Scaling Unverifiable Rewards: A Case Study on Visual Insights
作者: Shuyu Gan, James Mooney, Pan Hao, Renxiang Wang, Mingyi Hong, Qianwen Wang, Dongyeop Kang
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-12-27
备注: 32 pages, 25 figures
💡 一句话要点
提出Selective TTS,通过阶段性推理优化解决不可验证奖励下的多阶段任务。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多阶段推理 测试时缩放 LLM代理 奖励信号 数据科学 视觉洞察 判断模型
📋 核心要点
- 现有方法在不可验证奖励的多阶段任务中,由于缺乏可靠的奖励信号,容易导致判断漂移和误差累积。
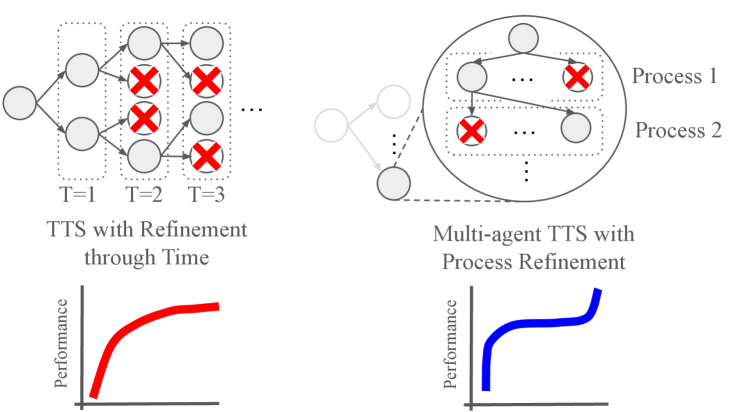
- Selective TTS通过在多代理流程的不同阶段分配计算资源,并尽早修剪低质量分支,减轻判断漂移。
- 实验表明,Selective TTS在固定计算预算下提高了洞察力质量,平均得分从61.64提升至65.86,并降低了方差。
📝 摘要(中文)
大型语言模型(LLM)代理越来越多地通过测试时缩放(TTS)实现复杂推理的自动化,这种方法通过奖励信号指导迭代优化。然而,许多现实世界的任务涉及多阶段流程,其最终结果缺乏可验证的奖励或足够的数据来训练鲁棒的奖励模型,使得基于判断的优化容易在各个阶段累积误差。我们提出了选择性TTS,一种基于过程的优化框架,它在多代理流程的不同阶段扩展推理,而不是像先前的工作那样重复优化。通过在各个阶段分配计算资源,并使用特定于过程的判断器尽早修剪低质量的分支,选择性TTS减轻了判断漂移并稳定了优化。以数据科学流程为基础,我们构建了一个端到端的、用于生成具有视觉洞察力的图表和数据集报告的多代理流程,并设计了一个可靠的、与人类专家对齐的基于LLM的判断模型(Kendall's τ=0.55)。我们提出的选择性TTS在固定的计算预算下提高了洞察力质量,平均得分从61.64提高到65.86,同时降低了方差。我们希望我们的发现能够成为扩展复杂、开放式任务(如科学发现和故事生成)的第一步,这些任务具有不可验证的奖励。
🔬 方法详解
问题定义:论文旨在解决在多阶段任务中,由于奖励信号不可靠或难以验证,导致LLM代理难以进行有效迭代优化的问题。现有方法通常采用重复优化策略,但这种策略容易受到判断漂移的影响,尤其是在任务的早期阶段,错误的判断会导致后续阶段的努力付诸东流。
核心思路:论文的核心思路是将计算资源分配到多阶段流程的不同阶段,而不是集中在重复的迭代优化上。通过在每个阶段使用特定于该阶段的判断器对结果进行评估,并尽早修剪低质量的分支,可以有效地减少判断漂移,并提高整体性能。这种方法类似于在搜索树中进行剪枝,避免了对无希望分支的进一步探索。
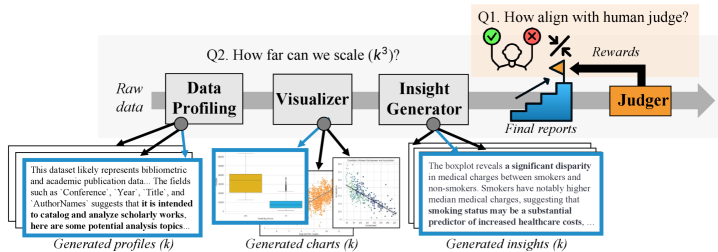
技术框架:整体框架是一个多代理流程,每个代理负责完成数据科学流程中的一个特定阶段,例如数据清洗、特征工程、可视化等。Selective TTS的关键在于在每个阶段之后引入一个判断模块,该模块使用LLM对当前阶段的结果进行评估,并根据评估结果决定是否继续进行后续阶段的处理。框架包含以下主要模块:数据输入模块、多阶段代理模块、判断模块和结果输出模块。
关键创新:最重要的技术创新点是Selective TTS的阶段性推理和早期剪枝策略。与传统的重复优化方法不同,Selective TTS将计算资源分配到不同的阶段,并在每个阶段进行评估和剪枝,从而避免了对低质量分支的过度投入。这种方法能够更有效地利用计算资源,并提高整体性能。
关键设计:判断模块的设计是Selective TTS的关键。论文使用LLM作为判断器,并针对每个阶段的任务特点设计了特定的提示语。为了提高判断器的可靠性,论文还使用了人类专家的数据对LLM进行了微调。此外,论文还探索了不同的剪枝策略,例如基于置信度的剪枝和基于阈值的剪枝,以找到最佳的性能平衡。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Selective TTS在生成具有视觉洞察力的图表和数据集报告的任务中,在固定计算预算下,将平均得分从61.64提高到65.86,同时降低了方差。此外,论文还验证了LLM判断器与人类专家具有较高的一致性(Kendall's τ=0.55),表明该方法具有较强的可靠性。
🎯 应用场景
该研究成果可应用于各种需要多阶段推理和决策的任务,例如科学发现、故事生成、软件开发等。通过将任务分解为多个阶段,并在每个阶段进行评估和优化,可以有效地提高任务的完成质量和效率。该方法尤其适用于那些奖励信号难以验证或获取的任务。
📄 摘要(原文)
Large Language Model (LLM) agents can increasingly automate complex reasoning through Test-Time Scaling (TTS), iterative refinement guided by reward signals. However, many real-world tasks involve multi-stage pipeline whose final outcomes lack verifiable rewards or sufficient data to train robust reward models, making judge-based refinement prone to accumulate error over stages. We propose Selective TTS, a process-based refinement framework that scales inference across different stages in multi-agent pipeline, instead of repeated refinement over time by prior work. By distributing compute across stages and pruning low-quality branches early using process-specific judges, Selective TTS mitigates the judge drift and stabilizes refinement. Grounded in the data science pipeline, we build an end-to-end multi-agent pipeline for generating visually insightful charts and report of given dataset, and design a reliable LLM-based judge model, aligned with human experts (Kendall's τ=0.55). Our proposed selective TTS then improves insight quality under a fixed compute budget, increasing mean scores from 61.64 to 65.86 while reducing variance. We hope our findings serve as the first step toward to scaling complex, open-ended tasks with unverifiable rewards, such as scientific discovery and story generation.