How and Why LLMs Generalize: A Fine-Grained Analysis of LLM Reasoning from Cognitive Behaviors to Low-Level Patterns
作者: Haoyue Bai, Yiyou Sun, Wenjie Hu, Shi Qiu, Maggie Ziyu Huan, Peiyang Song, Robert Nowak, Dawn Song
分类: cs.LG
发布日期: 2025-12-30
💡 一句话要点
提出细粒度LLM推理基准,揭示SFT与RL微调泛化能力差异的深层原因
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 泛化能力 监督微调 强化学习 推理基准 认知能力 元学习
📋 核心要点
- 现有研究缺乏对LLM泛化能力差异的细粒度分析,主要依赖于粗略的准确性指标,难以揭示深层原因。
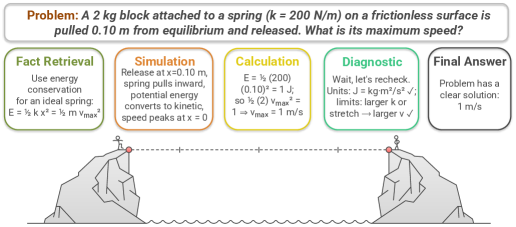
- 论文提出一种新的基准,将推理分解为原子核心技能,并结合低级统计模式分析,以细粒度地研究泛化演变。
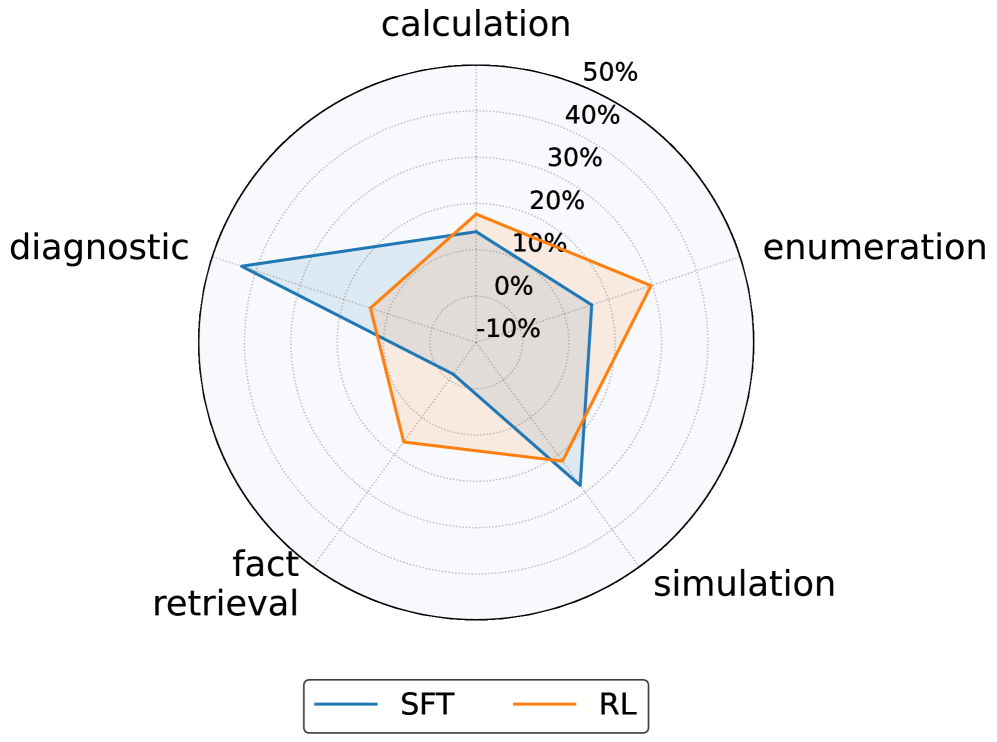
- 实验表明,RL微调模型保持更稳定的行为特征,抵抗推理技能崩溃,而SFT模型更容易过拟合表面模式。
📝 摘要(中文)
大型语言模型(LLMs)表现出显著不同的泛化行为:监督微调(SFT)通常会缩小能力范围,而强化学习(RL)微调则倾向于保持能力。这种差异背后的原因尚不清楚,因为之前的研究主要依赖于粗略的准确性指标。为了弥补这一差距,我们引入了一个新的基准,将推理分解为原子核心技能,如计算、事实检索、模拟、枚举和诊断,为解决LLM推理的根本问题提供了一个具体的框架。通过隔离和测量这些核心技能,该基准提供了更细粒度的视角,观察特定认知能力如何在后训练期间出现、转移,有时甚至崩溃。结合对低级统计模式(如分布差异和参数统计)的分析,可以对SFT和RL在数学、科学推理和非推理任务中的泛化演变进行细粒度研究。我们的元探测框架跟踪模型在不同训练阶段的行为,揭示了RL调整的模型保持更稳定的行为特征,并抵抗推理技能的崩溃,而SFT模型表现出更明显的漂移并过度拟合表面模式。这项工作为LLM推理的本质提供了新的见解,并为设计培养广泛、稳健泛化的训练策略指明了方向。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在监督微调(SFT)和强化学习(RL)微调后表现出不同泛化行为的问题。现有方法主要依赖于粗略的准确性指标,无法深入理解SFT和RL微调对LLM推理能力的影响,以及导致泛化能力差异的根本原因。现有方法缺乏对LLM推理过程的细粒度分析,难以揭示模型在不同训练阶段认知能力的变化。
核心思路:论文的核心思路是通过构建一个细粒度的推理基准,将复杂的推理过程分解为原子核心技能,如计算、事实检索、模拟、枚举和诊断。通过隔离和测量这些核心技能,可以更清晰地观察特定认知能力在训练过程中的演变。同时,结合对低级统计模式(如分布差异和参数统计)的分析,可以深入理解SFT和RL微调对LLM泛化能力的影响。
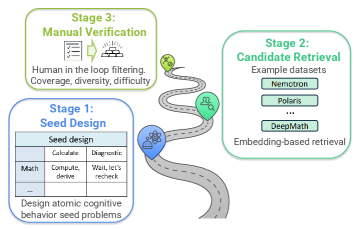
技术框架:论文的技术框架主要包括以下几个部分:1) 构建细粒度的推理基准,将推理任务分解为原子核心技能;2) 设计元探测框架,跟踪模型在不同训练阶段的行为;3) 分析低级统计模式,如分布差异和参数统计;4) 对比SFT和RL微调模型在不同任务上的泛化表现。整体流程是:首先使用基准测试不同训练阶段的模型,然后分析模型的行为和统计模式,最后得出关于SFT和RL微调对LLM泛化能力影响的结论。
关键创新:论文最重要的技术创新点在于提出了一个细粒度的推理基准,能够将复杂的推理过程分解为原子核心技能。与现有方法相比,该基准能够提供更细粒度的视角,观察特定认知能力在训练过程中的演变。此外,结合对低级统计模式的分析,可以更深入地理解SFT和RL微调对LLM泛化能力的影响。该基准为研究LLM推理的本质提供了一个具体的框架。
关键设计:论文的关键设计包括:1) 原子核心技能的选取,需要覆盖LLM推理过程中的关键认知能力;2) 元探测框架的设计,需要能够准确跟踪模型在不同训练阶段的行为;3) 低级统计模式的分析方法,需要能够揭示SFT和RL微调对模型参数和分布的影响。论文还详细描述了如何设计数学、科学推理和非推理任务,以及如何评估模型在这些任务上的表现。
🖼️ 关键图片
📊 实验亮点
实验结果表明,RL微调的模型在推理技能方面表现出更强的稳定性,能够抵抗技能崩溃,而SFT模型则更容易出现漂移和过拟合。通过元探测框架,论文能够跟踪模型在不同训练阶段的行为,并揭示SFT和RL微调对模型认知能力的不同影响。这些发现为设计更有效的LLM训练策略提供了重要的指导。
🎯 应用场景
该研究成果可应用于提升大型语言模型的泛化能力和鲁棒性,尤其是在需要复杂推理的任务中。通过理解SFT和RL微调对模型认知能力的影响,可以设计更有效的训练策略,避免模型过拟合表面模式,从而提高模型在实际应用中的性能。此外,该研究提出的细粒度推理基准可以作为评估和比较不同LLM推理能力的工具。
📄 摘要(原文)
Large Language Models (LLMs) display strikingly different generalization behaviors: supervised fine-tuning (SFT) often narrows capability, whereas reinforcement-learning (RL) tuning tends to preserve it. The reasons behind this divergence remain unclear, as prior studies have largely relied on coarse accuracy metrics. We address this gap by introducing a novel benchmark that decomposes reasoning into atomic core skills such as calculation, fact retrieval, simulation, enumeration, and diagnostic, providing a concrete framework for addressing the fundamental question of what constitutes reasoning in LLMs. By isolating and measuring these core skills, the benchmark offers a more granular view of how specific cognitive abilities emerge, transfer, and sometimes collapse during post-training. Combined with analyses of low-level statistical patterns such as distributional divergence and parameter statistics, it enables a fine-grained study of how generalization evolves under SFT and RL across mathematical, scientific reasoning, and non-reasoning tasks. Our meta-probing framework tracks model behavior at different training stages and reveals that RL-tuned models maintain more stable behavioral profiles and resist collapse in reasoning skills, whereas SFT models exhibit sharper drift and overfit to surface patterns. This work provides new insights into the nature of reasoning in LLMs and points toward principles for designing training strategies that foster broad, robust generalization.