From Perception to Punchline: Empowering VLM with the Art of In-the-wild Meme
作者: Xueyan Li, Yingyi Xue, Mengjie Jiang, Qingzi Zhu, Yazhe Niu
分类: cs.LG
发布日期: 2025-12-31 (更新: 2026-01-17)
备注: 46 pages, 20 figures
💡 一句话要点
提出HUMOR框架,赋能VLM生成更幽默、符合人类偏好的野生表情包
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱六:视频提取与匹配 (Video Extraction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 表情包生成 多模态学习 视觉语言模型 思维链 强化学习 人类偏好对齐 幽默理解
📋 核心要点
- 现有表情包生成方法难以进行细致的视觉内容推理和捕捉主观幽默。
- HUMOR框架通过分层多路径CoT增强推理多样性,并使用成对奖励模型对齐人类偏好。
- 实验表明,HUMOR显著提升了VLM在表情包生成中的推理多样性、偏好对齐和整体质量。
📝 摘要(中文)
生成幽默表情包是一项具有挑战性的多模态任务,它超越了直接的图像到标题的监督。它需要对视觉内容、上下文线索和主观幽默进行细致的推理。为了弥合视觉感知和幽默妙语创作之间的差距,我们提出了HUMOR,这是一个新颖的框架,通过分层推理引导VLM,并使它们与群体人类偏好对齐。首先,HUMOR采用分层的多路径思维链(CoT):模型首先识别模板级别的意图,然后探索不同上下文下的各种推理路径,最后锚定到高质量的、特定于上下文的路径上。这种从真实标题追溯的CoT监督增强了推理多样性。我们进一步分析,在高质量路径保持显著概率质量的实际条件下,这种具有锚定的多路径探索保持了较高的预期幽默质量。其次,为了捕捉主观幽默,我们训练了一个成对奖励模型,该模型在共享相同模板的表情包组内运行。根据既定理论,即使存在主观和嘈杂的标签,这种方法也能确保人类偏好的一致且稳健的代理。然后,奖励模型能够进行群体强化学习优化,从而为信任区域内的单调改进提供理论保证。大量的实验表明,HUMOR赋予了各种VLM卓越的推理多样性、更可靠的偏好对齐和更高的整体表情包质量。除了表情包之外,我们的工作还提出了一种通用的训练范式,用于开放式的、人类对齐的多模态生成,其中成功由连贯输出组内的比较判断来指导。
🔬 方法详解
问题定义:表情包生成任务需要模型理解图像内容、把握上下文,并生成符合人类幽默感和偏好的文字。现有方法通常依赖于直接的图像-文本监督,缺乏对视觉内容的细致推理能力,难以捕捉主观幽默,生成的表情包质量不高,与人类偏好存在偏差。
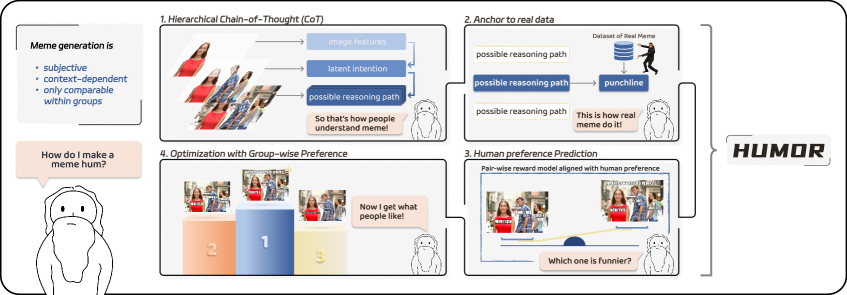
核心思路:HUMOR框架的核心在于通过分层多路径的思维链(Chain-of-Thought, CoT)来引导VLM进行更深入的推理,并利用成对奖励模型来学习和对齐人类的主观偏好。这种方法旨在弥合视觉感知和幽默妙语创作之间的差距,使模型能够生成更符合人类期望的表情包。
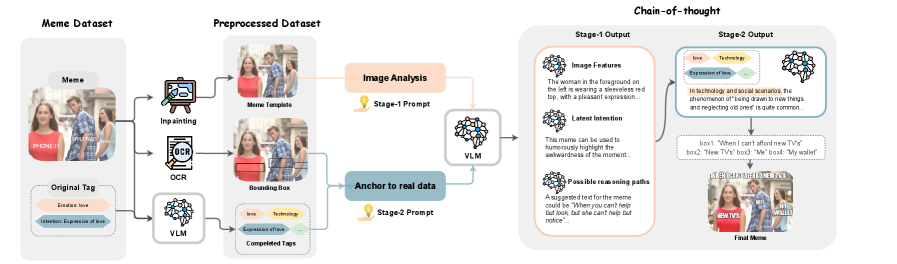
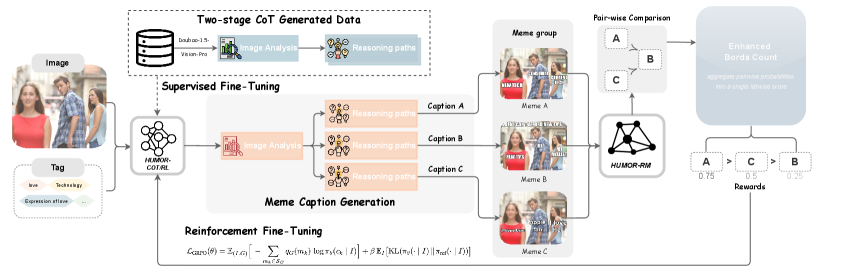
技术框架:HUMOR框架包含两个主要组成部分:分层多路径CoT和成对奖励模型。首先,模型通过分层CoT识别模板级别的意图,并探索不同上下文下的多种推理路径,最终选择高质量的路径生成文本。然后,成对奖励模型在共享相同模板的表情包组内进行训练,学习人类对不同表情包的偏好。最后,利用奖励模型进行群体强化学习优化,提升模型生成表情包的质量。
关键创新:HUMOR的关键创新在于:1) 提出了分层多路径CoT,增强了VLM的推理多样性,使其能够探索不同的上下文和表达方式;2) 使用成对奖励模型,能够更好地捕捉主观幽默,并对齐人类偏好;3) 采用群体强化学习优化,保证了在信任区域内的单调改进。
关键设计:在分层CoT中,模型首先识别表情包的模板类型,然后根据模板生成多个候选文本,并根据上下文选择最佳文本。成对奖励模型使用Transformer架构,输入为两个表情包(图像和文本),输出为偏好得分。群体强化学习使用PPO算法,奖励函数基于成对奖励模型的输出,目标是最大化生成表情包的平均奖励。
🖼️ 关键图片
📊 实验亮点
实验结果表明,HUMOR框架显著提升了VLM在表情包生成任务中的性能。与现有方法相比,HUMOR生成的表情包在推理多样性、偏好对齐和整体质量方面均有显著提升。具体而言,HUMOR在多个指标上取得了SOTA结果,证明了其有效性。
🎯 应用场景
该研究提出的HUMOR框架不仅可以应用于表情包生成,还可以推广到其他开放式的、人类对齐的多模态生成任务中,例如故事创作、广告文案生成等。通过学习人类偏好和进行分层推理,可以使模型生成更符合人类期望的内容,具有广泛的应用前景。
📄 摘要(原文)
Generating humorous memes is a challenging multimodal task that moves beyond direct image-to-caption supervision. It requires a nuanced reasoning over visual content, contextual cues, and subjective humor. To bridge this gap between visual perception and humorous punchline creation, we propose HUMOR}, a novel framework that guides VLMs through hierarchical reasoning and aligns them with group-wise human preferences. First, HUMOR employs a hierarchical, multi-path Chain-of-Thought (CoT): the model begins by identifying a template-level intent, then explores diverse reasoning paths under different contexts, and finally anchors onto a high-quality, context-specific path. This CoT supervision, which traces back from ground-truth captions, enhances reasoning diversity. We further analyze that this multi-path exploration with anchoring maintains a high expected humor quality, under the practical condition that high-quality paths retain significant probability mass. Second, to capture subjective humor, we train a pairwise reward model that operates within groups of memes sharing the same template. Following established theory, this approach ensures a consistent and robust proxy for human preference, even with subjective and noisy labels. The reward model then enables a group-wise reinforcement learning optimization, guaranteeing providing a theoretical guarantee for monotonic improvement within the trust region. Extensive experiments show that HUMOR empowers various VLMs with superior reasoning diversity, more reliable preference alignment, and higher overall meme quality. Beyond memes, our work presents a general training paradigm for open-ended, human-aligned multimodal generation, where success is guided by comparative judgment within coherent output group.