Implicit geometric regularization in flow matching via density weighted Stein operators
作者: Shinto Eguchi
分类: stat.ML, cs.LG
发布日期: 2025-12-30
💡 一句话要点
提出γ-Flow Matching,通过密度加权Stein算子实现Flow Matching的几何正则化。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: Flow Matching 连续归一化流 密度加权 几何正则化 Stein算子 生成模型 高维数据
📋 核心要点
- 标准Flow Matching在高维空间中存在效率问题,因其在低密度区域的目标速度场不稳定。
- γ-Flow Matching通过动态密度加权策略,降低低密度区域的回归损失,优化回归几何。
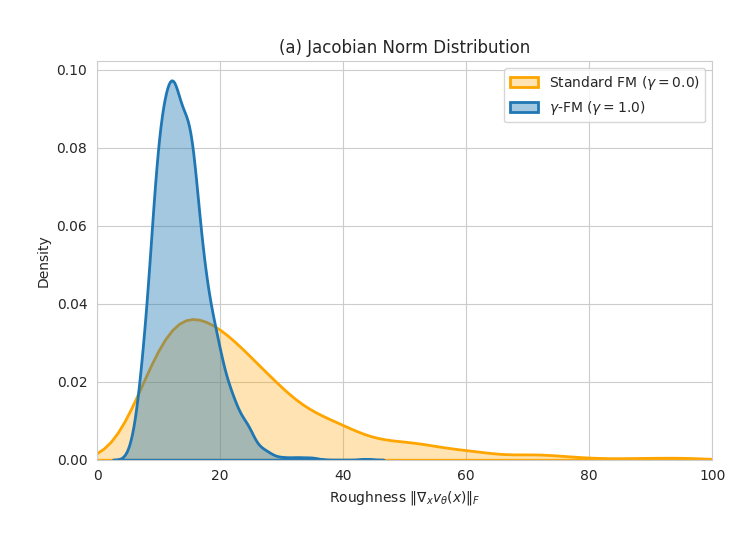
- 实验结果表明,γ-FM能有效提高向量场平滑度和采样效率,并对异常值具有鲁棒性。
📝 摘要(中文)
Flow Matching (FM) 作为一种强大的连续归一化流范式,但标准FM隐式地在整个环境空间上执行一个未加权的L^2回归。在高维空间中,这导致了一个根本性的低效:大部分积分域由低密度“空隙”区域组成,目标速度场通常是混乱或不明确的。本文提出了{γ-Flow Matching (γ-FM)},一种密度加权变体,它将回归几何与底层概率流对齐。虽然密度加权是理想的,但朴素的实现需要评估难以处理的目标密度。我们通过引入一种动态密度加权策略来规避这个问题,该策略直接从训练粒子中估计目标密度。这种方法允许我们动态地降低空隙区域中的回归损失,而不影响FM的无模拟性质。理论上,我们证明了γ-FM最小化了在赋予γ-Stein度量的统计流形上的传输成本。谱分析进一步表明,这种几何结构诱导了一种隐式的Sobolev正则化,有效地抑制了空隙区域中的高频振荡。实验表明,γ-FM显著提高了高维潜在数据集上的向量场平滑度和采样效率,同时表现出对异常值的内在鲁棒性。
🔬 方法详解
问题定义:Flow Matching (FM) 在高维空间中,由于数据分布不均匀,存在大量低密度区域。在这些区域,目标速度场往往是混乱或不明确的,导致模型训练不稳定和采样效率低下。标准FM方法在整个空间上执行未加权的L2回归,未能有效区分数据密度,导致在低密度区域浪费计算资源,并可能引入噪声。
核心思路:γ-Flow Matching (γ-FM) 的核心思路是引入密度加权机制,对高密度区域赋予更高的权重,对低密度区域赋予更低的权重。通过这种方式,模型可以更加关注数据分布的主要区域,减少低密度区域的噪声干扰,从而提高训练稳定性和采样效率。关键在于如何估计目标密度,避免直接计算难以处理的密度函数。
技术框架:γ-FM的技术框架主要包括以下几个步骤:1) 使用Flow Matching的基本框架生成速度场;2) 引入动态密度加权策略,从训练粒子中估计目标密度;3) 使用估计的密度对回归损失进行加权,降低低密度区域的损失贡献;4) 通过优化加权后的损失函数来训练模型。整体流程与标准FM类似,但核心在于动态密度加权模块的引入。
关键创新:γ-FM最重要的技术创新点在于动态密度加权策略。该策略无需显式计算目标密度,而是通过训练数据动态估计密度。这种方法避免了直接计算复杂密度函数的难题,使得密度加权方法可以在高维空间中有效应用。此外,理论分析表明,γ-FM最小化了在γ-Stein度量下的传输成本,并诱导了一种隐式的Sobolev正则化,有助于抑制低密度区域的高频振荡。
关键设计:γ-FM的关键设计包括:1) 动态密度估计方法:具体如何从训练粒子中估计目标密度,可能涉及核密度估计或其他密度估计技术;2) 密度加权损失函数:如何将估计的密度融入到回归损失中,例如使用密度作为权重系数;3) γ-Stein度量:理论分析中使用的γ-Stein度量如何影响模型的正则化效果。具体的网络结构和参数设置可能与标准FM类似,但损失函数的修改是关键。
🖼️ 关键图片


📊 实验亮点
实验结果表明,γ-FM在高维潜在数据集上显著提高了向量场的平滑度和采样效率。相较于标准FM,γ-FM在生成质量和训练稳定性方面均有提升,并且对异常值表现出更强的鲁棒性。具体性能数据(例如FID分数、采样速度等)未在摘要中明确给出,但强调了其在实际应用中的优势。
🎯 应用场景
γ-Flow Matching可应用于各种生成模型任务,尤其是在高维数据生成和处理领域,例如图像生成、分子生成、点云生成等。通过提高采样效率和生成质量,可以加速新材料发现、药物设计等领域的研发进程。此外,其对异常值的鲁棒性使其在数据清洗和异常检测方面也具有潜在应用价值。
📄 摘要(原文)
Flow Matching (FM) has emerged as a powerful paradigm for continuous normalizing flows, yet standard FM implicitly performs an unweighted $L^2$ regression over the entire ambient space. In high dimensions, this leads to a fundamental inefficiency: the vast majority of the integration domain consists of low-density ``void'' regions where the target velocity fields are often chaotic or ill-defined. In this paper, we propose {$γ$-Flow Matching ($γ$-FM)}, a density-weighted variant that aligns the regression geometry with the underlying probability flow. While density weighting is desirable, naive implementations would require evaluating the intractable target density. We circumvent this by introducing a Dynamic Density-Weighting strategy that estimates the \emph{target} density directly from training particles. This approach allows us to dynamically downweight the regression loss in void regions without compromising the simulation-free nature of FM. Theoretically, we establish that $γ$-FM minimizes the transport cost on a statistical manifold endowed with the $γ$-Stein metric. Spectral analysis further suggests that this geometry induces an implicit Sobolev regularization, effectively damping high-frequency oscillations in void regions. Empirically, $γ$-FM significantly improves vector field smoothness and sampling efficiency on high-dimensional latent datasets, while demonstrating intrinsic robustness to outliers.