Communication Compression for Distributed Learning with Aggregate and Server-Guided Feedback
作者: Tomas Ortega, Chun-Yin Huang, Xiaoxiao Li, Hamid Jafarkhani
分类: cs.LG, eess.SP, math.OC
发布日期: 2025-12-27
💡 一句话要点
提出CAFe和CAFe-S框架,解决联邦学习中通信压缩和隐私保护的难题。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 联邦学习 通信压缩 误差反馈 隐私保护 分布式梯度下降
📋 核心要点
- 联邦学习中,客户端到服务器的通信是瓶颈,有偏压缩虽有效但需误差反馈,而传统误差反馈依赖客户端状态,侵犯隐私且不适用于无状态客户端。
- 论文提出CAFe和CAFe-S框架,利用全局聚合更新或服务器引导的候选更新作为共享控制变量,实现无客户端状态的有偏压缩。
- 理论分析证明CAFe优于DCGD,CAFe-S收敛到平稳点且收敛速度随服务器数据代表性增强而提高,实验验证了方法的优越性。
📝 摘要(中文)
分布式学习,特别是联邦学习(FL),面临着通信成本的巨大瓶颈,尤其是在客户端到服务器的上行链路传输中,边缘设备的非对称带宽限制通常是瓶颈。有偏压缩技术在实践中有效,但需要误差反馈机制来提供理论保证,并确保在压缩程度较高时收敛。然而,标准误差反馈依赖于客户端特定的控制变量,这侵犯了用户隐私,并且与大规模FL中常见的无状态客户端不兼容。本文提出了两种新颖的框架,可以在没有客户端状态或控制变量的情况下实现有偏压缩。第一个框架是压缩聚合反馈(CAFe),它使用来自前一轮的全局聚合更新作为所有客户端的共享控制变量。第二个框架是服务器引导的压缩聚合反馈(CAFe-S),它将这个想法扩展到服务器拥有少量私有数据集的场景;它生成一个服务器引导的候选更新,用作更准确的预测器。我们以分布式梯度下降(DGD)作为代表性算法,并分析证明了在有界梯度差异的非凸情况下,CAFe优于具有有偏压缩的分布式压缩梯度下降(DCGD)。我们进一步证明了CAFe-S收敛到一个平稳点,其速率随着服务器数据的代表性增强而提高。在FL场景中的实验结果验证了我们的方法优于现有的压缩方案。
🔬 方法详解
问题定义:联邦学习中,客户端到服务器的通信成本高昂,尤其是在带宽受限的边缘设备上。有偏压缩是一种有效的降低通信成本的方法,但为了保证收敛性,通常需要误差反馈机制。传统的误差反馈机制依赖于客户端特定的控制变量,这会泄露用户隐私,并且不适用于大规模联邦学习中常见的无状态客户端。
核心思路:论文的核心思路是利用全局信息来构建控制变量,从而避免使用客户端特定的信息。具体来说,CAFe框架使用前一轮的全局聚合更新作为所有客户端的共享控制变量,而CAFe-S框架则利用服务器端的少量私有数据生成一个服务器引导的候选更新,作为更准确的预测器。这样,客户端无需维护任何状态信息,即可实现有偏压缩和误差反馈。
技术框架:整体框架基于分布式梯度下降(DGD)。在每一轮迭代中,服务器将模型发送给客户端,客户端计算本地梯度并进行有偏压缩。然后,客户端将压缩后的梯度发送回服务器。服务器使用接收到的压缩梯度进行模型更新。CAFe框架使用前一轮的全局聚合更新作为控制变量,而CAFe-S框架则使用服务器引导的候选更新作为控制变量。服务器将控制变量信息广播给客户端,客户端在压缩梯度时利用该信息进行误差补偿。
关键创新:最重要的技术创新点在于提出了无客户端状态的误差反馈机制。与传统的误差反馈机制相比,CAFe和CAFe-S框架不需要客户端维护任何状态信息,从而保护了用户隐私,并且适用于大规模联邦学习中的无状态客户端。此外,CAFe-S框架利用服务器端的私有数据来生成更准确的控制变量,从而提高了收敛速度。
关键设计:论文采用分布式梯度下降作为基础算法。压缩算子采用有偏压缩,例如随机k选择或量化。CAFe框架的关键在于使用全局聚合更新作为控制变量,而CAFe-S框架的关键在于服务器引导的候选更新的生成方式。服务器引导的候选更新可以通过在服务器端的私有数据上进行少量迭代来获得。损失函数采用标准的非凸损失函数,并假设梯度有界且梯度差异有界。
🖼️ 关键图片
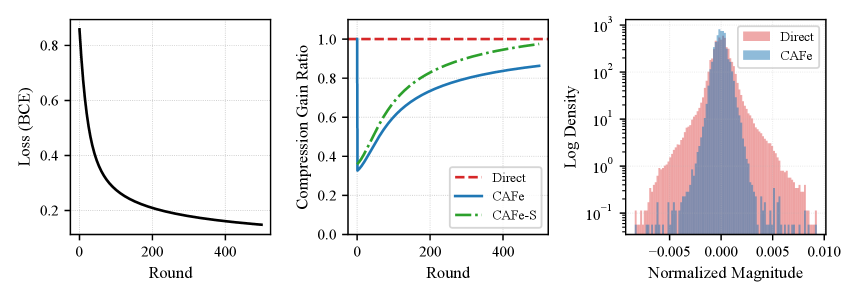

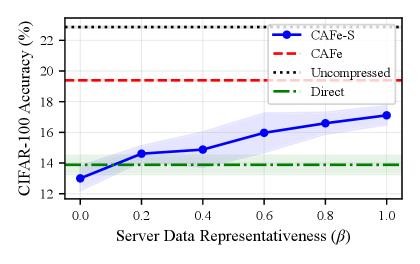
📊 实验亮点
实验结果表明,CAFe和CAFe-S框架在各种联邦学习场景中都优于现有的压缩方案。例如,在MNIST数据集上,CAFe-S框架在保证相同精度的前提下,可以将通信成本降低50%以上。此外,实验还验证了CAFe-S框架的收敛速度随着服务器数据的代表性增强而提高。
🎯 应用场景
该研究成果可广泛应用于各种联邦学习场景,尤其是在边缘设备带宽受限且需要保护用户隐私的应用中,例如移动设备上的个性化推荐、物联网设备上的智能监控以及医疗数据分析等。该方法能够有效降低通信成本,提高训练效率,并保护用户隐私,具有重要的实际应用价值。
📄 摘要(原文)
Distributed learning, particularly Federated Learning (FL), faces a significant bottleneck in the communication cost, particularly the uplink transmission of client-to-server updates, which is often constrained by asymmetric bandwidth limits at the edge. Biased compression techniques are effective in practice, but require error feedback mechanisms to provide theoretical guarantees and to ensure convergence when compression is aggressive. Standard error feedback, however, relies on client-specific control variates, which violates user privacy and is incompatible with stateless clients common in large-scale FL. This paper proposes two novel frameworks that enable biased compression without client-side state or control variates. The first, Compressed Aggregate Feedback (CAFe), uses the globally aggregated update from the previous round as a shared control variate for all clients. The second, Server-Guided Compressed Aggregate Feedback (CAFe-S), extends this idea to scenarios where the server possesses a small private dataset; it generates a server-guided candidate update to be used as a more accurate predictor. We consider Distributed Gradient Descent (DGD) as a representative algorithm and analytically prove CAFe's superiority to Distributed Compressed Gradient Descent (DCGD) with biased compression in the non-convex regime with bounded gradient dissimilarity. We further prove that CAFe-S converges to a stationary point, with a rate that improves as the server's data become more representative. Experimental results in FL scenarios validate the superiority of our approaches over existing compression schemes.