Max-Entropy Reinforcement Learning with Flow Matching and A Case Study on LQR
作者: Yuyang Zhang, Yang Hu, Bo Dai, Na Li
分类: cs.LG
发布日期: 2025-12-29
💡 一句话要点
提出基于Flow Matching的最大熵强化学习算法,提升策略表达能力与鲁棒性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 最大熵强化学习 软演员-评论家 流模型 流匹配 重要性采样 策略优化 线性二次调节器
📋 核心要点
- SAC算法虽然常用,但其能量策略常因效率问题而采用简单策略类,牺牲了策略的表达能力和鲁棒性。
- 本文提出使用基于流的模型来参数化策略,利用其强大的表达能力,并设计了在线重要性采样流匹配(ISFM)算法进行策略更新。
- 通过在最大熵线性二次调节器问题上的案例研究,验证了所提出的算法能够学习到最优的动作分布。
📝 摘要(中文)
本文提出了一种软演员-评论家(SAC)算法的变体,用于最大熵强化学习。SAC算法中,基于能量的策略通常使用简单的策略类来近似,以提高效率,但牺牲了表达性和鲁棒性。本文利用基于流的模型来参数化策略,从而利用其丰富的表达能力。该算法利用瞬时变量变换技术评估基于流的策略,并使用本文开发的在线流匹配变体更新策略。这种在线变体,称为重要性采样流匹配(ISFM),仅使用来自用户指定的采样分布的样本,而不是未知的目标分布,即可进行策略更新。本文对ISFM进行了理论分析,描述了不同采样分布的选择如何影响学习效率。最后,我们在最大熵线性二次调节器问题上进行了案例研究,证明了该算法能够学习到最优的动作分布。
🔬 方法详解
问题定义:现有SAC算法为了效率,通常使用简单的策略类近似能量策略,导致策略表达能力不足,鲁棒性较差。本文旨在解决最大熵强化学习中策略表达能力和鲁棒性之间的权衡问题,即如何在保证效率的同时,提升策略的表达能力。
核心思路:本文的核心思路是利用基于流的模型(Flow-based Models)来参数化策略。Flow-based模型具有强大的表达能力,能够表示复杂的概率分布。同时,为了解决策略更新时需要从未知目标分布中采样的问题,提出了在线重要性采样流匹配(ISFM)算法。
技术框架:整体框架仍然基于SAC算法,但策略网络被替换为Flow-based模型。算法包含以下主要步骤:1)使用Flow-based模型参数化策略;2)使用瞬时变量变换技术评估策略;3)使用ISFM算法更新策略。ISFM算法是本文的核心技术,它允许使用任意采样分布进行策略更新,而无需从目标分布中采样。
关键创新:最重要的创新点在于提出了在线重要性采样流匹配(ISFM)算法。传统的流匹配算法需要从目标分布中采样,这在强化学习中是不可行的,因为目标分布是未知的。ISFM算法通过重要性采样技术,将目标分布的采样问题转化为从用户指定的采样分布中采样,从而实现了在线策略更新。这使得可以使用Flow-based模型等复杂的策略类进行强化学习。
关键设计:ISFM算法的关键在于选择合适的采样分布。论文中对不同采样分布的选择进行了理论分析,并给出了选择采样分布的指导原则。此外,损失函数的设计也至关重要,ISFM算法使用了一种基于重要性权重的损失函数,以保证策略更新的稳定性。具体而言,损失函数通常包含一个流匹配损失项和一个正则化项,用于约束策略的复杂度。
🖼️ 关键图片

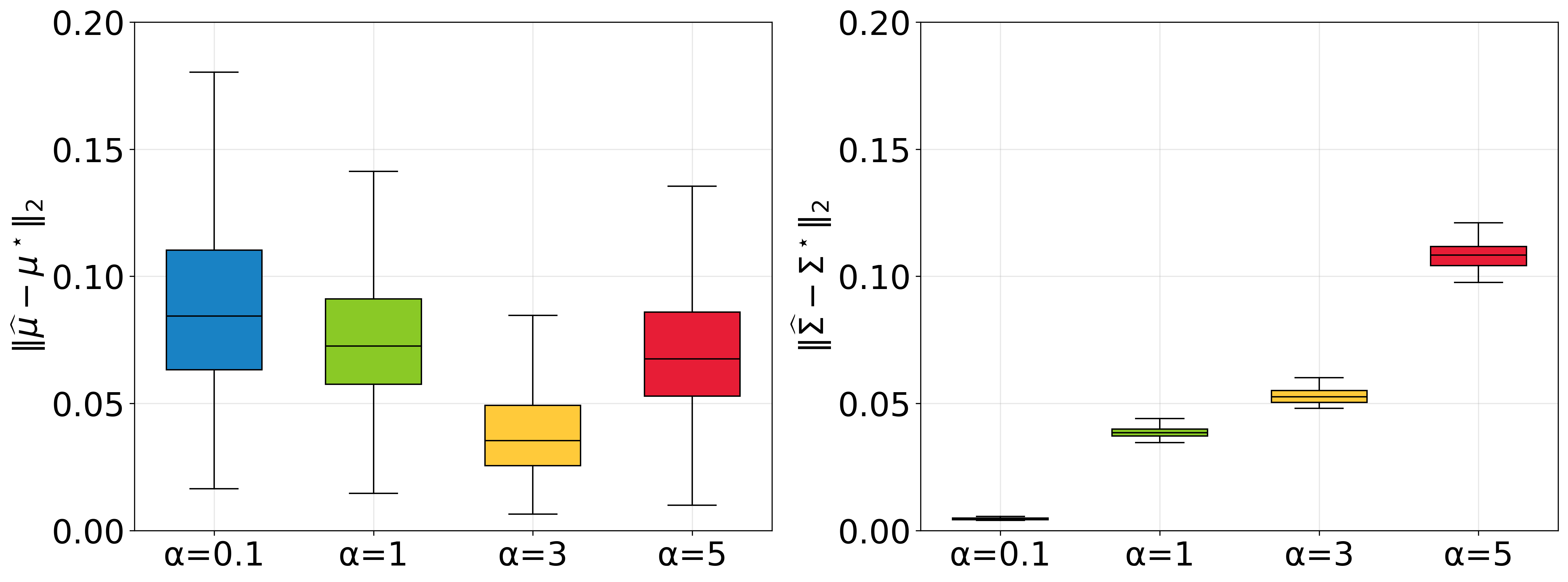
📊 实验亮点
该论文在最大熵线性二次调节器(LQR)问题上进行了案例研究,实验结果表明,所提出的算法能够学习到最优的动作分布。这验证了该算法的有效性和优越性。虽然论文没有给出与其他SAC变体的直接性能对比,但通过理论分析和LQR案例研究,证明了该算法在策略表达能力和学习效率方面的优势。
🎯 应用场景
该研究成果可应用于需要复杂策略表达的强化学习任务中,例如机器人控制、自动驾驶、金融交易等。通过提升策略的表达能力和鲁棒性,可以使智能体更好地适应复杂环境,并获得更高的回报。未来,该方法可以进一步扩展到多智能体强化学习、元强化学习等领域。
📄 摘要(原文)
Soft actor-critic (SAC) is a popular algorithm for max-entropy reinforcement learning. In practice, the energy-based policies in SAC are often approximated using simple policy classes for efficiency, sacrificing the expressiveness and robustness. In this paper, we propose a variant of the SAC algorithm that parameterizes the policy with flow-based models, leveraging their rich expressiveness. In the algorithm, we evaluate the flow-based policy utilizing the instantaneous change-of-variable technique and update the policy with an online variant of flow matching developed in this paper. This online variant, termed importance sampling flow matching (ISFM), enables policy update with only samples from a user-specified sampling distribution rather than the unknown target distribution. We develop a theoretical analysis of ISFM, characterizing how different choices of sampling distributions affect the learning efficiency. Finally, we conduct a case study of our algorithm on the max-entropy linear quadratic regulator problems, demonstrating that the proposed algorithm learns the optimal action distribution.