FoldAct: Efficient and Stable Context Folding for Long-Horizon Search Agents
作者: Jiaqi Shao, Yufeng Miao, Wei Zhang, Bing Luo
分类: cs.LG, cs.AI
发布日期: 2025-12-28
🔗 代码/项目: GITHUB
💡 一句话要点
提出FoldAct以解决长时间搜索代理的上下文折叠问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长时间强化学习 上下文折叠 摘要动作 训练效率 非平稳观察分布 智能系统 自然语言处理
📋 核心要点
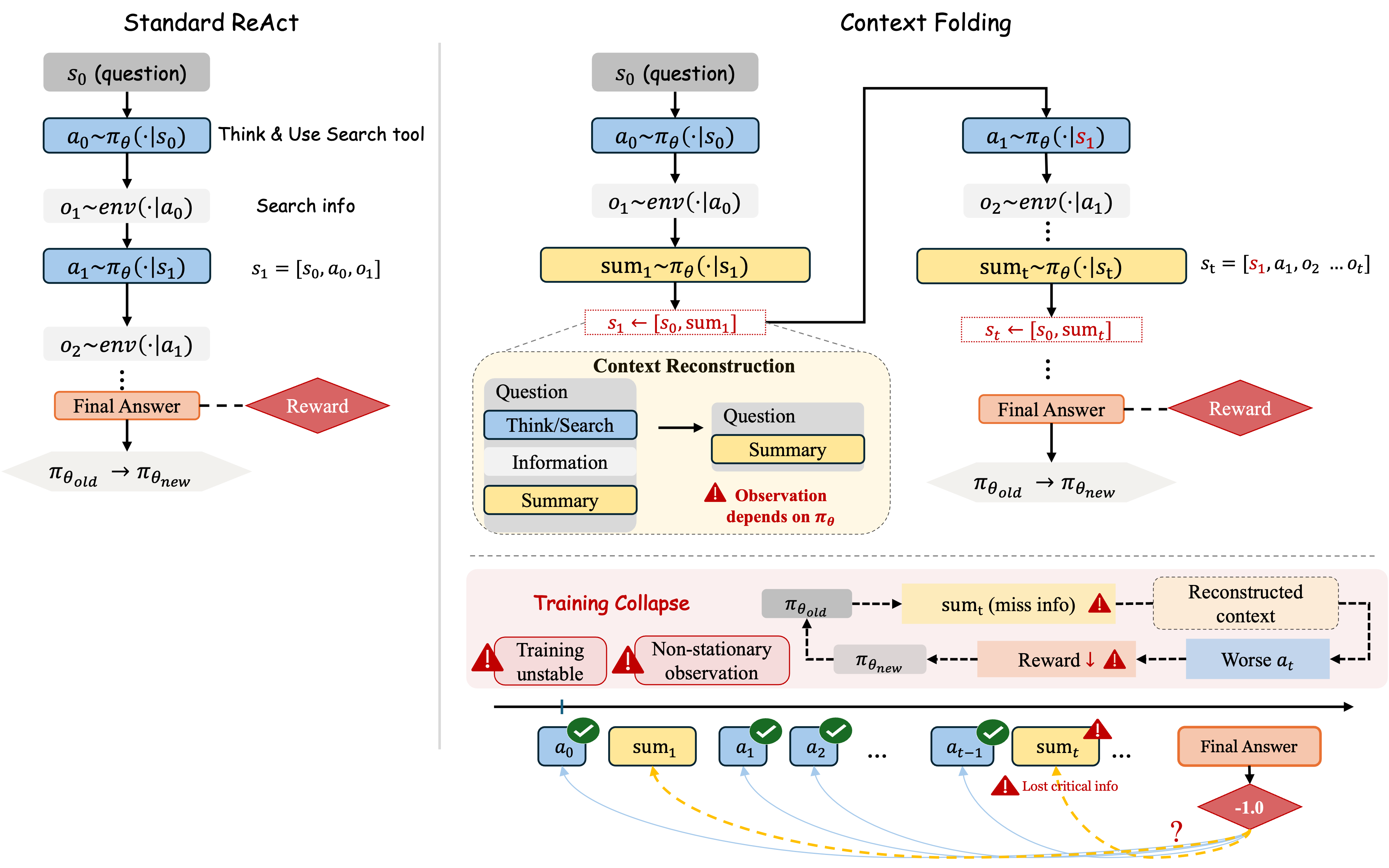
- 现有的上下文折叠方法未能有效处理摘要动作对观察空间的影响,导致训练信号不足和非平稳分布问题。
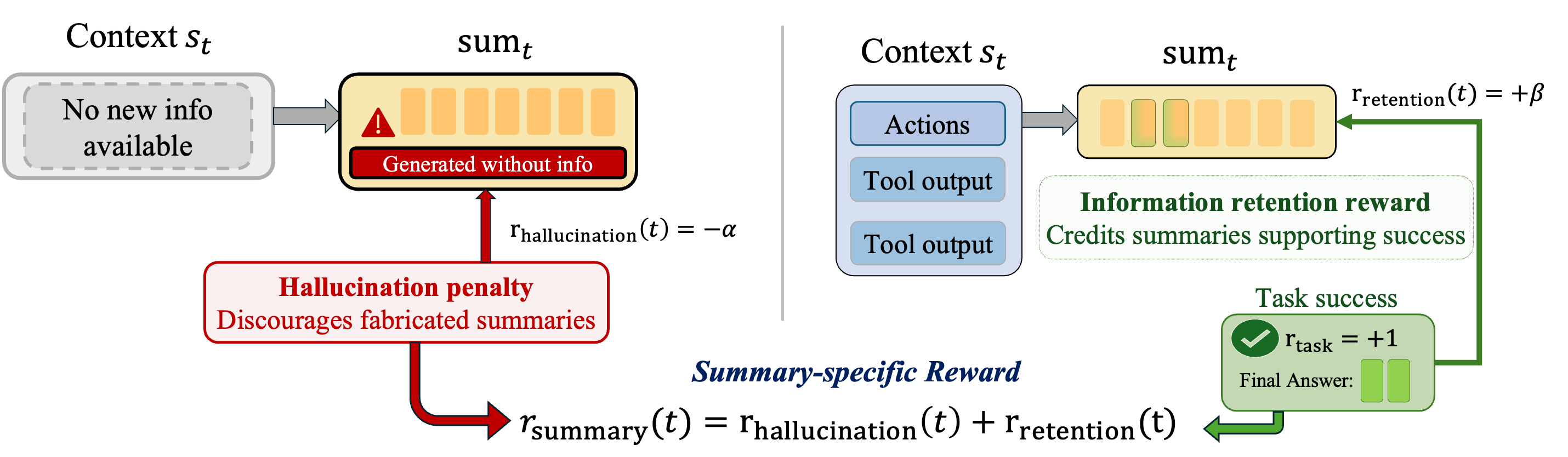
- FoldAct框架通过分离损失计算、上下文一致性损失和选择性段训练,解决了现有方法的核心挑战。
- 实验结果表明,FoldAct在长时间搜索任务中实现了5.19倍的训练速度提升,显著提高了训练效率和稳定性。
📝 摘要(中文)
长时间强化学习(RL)在大语言模型中面临着上下文增长的可扩展性挑战,导致在任务执行过程中需要压缩交互历史的上下文折叠方法。然而,现有方法将摘要动作视为标准动作,忽视了摘要根本上改变了代理的未来观察空间,导致策略依赖的非平稳观察分布,违反了核心RL假设。为此,本文提出了FoldAct框架,通过独立的损失计算、完整的上下文一致性损失和选择性段训练等三项关键创新,显著提高了长时间搜索代理的训练稳定性和效率,训练速度提升达5.19倍。
🔬 方法详解
问题定义:本文旨在解决长时间强化学习中上下文折叠方法的三个主要挑战:摘要动作的训练信号不足、策略更新导致的自我条件化以及处理独特上下文的高计算成本。
核心思路:FoldAct通过引入分离的损失计算和上下文一致性损失,确保摘要和动作的独立训练信号,从而减少观察分布的变化。
技术框架:FoldAct的整体架构包括三个主要模块:独立损失计算模块、上下文一致性损失模块和选择性段训练模块,确保训练过程的稳定性和高效性。
关键创新:FoldAct的核心创新在于通过分离损失计算和上下文一致性损失,解决了现有方法未能考虑的非平稳观察分布问题,显著提升了训练的稳定性。
关键设计:在损失函数设计上,FoldAct采用了针对摘要和动作的独立损失计算,并引入了上下文一致性损失以减少分布偏移,同时通过选择性段训练降低计算成本。具体参数设置和网络结构细节在实验部分进行了详细说明。
🖼️ 关键图片

📊 实验亮点
FoldAct在长时间搜索任务中实现了5.19倍的训练速度提升,相较于传统方法显著提高了训练效率和稳定性,解决了非平稳观察分布的问题,展现了其在强化学习中的应用潜力。
🎯 应用场景
FoldAct的研究成果在长时间强化学习任务中具有广泛的应用潜力,尤其是在需要处理大量上下文信息的自然语言处理、对话系统和机器人控制等领域。该方法的高效性和稳定性将推动相关领域的进一步发展,提升智能系统的决策能力和响应速度。
📄 摘要(原文)
Long-horizon reinforcement learning (RL) for large language models faces critical scalability challenges from unbounded context growth, leading to context folding methods that compress interaction history during task execution. However, existing approaches treat summary actions as standard actions, overlooking that summaries fundamentally modify the agent's future observation space, creating a policy-dependent, non-stationary observation distribution that violates core RL assumptions. This introduces three fundamental challenges: (1) gradient dilution where summary tokens receive insufficient training signal, (2) self-conditioning where policy updates change summary distributions, creating a vicious cycle of training collapse, and (3) computational cost from processing unique contexts at each turn. We introduce \textbf{FoldAct}\footnote{https://github.com/SHAO-Jiaqi757/FoldAct}, a framework that explicitly addresses these challenges through three key innovations: separated loss computation for independent gradient signals on summary and action tokens, full context consistency loss to reduce distribution shift, and selective segment training to reduce computational cost. Our method enables stable training of long-horizon search agents with context folding, addressing the non-stationary observation problem while improving training efficiency with 5.19$\times$ speedup.