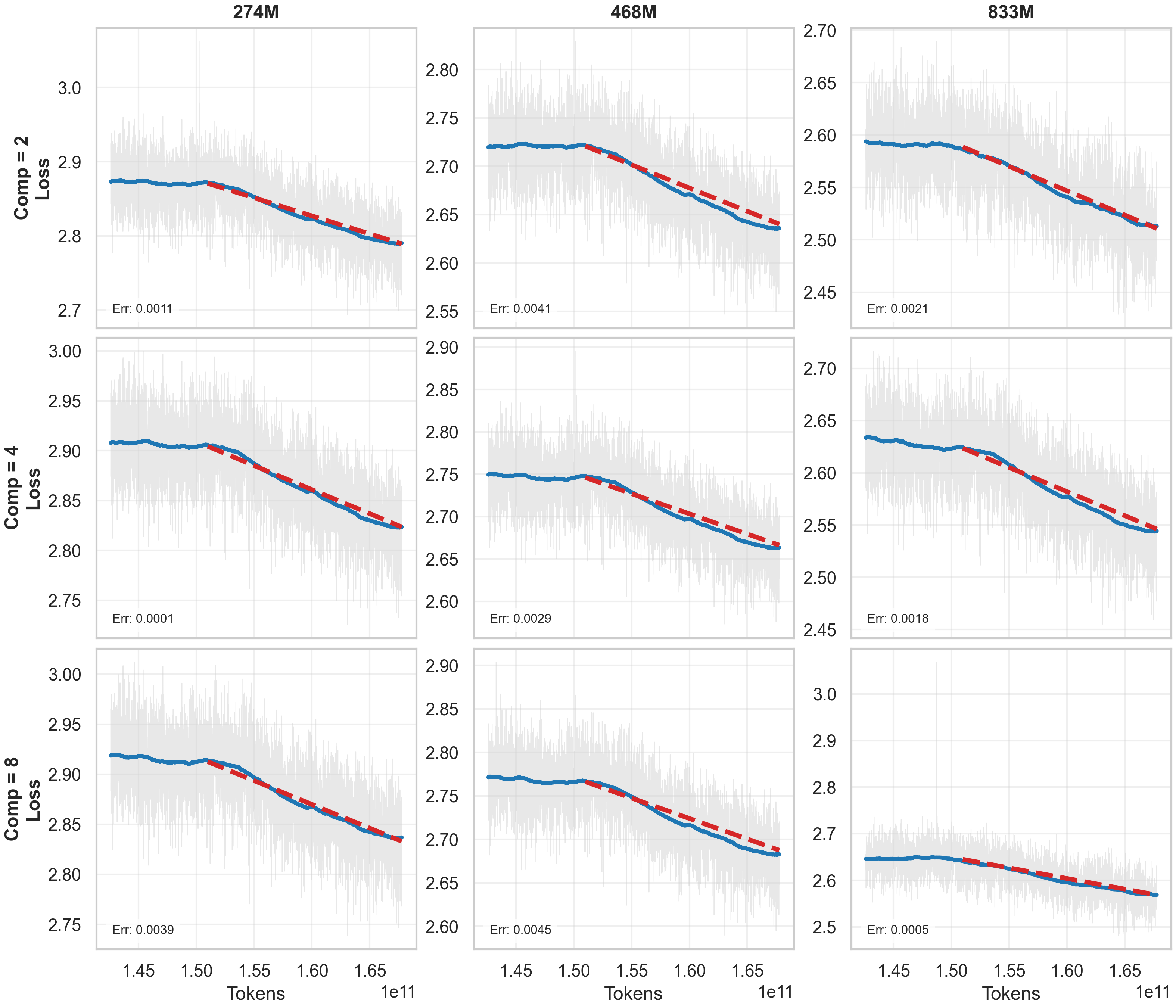
关键创新:DLCM的关键创新在于引入了“动态概念”的概念,并设计了一个能够自适应学习语义边界的框架。与传统的基于固定长度token的LLM不同,DLCM能够根据输入文本的语义信息动态地调整概念的长度,从而更有效地捕捉语言的结构和含义。此外,论文还提出了“压缩感知缩放定律”,用于指导在固定计算资源下如何平衡token级别的容量、概念级别的推理容量和压缩率。
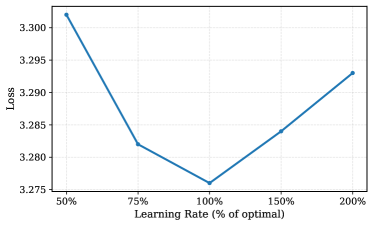
关键设计:DLCM的关键设计包括:1) 使用Transformer架构作为概念编码器和推理骨干网络。2) 使用Gumbel-Softmax技巧进行语义边界的软分割,从而实现端到端的训练。3) 引入解耦的μP参数化,以支持跨宽度和压缩方案的零样本超参数迁移。4) 设计了专门的损失函数,用于鼓励模型学习有意义的语义边界,并提高概念表示的质量。
🖼️ 关键图片
📊 实验亮点
实验结果表明,DLCM在R=4(每个概念平均四个token)的设置下,将大约三分之一的推理计算重新分配到一个更高容量的推理骨干网络中,在12个零样本基准测试中实现了+2.69%的平均性能提升。这一结果表明,DLCM能够有效地利用计算资源,并在各种自然语言处理任务中取得显著的性能提升。
🎯 应用场景
DLCM具有广泛的应用前景,例如可以应用于机器翻译、文本摘要、问答系统等自然语言处理任务中。通过更有效地利用计算资源,DLCM能够提升这些任务的性能,并降低计算成本。此外,DLCM的动态概念学习能力使其能够更好地适应不同领域和语言的特点,从而提高模型的泛化能力。未来,DLCM有望成为构建更高效、更智能的语言模型的重要技术。
📄 摘要(原文)
Large Language Models (LLMs) apply uniform computation to all tokens, despite language exhibiting highly non-uniform information density. This token-uniform regime wastes capacity on locally predictable spans while under-allocating computation to semantically critical transitions. We propose $\textbf{Dynamic Large Concept Models (DLCM)}$, a hierarchical language modeling framework that learns semantic boundaries from latent representations and shifts computation from tokens to a compressed concept space where reasoning is more efficient. DLCM discovers variable-length concepts end-to-end without relying on predefined linguistic units. Hierarchical compression fundamentally changes scaling behavior. We introduce the first $\textbf{compression-aware scaling law}$, which disentangles token-level capacity, concept-level reasoning capacity, and compression ratio, enabling principled compute allocation under fixed FLOPs. To stably train this heterogeneous architecture, we further develop a $\textbf{decoupled $μ$P parametrization}$ that supports zero-shot hyperparameter transfer across widths and compression regimes. At a practical setting ($R=4$, corresponding to an average of four tokens per concept), DLCM reallocates roughly one-third of inference compute into a higher-capacity reasoning backbone, achieving a $\textbf{+2.69$\%$ average improvement}$ across 12 zero-shot benchmarks under matched inference FLOPs.