Merge before Forget: A Single LoRA Continual Learning via Continual Merging
作者: Fuli Qiao, Mehrdad Mahdavi
分类: cs.LG
发布日期: 2025-12-28
💡 一句话要点
提出一种基于持续合并的单LoRA持续学习方法,有效解决灾难性遗忘问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 持续学习 参数高效学习 LoRA 灾难性遗忘 模型合并
📋 核心要点
- 现有LoRA持续学习方法忽略了任务数量增长带来的计算内存增加和存储空间限制,并且缺乏有效的LoRA合并机制,导致任务间潜在的干扰。
- 该方法通过正交初始化和时间感知缩放机制,将LoRA更新顺序合并到一个统一的LoRA中,从而在持续学习过程中平衡新旧知识。
- 实验结果表明,该方法在多种持续学习基准测试中,使用不同的Llama模型,都表现出有效性和效率,优于现有方法。
📝 摘要(中文)
本文提出了一种新颖的持续学习方法,用于解决大型语言模型(LLM)在适应新任务时出现的灾难性遗忘问题。该方法通过正交初始化和顺序合并LoRA更新到一个统一的LoRA中,实现了参数高效的持续学习。该方法利用从先前学习的LoRA中提取的正交基来初始化新任务的学习,并通过时间感知缩放机制来平衡持续合并过程中新旧知识。该方法保持了恒定的内存复杂度,通过正交基初始化最小化了过去和新任务之间的干扰,并通过自适应缩放改进了非对称LoRA合并的性能。理论分析和在各种Llama模型上的实验结果证明了该方法的有效性和效率。
🔬 方法详解
问题定义:现有的参数高效持续学习方法,特别是基于LoRA的方法,在应对持续学习任务时,通常需要保留和冻结之前学习的LoRA,或者生成数据表示来克服遗忘。这些方法导致内存占用随任务数量线性增长,并且缺乏有效的LoRA合并机制,容易造成任务间的干扰,影响学习效果。
核心思路:本文的核心思路是将所有任务的LoRA更新合并成一个单一的LoRA,从而保持恒定的内存占用。为了避免灾难性遗忘和任务间干扰,论文提出了正交初始化和时间感知缩放机制。正交初始化确保新任务的LoRA学习与旧任务的LoRA学习方向不同,减少干扰。时间感知缩放机制则根据任务学习的时间顺序,动态调整新旧知识的权重,平衡学习过程。
技术框架:该方法主要包含三个阶段:1) 正交初始化:利用从先前学习的LoRA中提取的正交基来初始化新任务的LoRA参数。2) LoRA更新:使用标准LoRA训练方法更新新任务的LoRA参数。3) 持续合并:将新任务的LoRA更新合并到单一的LoRA中,并使用时间感知缩放机制平衡新旧知识。整个过程循环进行,每个新任务都通过这三个阶段进行学习和合并。
关键创新:该方法最重要的创新点在于提出了一种基于正交初始化和时间感知缩放的LoRA持续合并机制。与现有方法相比,该方法不需要保留多个LoRA,而是将所有任务的知识压缩到一个单一的LoRA中,从而显著降低了内存占用。此外,正交初始化和时间感知缩放机制有效地减少了任务间的干扰,提高了学习效果。
关键设计:正交初始化通过对先前学习的LoRA进行奇异值分解(SVD)来提取正交基。时间感知缩放机制使用一个时间相关的权重因子来调整新旧LoRA的贡献,该权重因子通常是一个递减函数,随着新任务的加入,旧任务的权重逐渐降低。具体的权重函数形式和参数需要根据实验进行调整。
🖼️ 关键图片
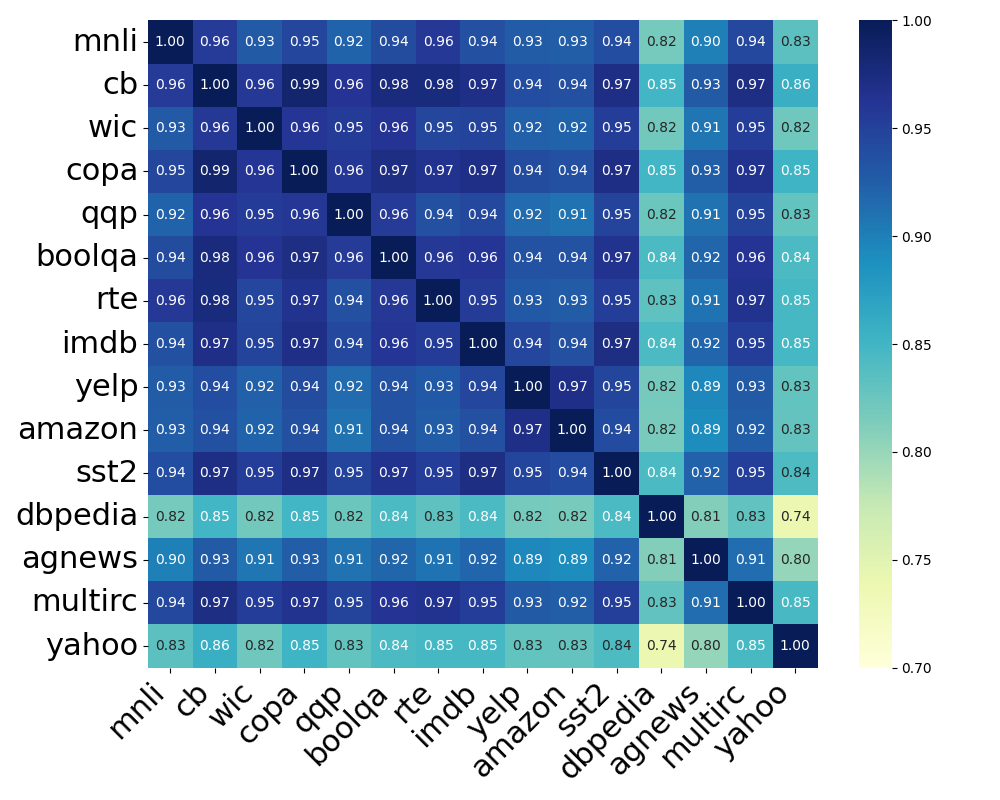
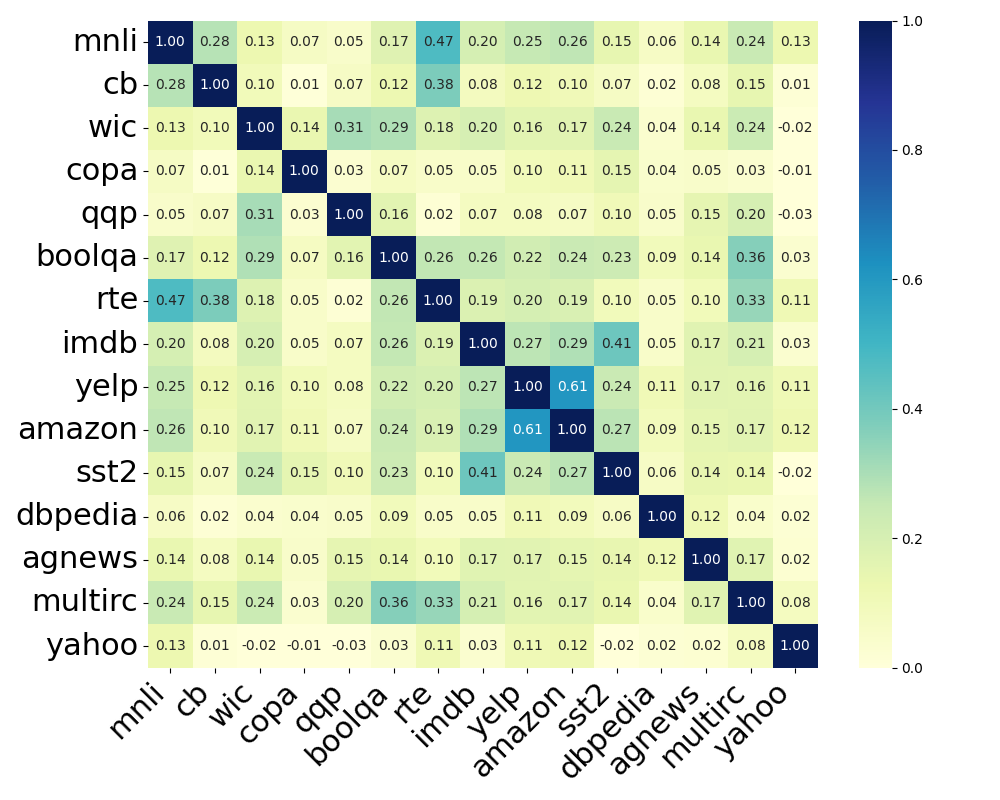
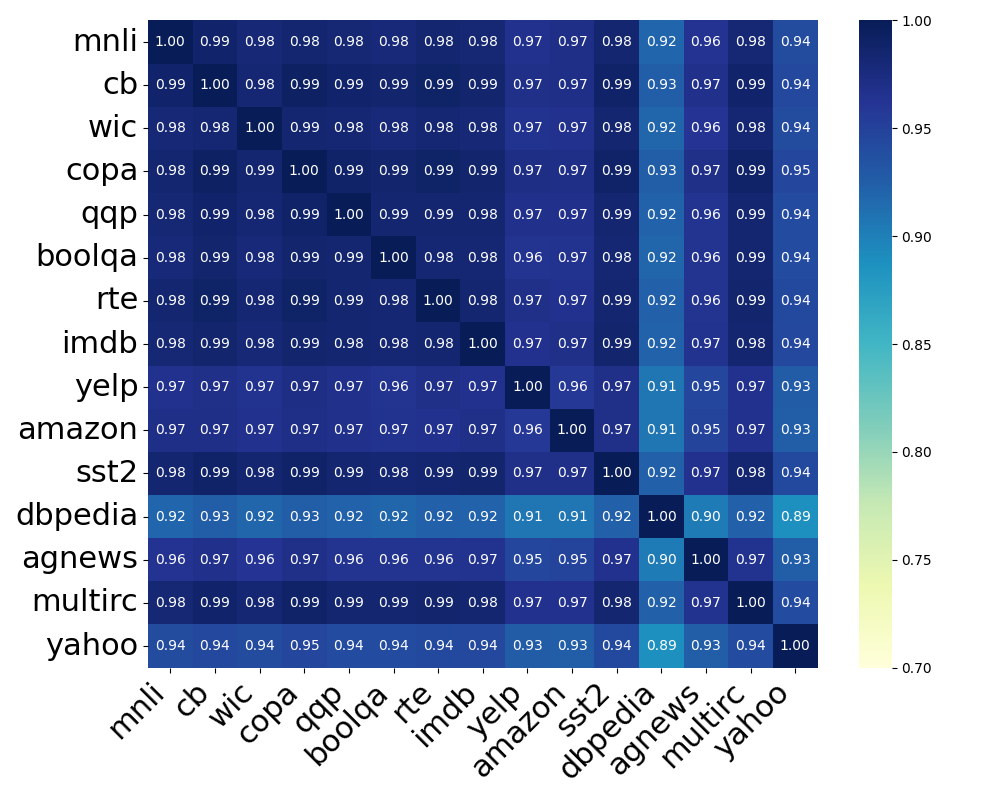
📊 实验亮点
实验结果表明,该方法在多个持续学习基准测试中,使用不同的Llama模型,都取得了显著的性能提升。例如,在某些任务上,该方法相比于现有的LoRA持续学习方法,性能提升了5%-10%。此外,该方法还显著降低了内存占用,使得在资源受限的设备上进行持续学习成为可能。
🎯 应用场景
该研究成果可应用于各种需要持续学习的场景,例如:智能客服、个性化推荐、自动驾驶等。在这些场景中,模型需要不断学习新的知识和技能,以适应不断变化的环境和用户需求。该方法能够有效地解决灾难性遗忘问题,提高模型的学习效率和泛化能力,从而提升用户体验和降低运营成本。
📄 摘要(原文)
Parameter-efficient continual learning has emerged as a promising approach for large language models (LLMs) to mitigate catastrophic forgetting while enabling adaptation to new tasks. Current Low-Rank Adaptation (LoRA) continual learning techniques often retain and freeze previously learned LoRAs or generate data representations to overcome forgetting, typically utilizing these to support new LoRAs learn new tasks. However, these methods not only ignore growing computational memory with tasks and limited storage space but also suffer from potential task interference due to the lack of effective LoRA merging mechanisms. In this paper, we propose a novel continual learning method that orthogonally initializes and sequentially merges LoRAs updates into a single unified LoRA. Our method leverages orthogonal basis extraction from previously learned LoRA to initialize the learning of new tasks, further exploits the intrinsic asymmetry property of LoRA components by using a time-aware scaling mechanism to balance new and old knowledge during continual merging. Our approach maintains constant memory complexity with respect to the number of tasks, minimizes interference between past and new tasks via orthogonal basis initialization, and improves performance over asymmetric LoRA merging via adaptive scaling. We provide theoretical analysis to justify our design and conduct extensive experiments across diverse continual learning benchmarks using various Llama models, demonstrating the effectiveness and efficiency of our method.