Robust Bayesian Dynamic Programming for On-policy Risk-sensitive Reinforcement Learning
作者: Shanyu Han, Yangbo He, Yang Liu
分类: q-fin.RM, cs.LG
发布日期: 2025-12-31
备注: 63 pages
💡 一句话要点
提出鲁棒贝叶斯动态规划,用于解决策略风险敏感强化学习中的转移不确定性问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 风险敏感强化学习 鲁棒优化 贝叶斯动态规划 转移不确定性 期权对冲
📋 核心要点
- 现有强化学习方法在处理环境转移概率不确定性时存在不足,可能导致策略在实际应用中表现不佳。
- 论文提出一种鲁棒贝叶斯动态规划框架,通过内外风险度量分别处理状态成本随机性和转移动态不确定性。
- 实验结果表明,该方法具有良好的收敛性,并在风险敏感性和鲁棒性方面优于现有方法,在期权对冲中表现出优势。
📝 摘要(中文)
本文提出了一种新的风险敏感强化学习(RSRL)框架,该框架融合了针对转移不确定性的鲁棒性。我们定义了两个不同但相互关联的风险度量:一个内部风险度量,用于处理状态和成本的随机性;一个外部风险度量,用于捕获转移动态的不确定性。我们的框架通过允许内部和外部风险度量使用一般的相干风险度量,统一并推广了大多数现有的RL框架。在此框架内,我们构建了一个风险敏感的鲁棒马尔可夫决策过程(RSRMDP),推导了其贝尔曼方程,并在给定的后验分布下提供了误差分析。我们进一步开发了一种贝叶斯动态规划(Bayesian DP)算法,该算法在后验更新和值迭代之间交替进行。该方法采用基于风险的贝尔曼算子的估计器,该估计器将蒙特卡洛采样与凸优化相结合,我们证明了其强一致性保证。此外,我们证明了该算法收敛到训练环境中接近最优的策略,并分析了Dirichlet后验和CVaR下的样本复杂度和计算复杂度。最后,我们通过两个数值实验验证了我们的方法。结果显示出优异的收敛特性,同时直观地展示了其在风险敏感性和鲁棒性方面的优势。通过期权对冲的应用,我们进一步从经验上证明了所提出算法的优势。
🔬 方法详解
问题定义:传统的强化学习方法通常假设环境的转移概率是已知的或者可以通过大量采样来精确估计。然而,在实际应用中,环境的转移概率往往存在不确定性,这会导致学习到的策略对环境的变化非常敏感,从而降低策略的鲁棒性和泛化能力。现有的风险敏感强化学习方法通常只考虑状态和成本的随机性,而忽略了转移动态的不确定性。
核心思路:本文的核心思路是将鲁棒优化和贝叶斯动态规划相结合,通过引入内外两层风险度量来同时处理状态成本的随机性和转移动态的不确定性。内层风险度量用于评估给定转移概率下的策略风险,外层风险度量用于评估转移概率不确定性对策略风险的影响。通过最小化外层风险度量,可以得到对转移概率不确定性具有鲁棒性的策略。
技术框架:该方法构建了一个风险敏感的鲁棒马尔可夫决策过程(RSRMDP),并推导了其贝尔曼方程。然后,采用贝叶斯动态规划算法,该算法在后验更新和值迭代之间交替进行。在每次迭代中,首先使用蒙特卡洛采样和凸优化方法来估计基于风险的贝尔曼算子,然后使用值迭代来更新值函数。最后,根据更新后的值函数来选择最优策略。
关键创新:该方法的主要创新点在于:1) 提出了一个统一的框架,可以同时处理状态成本的随机性和转移动态的不确定性;2) 引入了内外两层风险度量,可以灵活地控制策略的风险敏感性和鲁棒性;3) 提出了一个基于蒙特卡洛采样和凸优化的贝尔曼算子估计器,并证明了其强一致性保证。与现有方法相比,该方法可以学习到对环境变化更具有鲁棒性的策略。
关键设计:该方法的关键设计包括:1) 选择合适的内外风险度量,例如CVaR等相干风险度量;2) 设计有效的蒙特卡洛采样策略,以减少贝尔曼算子估计的方差;3) 选择合适的凸优化算法,以高效地求解贝尔曼方程。此外,该方法还分析了Dirichlet后验和CVaR下的样本复杂度和计算复杂度,为算法的实际应用提供了理论指导。
🖼️ 关键图片
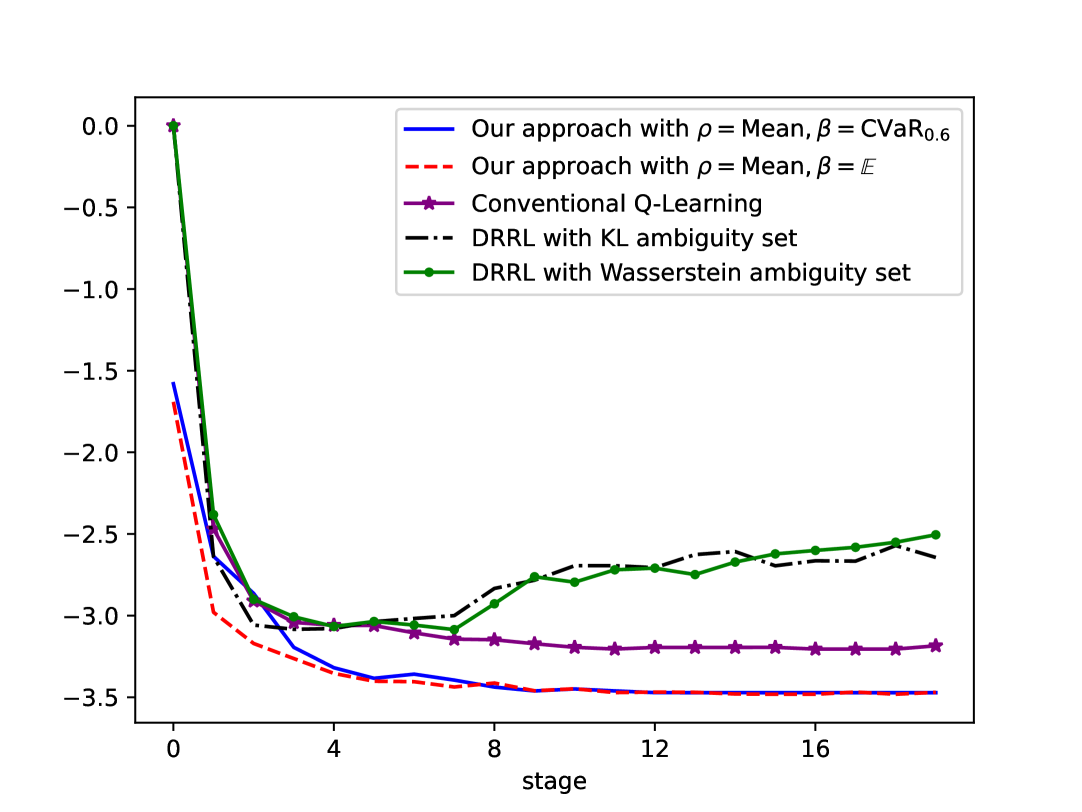
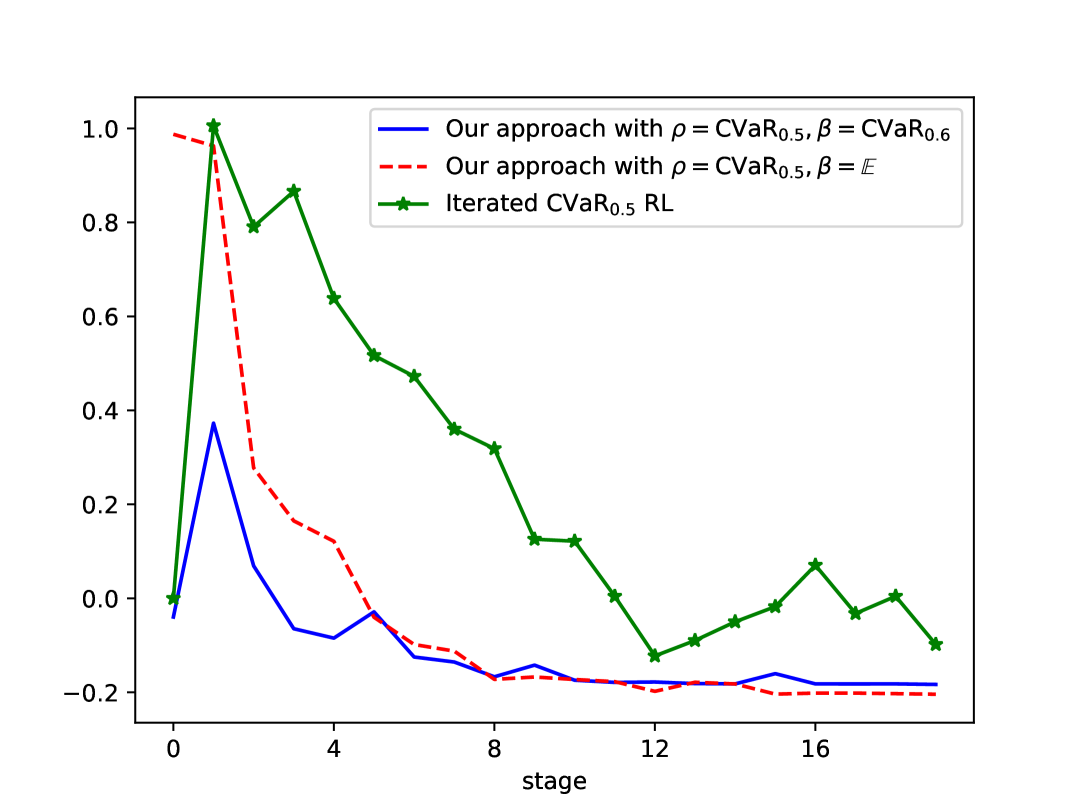
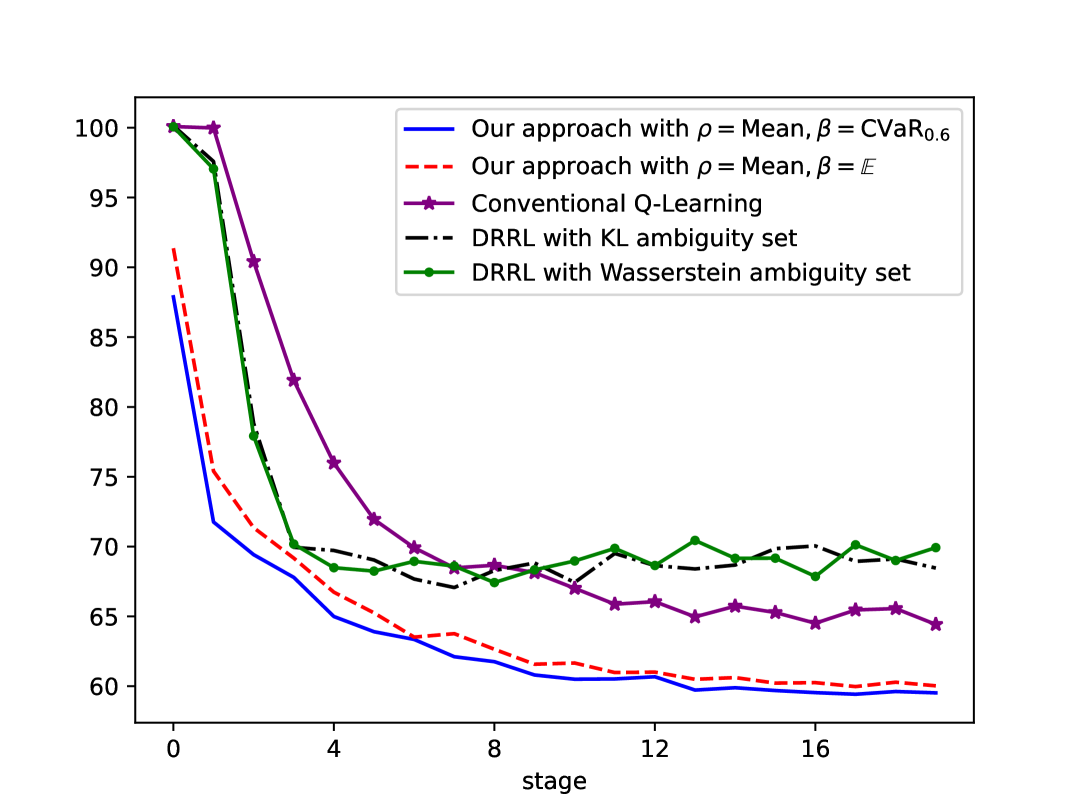
📊 实验亮点
实验结果表明,该方法在数值实验中表现出优异的收敛特性,并在风险敏感性和鲁棒性方面优于现有方法。在期权对冲的应用中,该方法能够有效地降低投资风险,获得更高的收益。具体性能提升数据未知,但实验结果直观地展示了该算法的优势。
🎯 应用场景
该研究成果可应用于金融领域的期权对冲、自动驾驶中的路径规划、机器人控制等对风险和鲁棒性要求较高的场景。通过考虑环境的不确定性,可以提高策略的稳定性和安全性,降低潜在的损失。该方法在智能决策领域具有广泛的应用前景。
📄 摘要(原文)
We propose a novel framework for risk-sensitive reinforcement learning (RSRL) that incorporates robustness against transition uncertainty. We define two distinct yet coupled risk measures: an inner risk measure addressing state and cost randomness and an outer risk measure capturing transition dynamics uncertainty. Our framework unifies and generalizes most existing RL frameworks by permitting general coherent risk measures for both inner and outer risk measures. Within this framework, we construct a risk-sensitive robust Markov decision process (RSRMDP), derive its Bellman equation, and provide error analysis under a given posterior distribution. We further develop a Bayesian Dynamic Programming (Bayesian DP) algorithm that alternates between posterior updates and value iteration. The approach employs an estimator for the risk-based Bellman operator that combines Monte Carlo sampling with convex optimization, for which we prove strong consistency guarantees. Furthermore, we demonstrate that the algorithm converges to a near-optimal policy in the training environment and analyze both the sample complexity and the computational complexity under the Dirichlet posterior and CVaR. Finally, we validate our approach through two numerical experiments. The results exhibit excellent convergence properties while providing intuitive demonstrations of its advantages in both risk-sensitivity and robustness. Empirically, we further demonstrate the advantages of the proposed algorithm through an application on option hedging.