AdaFRUGAL: Adaptive Memory-Efficient Training with Dynamic Control
作者: Quang-Hung Bui, Anh Son Ta
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-12-27
💡 一句话要点
AdaFRUGAL:通过动态控制实现自适应、内存高效的大模型训练
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 内存高效训练 梯度分割 动态控制 自适应优化
📋 核心要点
- 大型语言模型训练面临优化器状态带来的内存瓶颈,静态超参数的FRUGAL方法需要手动调优。
- AdaFRUGAL通过动态调整子空间比例和更新频率,自适应地降低内存占用和计算开销。
- 实验表明,AdaFRUGAL在保持性能的同时,显著减少了GPU内存使用和训练时间。
📝 摘要(中文)
训练大型语言模型(LLMs)由于优化器状态开销而需要大量内存。FRUGAL框架通过梯度分割缓解了这个问题,但其静态超参数——子空间比例($ρ$)和更新频率($T$)——需要耗费大量成本进行手动调整,限制了适应性。我们提出了AdaFRUGAL,它通过引入两个动态控制来自动化这个过程:(i)$ρ$的线性衰减,以逐步减少内存;(ii)$T$的损失感知调度,以降低计算开销。在大型预训练(English C4,Vietnamese VietVault)和微调(GLUE)上的实验表明,AdaFRUGAL实现了一个引人注目的权衡。它在与AdamW和静态FRUGAL相比保持了有竞争力的性能,同时显著减少了GPU内存和训练时间,为资源受限的LLM训练提供了一个更实用、自主的解决方案。
🔬 方法详解
问题定义:大型语言模型(LLMs)的训练对内存需求极高,这主要是由于优化器状态(如AdamW中的动量和方差)需要占用大量GPU内存。FRUGAL通过梯度分割来减少内存占用,但其子空间比例(ρ)和更新频率(T)是静态的,需要手动调整,这使得它在不同任务和数据集上的适应性较差。手动调参成本高昂,阻碍了FRUGAL的广泛应用。
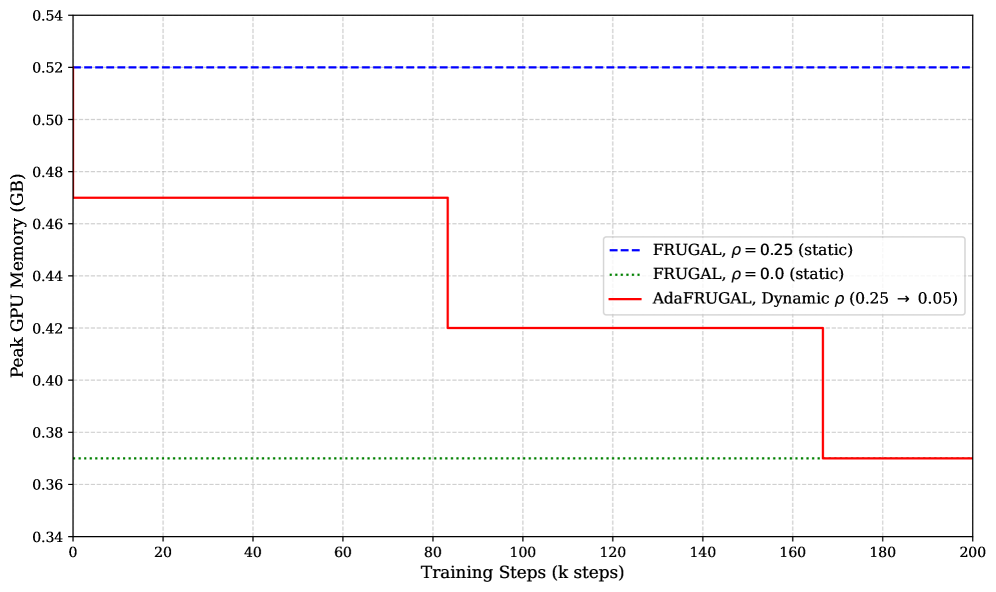
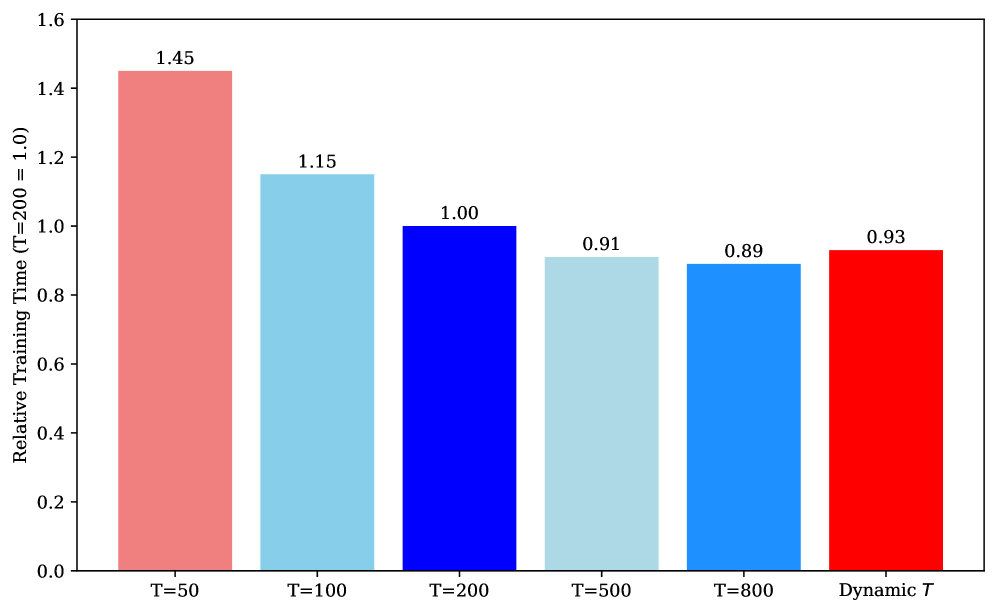
核心思路:AdaFRUGAL的核心思路是通过动态调整FRUGAL的两个关键超参数:子空间比例(ρ)和更新频率(T),使其能够自适应地应对不同的训练阶段和任务。具体来说,它采用线性衰减策略来逐渐减小ρ,从而在训练过程中逐步降低内存占用。同时,它使用损失感知调度来动态调整T,使得在损失变化剧烈的阶段更频繁地更新,而在损失变化平缓的阶段减少更新频率,从而降低计算开销。
技术框架:AdaFRUGAL沿用了FRUGAL的梯度分割框架,主要包括以下几个阶段:1. 梯度分割:将梯度投影到低维子空间中。2. 子空间更新:在低维子空间中更新模型参数。3. 全空间更新:将子空间中的更新映射回全空间。AdaFRUGAL的关键改进在于对子空间比例ρ和更新频率T的动态控制。ρ采用线性衰减策略,从初始值逐渐减小到目标值。T采用损失感知调度,根据损失变化率动态调整更新频率。
关键创新:AdaFRUGAL最关键的创新在于引入了动态控制机制,使得FRUGAL能够自适应地调整子空间比例和更新频率,从而在内存占用、计算开销和模型性能之间取得更好的平衡。与静态FRUGAL相比,AdaFRUGAL无需手动调参,降低了使用门槛。与AdamW相比,AdaFRUGAL显著减少了内存占用和训练时间。
关键设计:AdaFRUGAL的关键设计包括:1. 子空间比例(ρ)的线性衰减策略:ρ = ρ_initial - (ρ_initial - ρ_final) * (step / total_steps)。2. 更新频率(T)的损失感知调度:T = f(loss_change_rate),其中f是一个单调递减函数。损失变化率可以通过计算损失的移动平均来估计。具体的函数形式和参数设置需要根据具体任务进行调整。
🖼️ 关键图片
📊 实验亮点
实验结果表明,AdaFRUGAL在大型预训练(English C4,Vietnamese VietVault)和微调(GLUE)任务上,与AdamW和静态FRUGAL相比,在保持竞争力的性能的同时,显著减少了GPU内存占用和训练时间。具体的数据提升幅度未知,但摘要强调了其“引人注目的权衡”。
🎯 应用场景
AdaFRUGAL适用于资源受限场景下的大型语言模型训练,例如在GPU内存有限的设备上进行预训练和微调。该方法可以降低训练成本,加速模型迭代,并促进LLM在边缘设备上的部署。此外,AdaFRUGAL的自适应特性使其能够更好地适应不同的数据集和任务,提高模型的泛化能力。
📄 摘要(原文)
Training Large Language Models (LLMs) is highly memory-intensive due to optimizer state overhead. The FRUGAL framework mitigates this with gradient splitting, but its static hyperparameters -- the subspace ratio ($ρ$) and update frequency ($T$) -- require costly manual tuning, limiting adaptability. We present AdaFRUGAL, which automates this process by introducing two dynamic controls: (i) a linear decay for $ρ$ to progressively reduce memory, and (ii) a loss-aware schedule for $T$ to lower computational overhead. Experiments across large-scale pre-training (English C4, Vietnamese VietVault) and fine-tuning (GLUE) demonstrate that AdaFRUGAL achieves a compelling trade-off. It maintains competitive performance against AdamW and static FRUGAL while significantly reducing both GPU memory and training time, offering a more practical, autonomous solution for resource-constrained LLM training.