SB-TRPO: Towards Safe Reinforcement Learning with Hard Constraints
作者: Ankit Kanwar, Dominik Wagner, Luke Ong
分类: cs.LG, cs.AI
发布日期: 2025-12-29 (更新: 2026-01-30)
💡 一句话要点
SB-TRPO:面向硬约束安全强化学习,动态平衡成本降低与奖励提升
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 安全强化学习 硬约束 信赖域策略优化 自然策略梯度 动态平衡
📋 核心要点
- 现有无模型强化学习方法在安全约束场景下,难以同时保证安全性(接近零违规)和任务完成度,面临保守或失效问题。
- SB-TRPO通过动态平衡奖励和成本的自然策略梯度,在保证安全约束的同时,尽可能提升奖励,实现安全与性能的平衡。
- 在Safety Gymnasium任务上的实验表明,SB-TRPO在硬约束条件下,能够始终如一地实现安全性和任务性能的最佳平衡。
📝 摘要(中文)
在安全攸关的领域中,强化学习(RL)智能体在完成任务时通常必须满足严格的零成本安全约束。现有的无模型方法要么无法实现接近零的安全违规,要么变得过于保守。我们提出了一种名为安全偏置信赖域策略优化(SB-TRPO)的算法,这是一种用于硬约束RL的原则性方法,它动态地平衡了成本降低与奖励改进。在每一步中,SB-TRPO通过奖励和成本自然策略梯度的动态凸组合进行更新,确保固定比例的最优成本降低,同时利用剩余的更新能力来改进奖励。我们的方法在安全性方面具有局部进展的形式保证,同时在梯度适当对齐时仍然可以提高奖励。在标准和具有挑战性的Safety Gymnasium任务上的实验表明,SB-TRPO在硬约束机制中始终如一地实现了安全性和任务性能的最佳平衡。
🔬 方法详解
问题定义:论文旨在解决安全强化学习中,智能体需要在满足严格安全约束的前提下,最大化奖励的问题。现有方法要么过于保守,导致奖励不高;要么无法满足安全约束,导致违规行为。因此,如何在保证安全性的前提下,尽可能地提升智能体的性能,是该论文要解决的核心问题。
核心思路:SB-TRPO的核心思路是,在每一步策略更新时,动态地平衡成本降低和奖励提升。算法通过奖励和成本的自然策略梯度的凸组合来实现这一平衡。具体来说,算法首先确保以一定的比例降低成本,然后利用剩余的更新能力来提升奖励。这种动态平衡的策略,使得智能体能够在保证安全性的前提下,尽可能地提升性能。
技术框架:SB-TRPO算法基于信赖域策略优化(TRPO)框架。整体流程如下: 1. 收集数据:使用当前策略与环境交互,收集状态、动作、奖励和成本等数据。 2. 计算梯度:计算奖励和成本的自然策略梯度。 3. 动态平衡:根据当前状态,动态地确定奖励和成本梯度的权重,形成凸组合。 4. 策略更新:使用凸组合后的梯度,更新策略。 5. 重复以上步骤,直到训练完成。
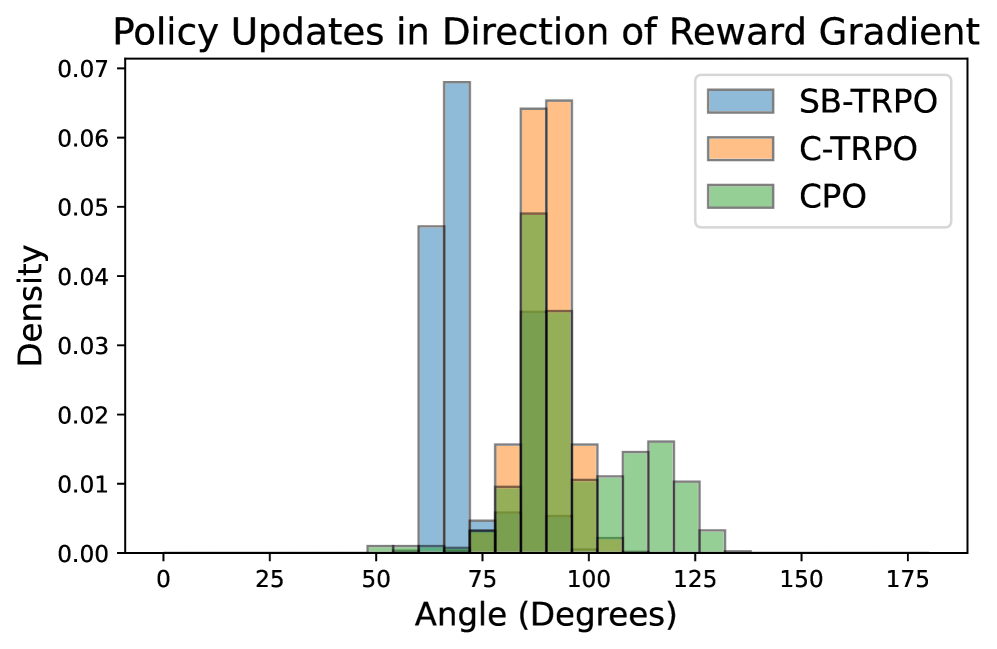
关键创新:SB-TRPO的关键创新在于其动态平衡奖励和成本梯度的机制。与现有方法不同,SB-TRPO不是简单地将成本作为约束添加到奖励函数中,而是通过动态调整梯度权重,来实现安全性和性能的平衡。这种方法能够更有效地利用策略更新空间,从而在保证安全性的前提下,获得更高的奖励。
关键设计:SB-TRPO的关键设计包括: 1. 动态权重:奖励和成本梯度的权重是动态调整的,取决于当前状态和策略。这种动态调整使得算法能够根据实际情况,灵活地平衡安全性和性能。 2. 自然策略梯度:使用自然策略梯度进行策略更新,能够更有效地利用策略更新空间,从而提高学习效率。 3. 信赖域:使用信赖域约束,防止策略更新过大,从而保证训练的稳定性。
🖼️ 关键图片


📊 实验亮点
SB-TRPO在Safety Gymnasium任务上表现出色,在硬约束条件下,实现了安全性和任务性能的最佳平衡。具体来说,SB-TRPO能够有效地降低成本,同时尽可能地提升奖励。与现有方法相比,SB-TRPO在安全性和性能方面都取得了显著的提升。实验结果表明,SB-TRPO是一种有效的安全强化学习算法,具有很强的实用价值。
🎯 应用场景
SB-TRPO算法适用于任何需要在满足严格安全约束的前提下进行决策的场景,例如自动驾驶、机器人控制、医疗诊断等。在这些场景中,安全是至关重要的,任何违规行为都可能导致严重的后果。SB-TRPO算法能够有效地保证安全性,同时尽可能地提升性能,从而为这些应用提供更可靠的解决方案。未来,该算法有望在更多安全攸关的领域得到应用,并为人类带来更大的福祉。
📄 摘要(原文)
In safety-critical domains, reinforcement learning (RL) agents must often satisfy strict, zero-cost safety constraints while accomplishing tasks. Existing model-free methods frequently either fail to achieve near-zero safety violations or become overly conservative. We introduce Safety-Biased Trust Region Policy Optimisation (SB-TRPO), a principled algorithm for hard-constrained RL that dynamically balances cost reduction with reward improvement. At each step, SB-TRPO updates via a dynamic convex combination of the reward and cost natural policy gradients, ensuring a fixed fraction of optimal cost reduction while using remaining update capacity for reward improvement. Our method comes with formal guarantees of local progress on safety, while still improving reward whenever gradients are suitably aligned. Experiments on standard and challenging Safety Gymnasium tasks demonstrate that SB-TRPO consistently achieves the best balance of safety and task performance in the hard-constrained regime.