GRADE: Replacing Policy Gradients with Backpropagation for LLM Alignment
作者: Lukas Abrie Nel
分类: cs.LG, cs.AI
发布日期: 2025-12-30
💡 一句话要点
GRADE:用反向传播替代策略梯度,实现LLM对齐
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM对齐 强化学习 反向传播 Gumbel-Softmax 可微估计 文本生成 策略梯度 梯度方差
📋 核心要点
- RLHF依赖策略梯度方法,但其高方差梯度估计导致训练不稳定和计算成本高昂。
- GRADE通过Gumbel-Softmax重参数化,将离散token采样转化为可微操作,实现直接反向传播。
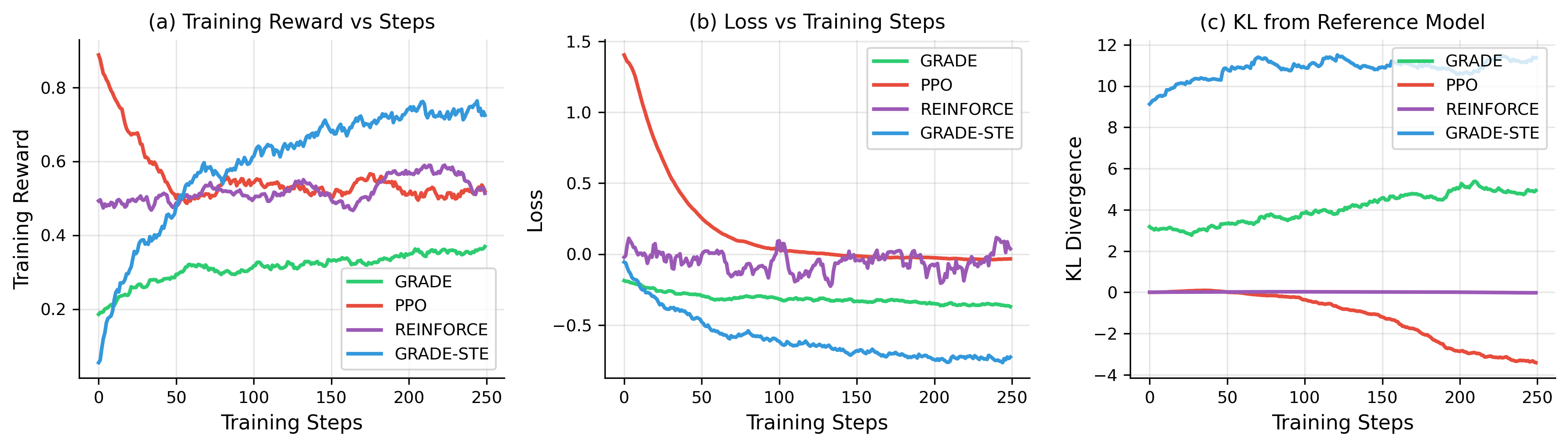
- 实验表明,GRADE在情感控制文本生成任务上显著优于PPO和REINFORCE,且梯度方差更低。
📝 摘要(中文)
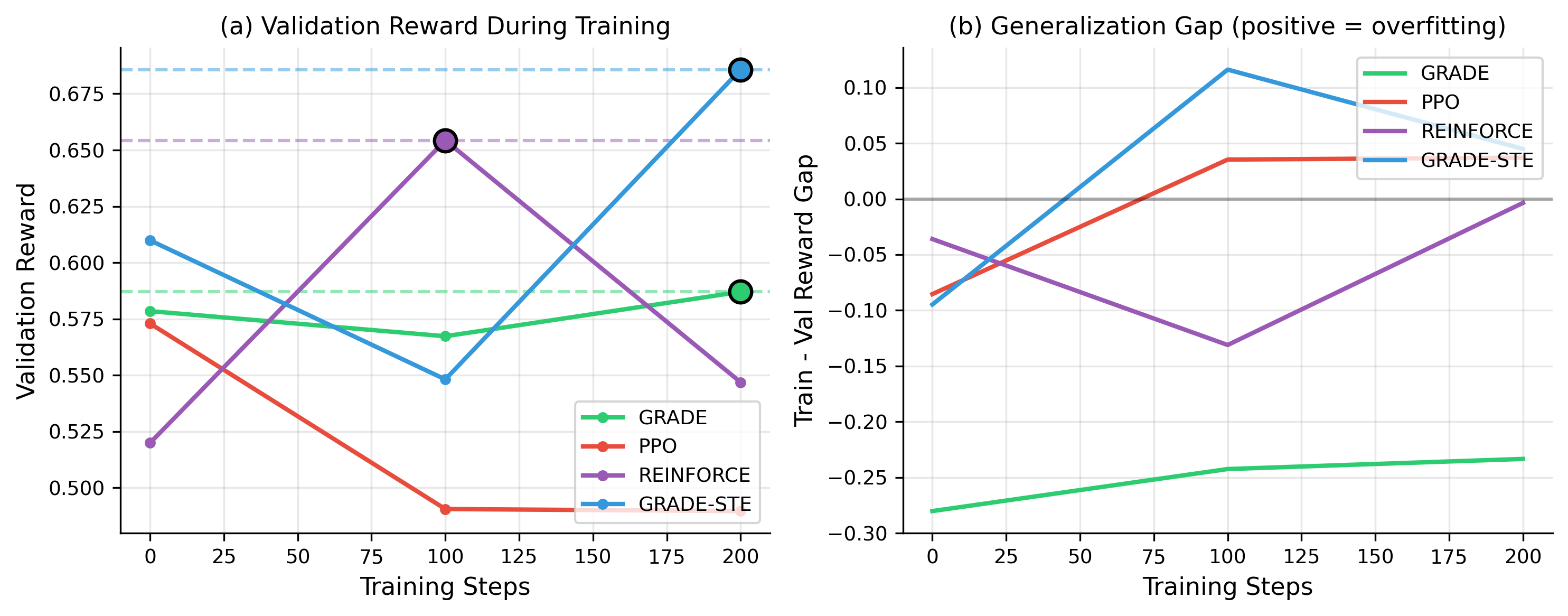
从人类反馈中进行强化学习(RLHF)已成为将大型语言模型与人类偏好对齐的主导范式。然而,诸如PPO之类的策略梯度方法受到高方差梯度估计的影响,需要仔细的超参数调整和大量的计算资源。我们引入了GRADE(通过可微估计进行对齐的Gumbel-softmax松弛),该方法用直接反向传播通过离散token采样过程的可微松弛来代替高方差策略梯度估计。使用带有直通估计的Gumbel-Softmax重参数化(GRADE-STE),我们实现了从奖励信号通过生成的token到模型参数的端到端梯度流。在使用IMDB数据集的情感控制文本生成中,GRADE-STE实现了0.763 +- 0.344的测试奖励,而PPO为0.510 +- 0.313,REINFORCE为0.617 +- 0.378,相对于PPO提高了50%。至关重要的是,GRADE-STE的梯度方差比REINFORCE低14倍以上,并在整个优化过程中保持稳定的训练动态。我们使用适当的训练/验证/测试分割进行的严格评估表明,这些改进推广到保留数据,GRADE-STE显示了所有测试方法中最佳的泛化特性。GRADE为LLM对齐提供了一种更简单、更稳定、更有效的强化学习替代方案。
🔬 方法详解
问题定义:现有RLHF方法,如PPO,在对齐大型语言模型时,由于策略梯度估计的高方差,面临训练不稳定、超参数敏感和计算资源需求大的问题。这限制了RLHF的效率和可扩展性。
核心思路:GRADE的核心在于使用Gumbel-Softmax重参数化技巧,将原本离散的token采样过程转化为一个连续且可微的操作。这样,就可以直接通过反向传播来优化模型,避免了策略梯度估计带来的高方差问题。
技术框架:GRADE方法主要包含以下几个阶段:1. 使用LLM生成文本;2. 使用奖励模型评估生成文本的质量;3. 使用Gumbel-Softmax重参数化对token采样过程进行可微近似;4. 通过反向传播,根据奖励信号直接更新LLM的参数。整个过程是端到端可微的。
关键创新:GRADE最重要的创新在于用可微的Gumbel-Softmax松弛取代了传统的策略梯度估计。这使得可以直接通过反向传播来优化LLM,避免了策略梯度方法固有的高方差问题。与现有方法相比,GRADE无需复杂的策略梯度估计和方差缩减技巧。
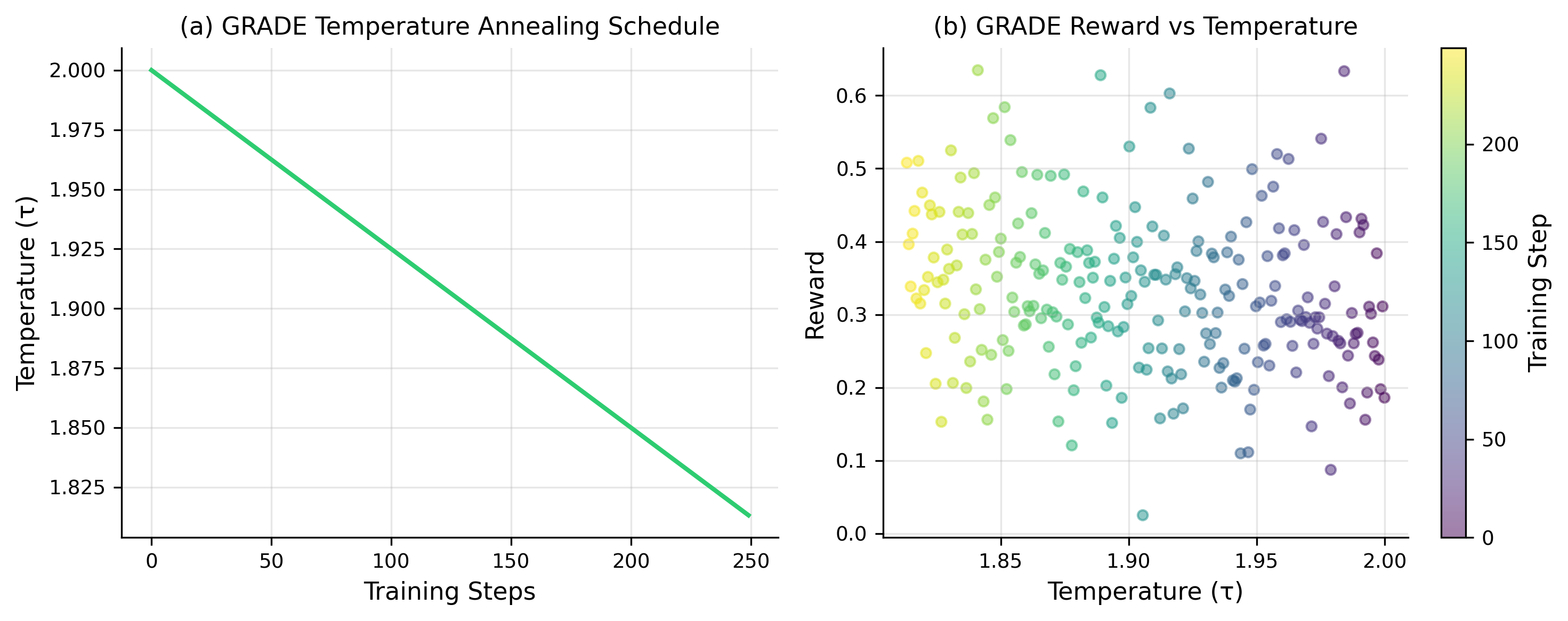
关键设计:GRADE的关键设计包括:1. 使用Gumbel-Softmax分布来近似离散的token分布,温度参数控制近似程度;2. 使用直通估计(Straight-Through Estimation, STE)来保证梯度能够有效地传递到离散的token选择过程;3. 奖励函数的设计直接影响对齐效果,需要根据具体任务进行调整。
🖼️ 关键图片
📊 实验亮点
GRADE-STE在IMDB数据集上的情感控制文本生成任务中,取得了显著的性能提升。其测试奖励达到0.763 +- 0.344,相比于PPO的0.510 +- 0.313和REINFORCE的0.617 +- 0.378,分别提升了50%和23%。更重要的是,GRADE-STE的梯度方差比REINFORCE低14倍以上,训练过程更加稳定。
🎯 应用场景
GRADE方法可广泛应用于需要将LLM与人类偏好或特定目标对齐的场景,例如:对话系统、文本摘要、代码生成等。它降低了对齐过程的复杂性和计算成本,使得LLM能够更好地满足用户需求,并有望加速LLM在各个领域的应用。
📄 摘要(原文)
Reinforcement learning from human feedback (RLHF) has become the dominant paradigm for aligning large language models with human preferences. However, policy gradient methods such as PPO suffer from high variance gradient estimates, requiring careful hyperparameter tuning and extensive computational resources. We introduce GRADE (Gumbel-softmax Relaxation for Alignment via Differentiable Estimation), a method that replaces high-variance policy gradient estimation with direct backpropagation through a differentiable relaxation of the discrete token sampling process. Using the Gumbel-Softmax reparameterization with straight-through estimation (GRADE-STE), we enable end-to-end gradient flow from reward signals through generated tokens to model parameters. On sentiment-controlled text generation using the IMDB dataset, GRADE-STE achieves a test reward of 0.763 +- 0.344 compared to PPO's 0.510 +- 0.313 and REINFORCE's 0.617 +- 0.378, representing a 50% relative improvement over PPO. Critically, GRADE-STE exhibits gradient variance over 14 times lower than REINFORCE and maintains stable training dynamics throughout optimization. Our rigorous evaluation with proper train/validation/test splits demonstrates that these improvements generalize to held-out data, with GRADE-STE showing the best generalization characteristics among all methods tested. GRADE offers a simpler, more stable, and more effective alternative to reinforcement learning for LLM alignment.