Long-Range Distillation: Distilling 10,000 Years of Simulated Climate into Long Timestep AI Weather Models
作者: Scott A. Martin, Noah Brenowitz, Dale Durran, Michael Pritchard
分类: cs.LG, physics.ao-ph
发布日期: 2025-12-28
💡 一句话要点
提出长程蒸馏方法,利用AI生成气候数据提升长时程AI天气模型预测能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 长时程预测 AI天气模型 蒸馏学习 合成数据 气候模拟 次季节预测 季节性预测
📋 核心要点
- 现有AI天气模型在长时程预测中面临误差累积和训练数据不足的挑战,限制了预测精度和稳定性。
- 论文提出长程蒸馏方法,利用短时程自回归教师模型生成大规模合成气候数据,训练长时程概率学生模型。
- 实验表明,该方法在完美模型和真实世界中均表现出优异的预测能力,且性能随数据量增加而提升。
📝 摘要(中文)
精确的长时程天气预报对AI模型来说仍然是一个巨大的挑战,这既是因为误差会在自回归展开中累积,也是因为用于训练的再分析数据集提供的气候变率慢模式样本有限,而这些慢模式是可预测性的基础。大多数AI天气模型都是自回归的,产生短期预测,必须重复应用才能达到次季节到季节(S2S)或季节性提前期,这通常会导致不稳定和校准问题。一步生成长程预测的长时程概率模型提供了一个有吸引力的替代方案,但使用40年的再分析记录进行训练会导致过拟合,这表明需要更多数量级的训练数据。我们引入了长程蒸馏,这是一种训练长时程概率“学生”模型的方法,该模型使用短时程自回归“教师”模型生成的大量合成训练数据集直接预测长程。使用深度学习地球系统模型(DLESyM)作为教师,我们生成超过10,000年的模拟气候来训练蒸馏学生模型,用于跨越一系列时间尺度的预测。在完美模型实验中,蒸馏模型优于气候学,并接近其自回归教师的技能,同时用单个时间步长取代了数百个自回归步骤。在现实世界中,经过ERA5微调后,它们实现了与ECMWF集合预报相当的S2S预测技能。我们的蒸馏模型的技能随着合成训练数据的增加而扩展,即使该数据比ERA5大几个数量级。这代表了AI生成的合成训练数据可用于扩展长程预测技能的首次演示。
🔬 方法详解
问题定义:现有AI天气模型,特别是自回归模型,在进行长时程天气预测时面临两个主要问题。一是自回归模型需要多次迭代预测,每次迭代都会引入误差,导致误差累积,最终影响预测精度。二是用于训练AI模型的再分析数据集(如ERA5)的时间跨度有限,无法充分捕捉气候系统的长期变率,导致模型难以学习到长时程预测所需的关键信息。
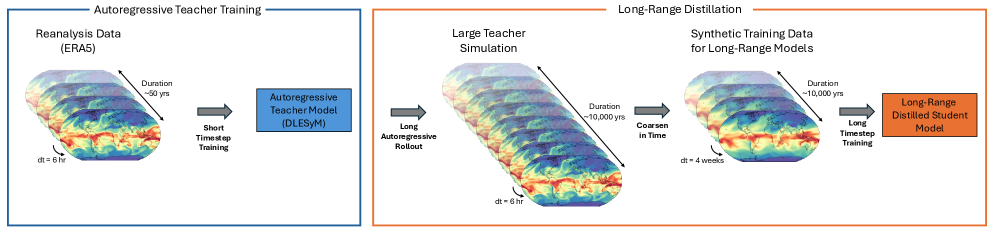
核心思路:论文的核心思路是利用“蒸馏”的思想,将一个高性能的短时程自回归模型(教师模型)的知识转移到一个长时程概率模型(学生模型)上。具体来说,教师模型生成大量的合成气候数据,作为学生模型的训练数据。学生模型直接预测长时程的天气状况,避免了自回归模型的误差累积问题,同时利用大规模的合成数据克服了真实数据不足的限制。
技术框架:整体框架包含两个主要部分:教师模型和学生模型。教师模型采用DLESyM模型,生成长达10000年的合成气候数据。学生模型是一个长时程概率模型,其输入是初始天气状态,输出是未来一段时间的天气状况的概率分布。学生模型使用教师模型生成的合成数据进行训练,并通过最小化预测结果与真实结果之间的差异来学习气候系统的动态规律。在真实世界应用中,学生模型还会使用ERA5等真实数据进行微调,以适应真实世界的气候特征。
关键创新:最重要的技术创新点在于利用AI生成的合成数据来训练长时程预测模型。传统方法依赖于真实的历史数据,但真实数据的量往往不足以训练复杂的AI模型。通过使用教师模型生成大规模的合成数据,可以有效地克服数据不足的问题,并显著提升长时程预测的精度。此外,该方法将长时程预测问题转化为一个单步预测问题,避免了自回归模型的误差累积问题。
关键设计:教师模型采用DLESyM模型,该模型具有较高的精度和较好的稳定性。学生模型可以采用各种概率模型,例如变分自编码器(VAE)或生成对抗网络(GAN)。损失函数通常采用负对数似然函数或均方误差等。在训练过程中,需要仔细调整学习率、批量大小等超参数,以避免过拟合或欠拟合。
🖼️ 关键图片
📊 实验亮点
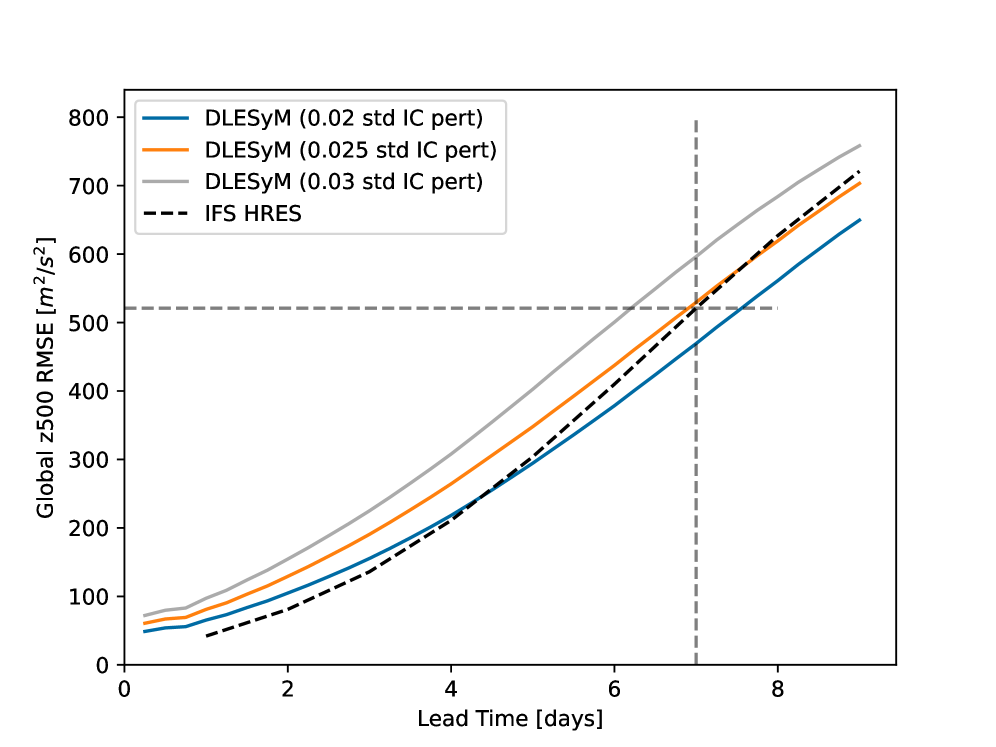
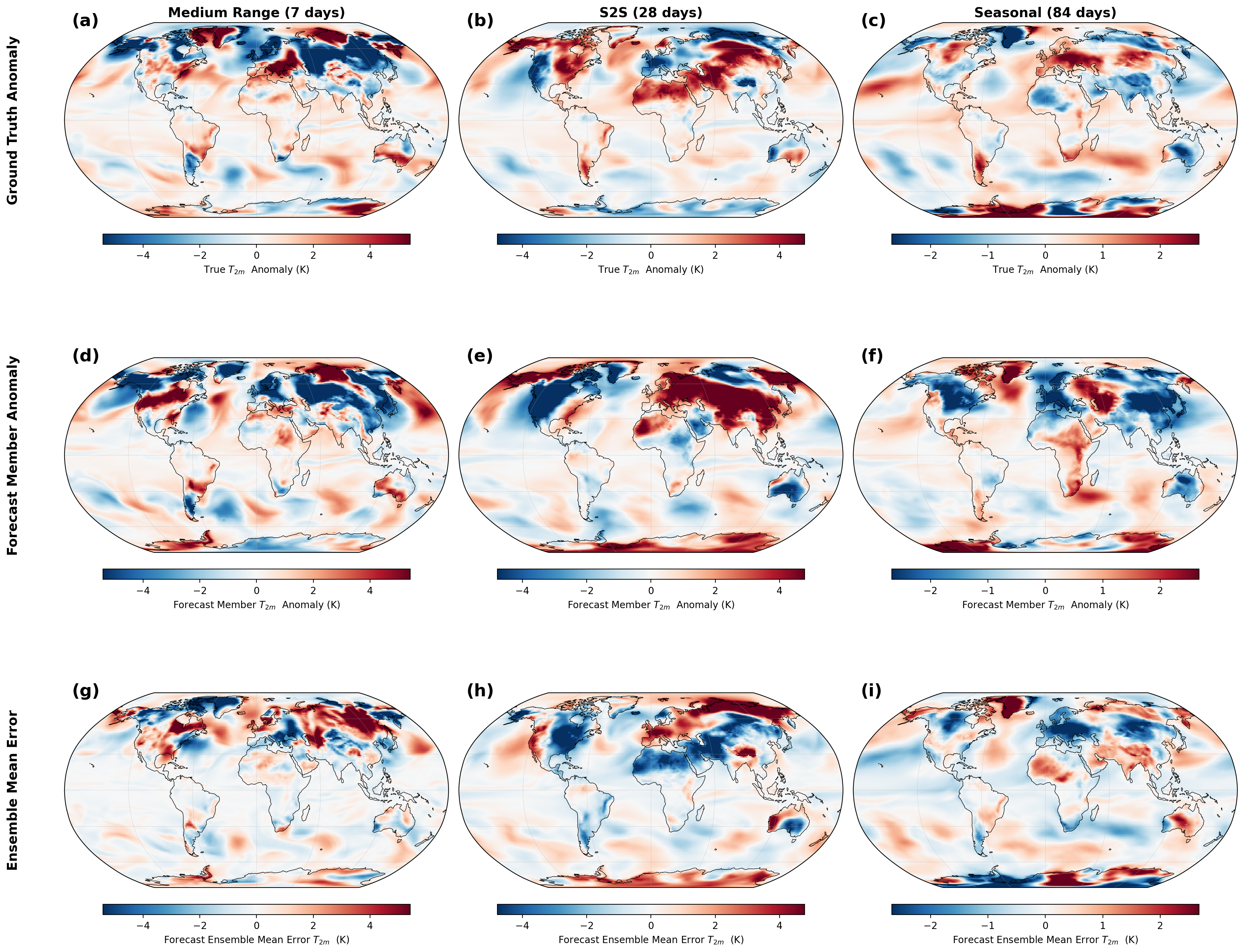
实验结果表明,使用长程蒸馏方法训练的学生模型在完美模型实验中优于气候学方法,并接近教师模型的预测能力,同时将数百个自回归步骤简化为单个步骤。在真实世界中,经过ERA5微调后,学生模型实现了与ECMWF集合预报相当的S2S预测技能。更重要的是,模型性能随着合成训练数据的增加而持续提升,即使数据量远超ERA5数据集,也未出现过拟合现象,证明了AI生成合成数据在提升长时程预测能力方面的潜力。
🎯 应用场景
该研究成果可应用于改进次季节到季节(S2S)和季节性天气预报,为农业、水资源管理、能源规划等领域提供更准确的长期气候预测信息。通过提高预测精度,可以帮助相关行业更好地应对气候变化带来的挑战,减少经济损失,并提高资源利用效率。未来,该方法有望推广到其他气候模型和预测任务中。
📄 摘要(原文)
Accurate long-range weather forecasting remains a major challenge for AI models, both because errors accumulate over autoregressive rollouts and because reanalysis datasets used for training offer a limited sample of the slow modes of climate variability underpinning predictability. Most AI weather models are autoregressive, producing short lead forecasts that must be repeatedly applied to reach subseasonal-to-seasonal (S2S) or seasonal lead times, often resulting in instability and calibration issues. Long-timestep probabilistic models that generate long-range forecasts in a single step offer an attractive alternative, but training on the 40-year reanalysis record leads to overfitting, suggesting orders of magnitude more training data are required. We introduce long-range distillation, a method that trains a long-timestep probabilistic "student" model to forecast directly at long-range using a huge synthetic training dataset generated by a short-timestep autoregressive "teacher" model. Using the Deep Learning Earth System Model (DLESyM) as the teacher, we generate over 10,000 years of simulated climate to train distilled student models for forecasting across a range of timescales. In perfect-model experiments, the distilled models outperform climatology and approach the skill of their autoregressive teacher while replacing hundreds of autoregressive steps with a single timestep. In the real world, they achieve S2S forecast skill comparable to the ECMWF ensemble forecast after ERA5 fine-tuning. The skill of our distilled models scales with increasing synthetic training data, even when that data is orders of magnitude larger than ERA5. This represents the first demonstration that AI-generated synthetic training data can be used to scale long-range forecast skill.