OptRot: Mitigating Weight Outliers via Data-Free Rotations for Post-Training Quantization
作者: Advait Gadhikar, Riccardo Grazzi, James Hensman
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-12-30 (更新: 2026-01-12)
备注: 25 pages, 10 figures
💡 一句话要点
OptRot:通过免数据旋转缓解权重异常值,用于训练后量化
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 训练后量化 权重量化 异常值缓解 旋转优化 大型语言模型
📋 核心要点
- 大型语言模型量化面临权重和激活中异常值的挑战,现有方法量化精度受限。
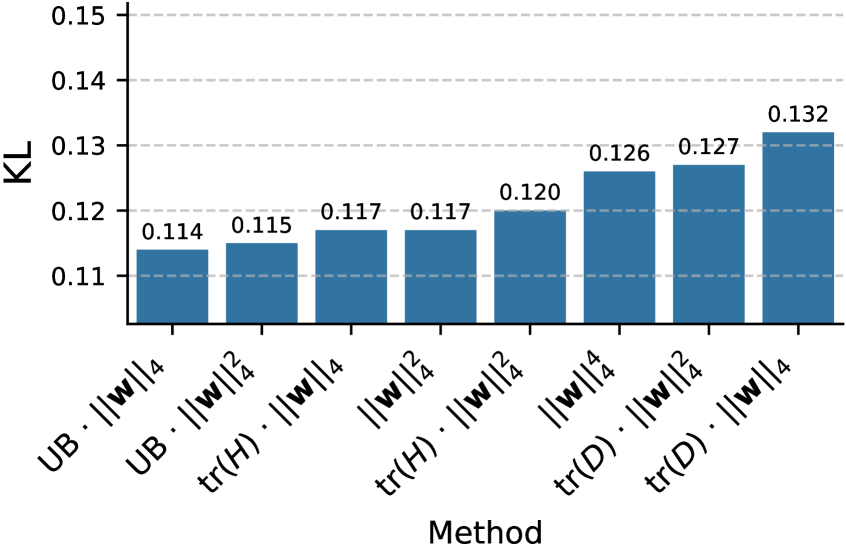
- OptRot通过最小化旋转后权重的四次方来减少异常值,无需数据即可学习可融合的旋转。
- 实验表明,OptRot在权重量化方面优于现有方法,并在W4A8设置中改进了激活量化。
📝 摘要(中文)
大型语言模型(LLM)权重和激活中异常值的存在使其难以量化。最近的研究利用旋转来缓解这些异常值。本文提出了一种方法,通过最小化基于原则且计算成本低的代理目标函数来学习可融合的旋转,从而降低权重量化误差。我们主要关注GPTQ作为量化方法。我们的主要方法是OptRot,它通过简单地最小化旋转后权重的逐元素四次方来减少权重异常值。实验表明,对于权重量化,OptRot优于Hadamard旋转和更昂贵、依赖于数据的方法,如SpinQuant和OSTQuant。它还在W4A8设置中改进了激活量化。我们还提出了一种依赖于数据的方法OptRot$^{+}$,通过结合激活协方差信息来进一步提高性能。在W4A4设置中,OptRot和OptRot$^{+}$的性能都较差,突出了权重和激活量化之间的权衡。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)训练后量化过程中,由于权重和激活中存在异常值而导致的量化精度下降问题。现有的量化方法难以有效处理这些异常值,导致量化后的模型性能显著降低。
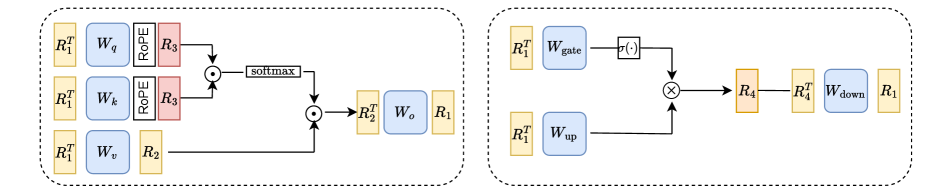
核心思路:论文的核心思路是通过学习可融合的旋转矩阵,将权重分布进行变换,从而减少异常值的数量和幅度。具体而言,通过最小化旋转后权重的逐元素四次方,可以有效地抑制权重中的极端值,使其更易于量化。这种方法无需依赖训练数据,降低了计算成本和数据依赖性。
技术框架:OptRot方法主要包含以下几个阶段:1) 对模型的权重进行初始化;2) 使用优化的目标函数(例如,旋转后权重的四次方)学习旋转矩阵;3) 将学习到的旋转矩阵应用于权重;4) 使用GPTQ等量化方法对旋转后的权重进行量化。OptRot$^{+}$方法在OptRot的基础上,进一步考虑了激活的协方差信息,以更精确地调整旋转矩阵。
关键创新:OptRot的关键创新在于提出了一种数据无关的旋转学习方法,通过最小化旋转后权重的四次方来减少异常值。与现有的数据依赖方法相比,OptRot具有更低的计算成本和更强的通用性。OptRot$^{+}$则通过引入激活协方差信息,进一步提高了旋转的精度。
关键设计:OptRot的关键设计在于目标函数的选择。最小化旋转后权重的四次方能够有效地抑制异常值,同时保持权重的整体分布。此外,论文还研究了不同的旋转矩阵初始化方法和优化算法,以提高旋转学习的效率和稳定性。OptRot$^{+}$的关键在于如何有效地利用激活协方差信息来调整旋转矩阵,以实现更好的权重和激活量化平衡。
🖼️ 关键图片

📊 实验亮点
OptRot在权重量化方面优于Hadamard旋转以及SpinQuant和OSTQuant等数据依赖方法。在W4A8设置下,OptRot还提升了激活量化效果。虽然在W4A4设置下表现略有下降,但整体而言,OptRot提供了一种高效且有效的方法来缓解量化中的异常值问题。
🎯 应用场景
该研究成果可应用于各种需要对大型语言模型进行压缩和加速的场景,例如移动设备、边缘计算和资源受限的服务器。通过降低模型的大小和计算复杂度,OptRot可以使LLMs在这些平台上更高效地运行,从而推动人工智能技术的普及和应用。
📄 摘要(原文)
The presence of outliers in Large Language Models (LLMs) weights and activations makes them difficult to quantize. Recent work has leveraged rotations to mitigate these outliers. In this work, we propose methods that learn fusible rotations by minimizing principled and cheap proxy objectives to the weight quantization error. We primarily focus on GPTQ as the quantization method. Our main method is OptRot, which reduces weight outliers simply by minimizing the element-wise fourth power of the rotated weights. We show that OptRot outperforms both Hadamard rotations and more expensive, data-dependent methods like SpinQuant and OSTQuant for weight quantization. It also improves activation quantization in the W4A8 setting. We also propose a data-dependent method, OptRot$^{+}$, that further improves performance by incorporating information on the activation covariance. In the W4A4 setting, we see that both OptRot and OptRot$^{+}$ perform worse, highlighting a trade-off between weight and activation quantization.