Post-Training Quantization of OpenPangu Models for Efficient Deployment on Atlas A2
作者: Yilun Luo, Huaqing Zheng, Haoqian Meng, Wenyuan Liu, Peng Zhang
分类: cs.LG, cs.AI
发布日期: 2025-12-29 (更新: 2026-01-08)
💡 一句话要点
针对昇腾A2,提出OpenPangu模型后训练量化方案,实现高效部署。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 后训练量化 大语言模型 昇腾NPU 模型部署 低比特推理
📋 核心要点
- 现有CoT推理增强了模型能力,但生成扩展推理轨迹引入了大量的内存和延迟开销,给Ascend NPU上的实际部署带来了挑战。
- 论文提出了一种统一的低比特推理框架,支持INT8和W4A8量化,将FP16计算转换为更高效的整数运算,从而降低计算和存储需求。
- 实验结果表明,INT8量化在保持较高精度的同时实现了1.5倍的预填充加速,W4A8量化则显著降低了内存消耗。
📝 摘要(中文)
本文针对华为openPangu-Embedded-1B和openPangu-Embedded-7B大语言模型在昇腾NPU上的高效部署问题,利用低比特量化技术,将FP16计算转换为更高效的整数运算。论文提出了一个统一的低比特推理框架,支持INT8 (W8A8)和W4A8量化,并针对Atlas A2上的openPangu-Embedded模型进行了优化。在代码生成基准测试(HumanEval和MBPP)上的评估表明,INT8量化始终保持超过90%的FP16基线精度,并在Atlas A2上实现了1.5倍的预填充加速。W4A8量化显著降低了内存消耗,但精度略有下降。研究结果表明,低比特量化有效地促进了昇腾NPU上高效的CoT推理,同时保持了较高的模型保真度。
🔬 方法详解
问题定义:论文旨在解决openPangu系列模型在Ascend NPU上部署时,由于CoT推理带来的高内存和高延迟问题。现有方法难以在资源受限的设备上实现高效的CoT推理,限制了大型语言模型在边缘设备上的应用。
核心思路:论文的核心思路是利用后训练量化(Post-Training Quantization, PTQ)技术,将模型中的浮点数运算转换为低比特整数运算。通过降低计算精度,可以显著减少模型的内存占用和计算复杂度,从而提高推理速度。
技术框架:论文提出了一个统一的低比特推理框架,该框架支持INT8 (W8A8) 和 W4A8 两种量化方案。整体流程包括:首先,对FP16模型进行量化,将其转换为INT8或W4A8模型;然后,在Atlas A2硬件平台上部署量化后的模型进行推理。该框架针对Atlas A2的硬件特性进行了优化,以充分利用其计算能力。
关键创新:论文的关键创新在于针对openPangu-Embedded模型,探索了低比特量化在Ascend NPU上的应用,并验证了其在CoT推理场景下的有效性。与传统的量化方法相比,该研究针对特定模型和硬件平台进行了优化,从而获得了更好的性能。
关键设计:论文中没有详细描述具体的量化参数设置、损失函数或网络结构等技术细节。但是,可以推断,该研究可能采用了诸如Min-Max量化或KL散度量化等常用的量化方法,并根据openPangu模型的特点进行了调整。具体参数设置和优化策略未知。
🖼️ 关键图片

📊 实验亮点
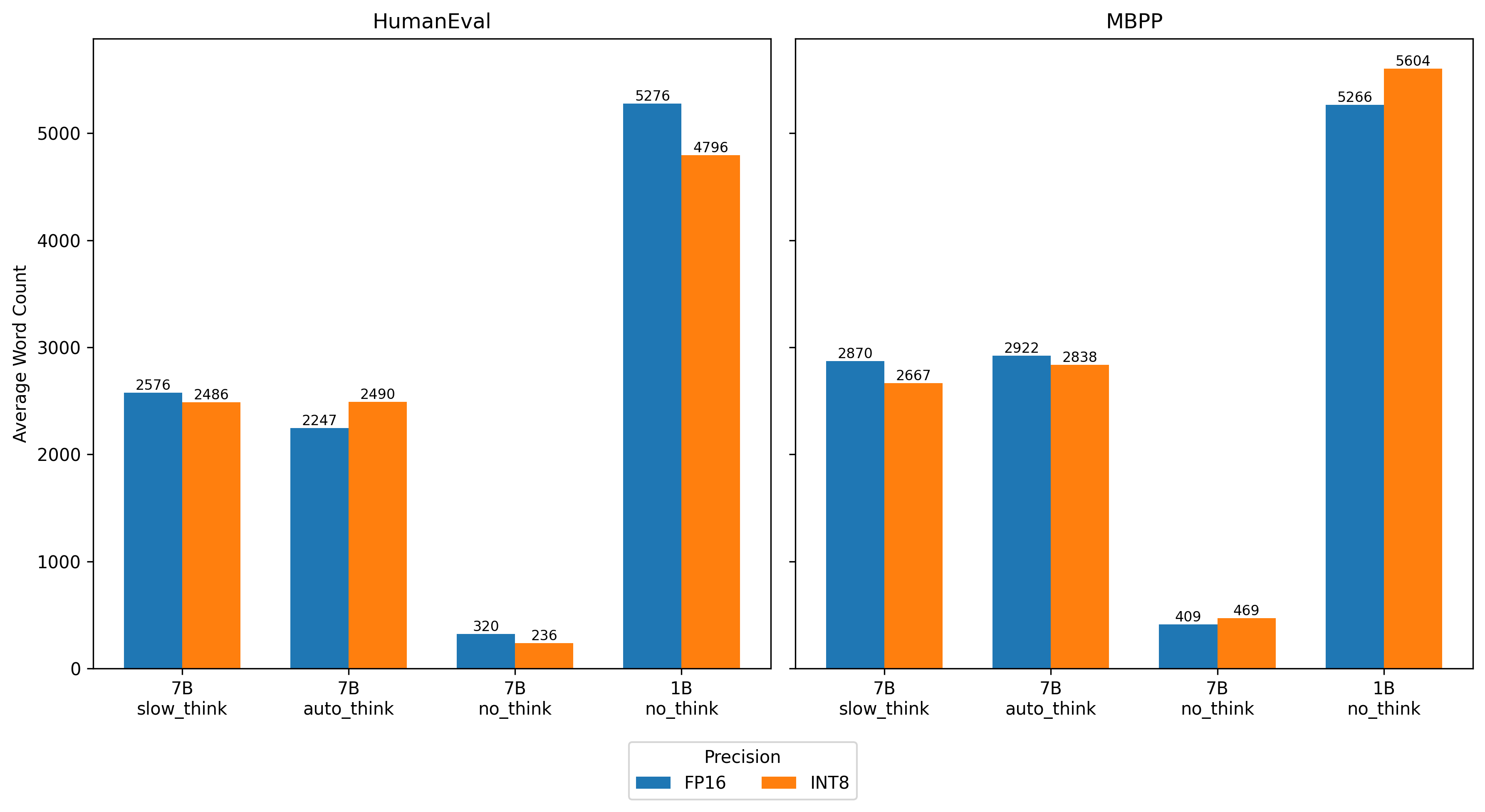
实验结果表明,INT8量化在HumanEval和MBPP代码生成基准测试中,始终保持超过90%的FP16基线精度,并在Atlas A2上实现了1.5倍的预填充加速。W4A8量化虽然精度略有下降,但显著降低了内存消耗,为资源受限的场景提供了另一种选择。
🎯 应用场景
该研究成果可应用于各种需要高效部署大型语言模型的场景,例如边缘计算、移动设备和嵌入式系统。通过降低模型的大小和计算需求,可以使这些模型在资源受限的设备上运行,从而实现更广泛的应用,例如智能助手、自动驾驶和智能制造等。
📄 摘要(原文)
Huawei's openPangu-Embedded-1B and openPangu-Embedded-7B are variants of the openPangu large language model, designed for efficient deployment on Ascend NPUs. The 7B variant supports three distinct Chain-of-Thought (CoT) reasoning paradigms, namely slow_think, auto_think, and no_think, while the 1B variant operates exclusively in the no_think mode, which employs condensed reasoning for higher efficiency. Although CoT reasoning enhances capability, the generation of extended reasoning traces introduces substantial memory and latency overheads, posing challenges for practical deployment on Ascend NPUs. This paper addresses these computational constraints by leveraging low-bit quantization, which transforms FP16 computations into more efficient integer arithmetic. We introduce a unified low-bit inference framework, supporting INT8 (W8A8) and W4A8 quantization, specifically optimized for openPangu-Embedded models on the Atlas A2. Our comprehensive evaluation on code generation benchmarks (HumanEval and MBPP) demonstrates the efficacy of this approach. INT8 quantization consistently preserves over 90\% of the FP16 baseline accuracy and achieves a 1.5x prefill speedup on the Atlas A2. Furthermore, W4A8 quantization significantly reduces memory consumption, albeit with a moderate trade-off in accuracy. These findings collectively indicate that low-bit quantization effectively facilitates efficient CoT reasoning on Ascend NPUs, maintaining high model fidelity.