Adaptive Trust Consensus for Blockchain IoT: Comparing RL, DRL, and MARL Against Naive, Collusive, Adaptive, Byzantine, and Sleeper Attacks
作者: Soham Padia, Dhananjay Vaidya, Ramchandra Mangrulkar
分类: cs.CR, cs.LG, cs.MA
发布日期: 2025-12-28
备注: 34 pages, 19 figures, 10 tables. Code available at https://github.com/soham-padia/blockchain-iot-trust
💡 一句话要点
提出基于强化学习的自适应信任共识机制,防御区块链物联网中的复杂攻击
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱五:交互与反应 (Interaction & Reaction)
关键词: 区块链物联网 强化学习 信任共识 安全防御 多智能体学习
📋 核心要点
- 区块链物联网面临复杂对抗攻击,现有防御方法难以有效应对自适应和共谋攻击。
- 提出一种基于强化学习的自适应信任共识框架,结合FHE和ABAC实现隐私保护和策略评估。
- 实验表明,MARL在防御共谋攻击方面优于DRL和RL,DRL和MARL在防御自适应攻击方面表现出色。
📝 摘要(中文)
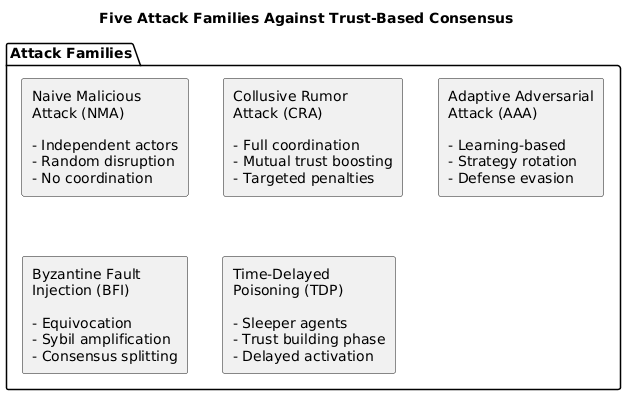
本文提出了一种基于信任的委托共识框架,该框架集成了全同态加密(FHE)与基于属性的访问控制(ABAC),用于保护隐私的策略评估,并结合了基于学习的防御机制。系统地比较了三种强化学习方法——表格型Q学习(RL)、具有Dueling Double DQN的深度RL(DRL)和多智能体RL(MARL)——对抗五种不同的攻击类型:朴素恶意攻击(NMA)、共谋谣言攻击(CRA)、自适应对抗攻击(AAA)、拜占庭故障注入(BFI)和时间延迟投毒(TDP)。在16节点模拟物联网网络上的实验结果表明,性能差异显著:MARL在共谋攻击下实现了卓越的检测(F1=0.85,DRL为0.68,RL为0.50),而DRL和MARL在自适应攻击下均实现了完美的检测(F1=1.00),而RL失败(F1=0.50)。所有智能体都成功防御了拜占庭攻击(F1=1.00)。最关键的是,时间延迟投毒攻击对所有智能体都是灾难性的,在潜伏期激活后,F1分数降至0.11-0.16,证明了信任构建攻击者构成的严重威胁。研究结果表明,协调的多智能体学习为防御区块链物联网环境中复杂的信任操纵攻击提供了可衡量的优势。
🔬 方法详解
问题定义:论文旨在解决区块链物联网环境中,现有共识机制在面对复杂攻击(如共谋攻击、自适应攻击和时间延迟投毒攻击)时存在的脆弱性问题。现有的方法通常难以有效识别和防御这些攻击,导致系统信任机制崩溃,数据安全受到威胁。
核心思路:论文的核心思路是利用强化学习(RL)、深度强化学习(DRL)和多智能体强化学习(MARL)来构建自适应的信任评估和共识机制。通过让节点学习在不同攻击场景下的最佳防御策略,提高系统对恶意行为的检测和抵御能力。同时,结合全同态加密(FHE)和基于属性的访问控制(ABAC)来保护隐私,确保策略评估过程中的数据安全。
技术框架:该框架包含以下主要模块:1) 基于FHE和ABAC的隐私保护策略评估模块;2) 基于RL、DRL或MARL的信任评估模块;3) 委托共识模块,根据信任评估结果选择合适的节点参与共识过程。整体流程是:首先,节点通过FHE和ABAC进行策略评估,生成信任值;然后,RL/DRL/MARL智能体根据信任值学习防御策略;最后,委托共识模块根据学习到的策略选择节点参与共识,从而抵御攻击。
关键创新:最重要的技术创新点在于将强化学习应用于区块链物联网的信任共识机制中,使其能够自适应地应对各种复杂的攻击。与传统的静态信任机制相比,该方法能够根据环境变化动态调整防御策略,提高系统的鲁棒性和安全性。此外,对比了RL、DRL和MARL在不同攻击场景下的性能,为实际应用提供了指导。
关键设计:论文中,RL使用表格型Q学习,DRL使用Dueling Double DQN,MARL则采用多个智能体协同学习。关键参数包括学习率、折扣因子、探索率等。损失函数采用均方误差损失函数,用于衡量Q值预测的准确性。网络结构方面,Dueling Double DQN采用了两个独立的网络分别估计值函数和优势函数,以提高学习效率和稳定性。
🖼️ 关键图片


📊 实验亮点
实验结果表明,MARL在防御共谋攻击方面表现最佳,F1值达到0.85,显著优于DRL(0.68)和RL(0.50)。DRL和MARL在防御自适应攻击方面均达到完美的检测效果(F1=1.00),而RL的F1值仅为0.50。然而,时间延迟投毒攻击对所有智能体都造成了严重影响,在攻击激活后,F1值均降至0.11-0.16,突显了该攻击的威胁性。
🎯 应用场景
该研究成果可应用于各种区块链物联网场景,例如智能家居、智能交通、供应链管理等。通过提高系统的安全性和可靠性,可以促进区块链技术在物联网领域的广泛应用,并为用户提供更安全、可信赖的服务。未来的研究可以进一步探索更先进的强化学习算法和隐私保护技术,以应对更加复杂的攻击场景。
📄 摘要(原文)
Securing blockchain-enabled IoT networks against sophisticated adversarial attacks remains a critical challenge. This paper presents a trust-based delegated consensus framework integrating Fully Homomorphic Encryption (FHE) with Attribute-Based Access Control (ABAC) for privacy-preserving policy evaluation, combined with learning-based defense mechanisms. We systematically compare three reinforcement learning approaches -- tabular Q-learning (RL), Deep RL with Dueling Double DQN (DRL), and Multi-Agent RL (MARL) -- against five distinct attack families: Naive Malicious Attack (NMA), Collusive Rumor Attack (CRA), Adaptive Adversarial Attack (AAA), Byzantine Fault Injection (BFI), and Time-Delayed Poisoning (TDP). Experimental results on a 16-node simulated IoT network reveal significant performance variations: MARL achieves superior detection under collusive attacks (F1=0.85 vs. DRL's 0.68 and RL's 0.50), while DRL and MARL both attain perfect detection (F1=1.00) against adaptive attacks where RL fails (F1=0.50). All agents successfully defend against Byzantine attacks (F1=1.00). Most critically, the Time-Delayed Poisoning attack proves catastrophic for all agents, with F1 scores dropping to 0.11-0.16 after sleeper activation, demonstrating the severe threat posed by trust-building adversaries. Our findings indicate that coordinated multi-agent learning provides measurable advantages for defending against sophisticated trust manipulation attacks in blockchain IoT environments.