The Bayesian Geometry of Transformer Attention
作者: Naman Agarwal, Siddhartha R. Dalal, Vishal Misra
分类: cs.LG, cs.AI, stat.ML
发布日期: 2025-12-27 (更新: 2026-01-27)
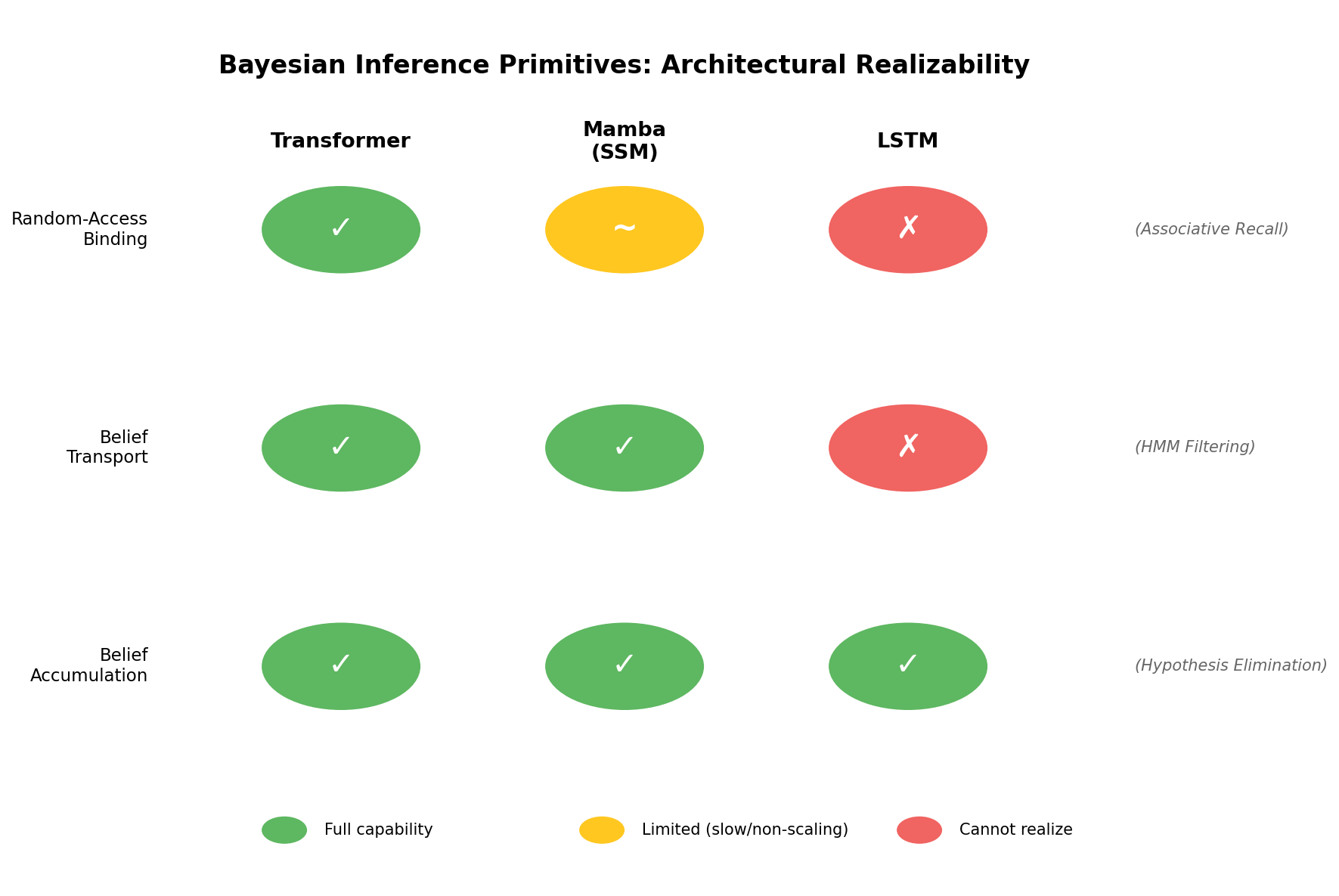
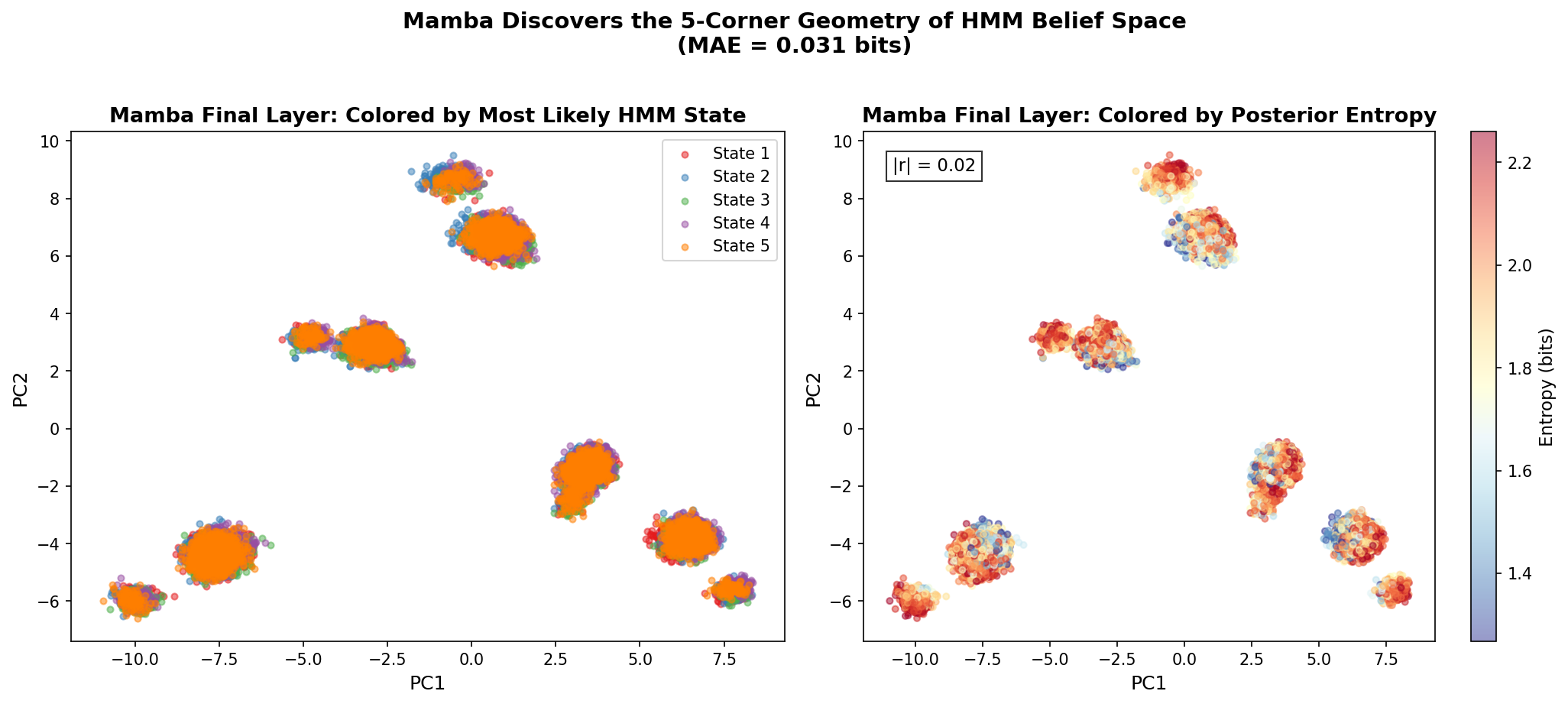
备注: Added inference primitives taxonomy (accumulation, transport, binding). New associative recall task. Complete Mamba/LSTM comparison with multi-seed results. KL/TVD verification table. Mamba 5-cluster geometry analysis. Layer/head ablation figures. Content-based routing as unifying principle
💡 一句话要点
Transformer通过几何机制实现贝叶斯推理,显著优于MLP
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Transformer 贝叶斯推理 注意力机制 几何表示 可解释性 机器学习 深度学习
📋 核心要点
- 自然数据和大型模型难以分离推理与记忆,阻碍了Transformer贝叶斯推理能力的验证。
- 构建“贝叶斯风洞”,在可控环境中验证Transformer的贝叶斯推理能力,并排除记忆的影响。
- 实验表明,Transformer能高精度重现贝叶斯后验,并通过几何机制实现,显著优于MLP。
📝 摘要(中文)
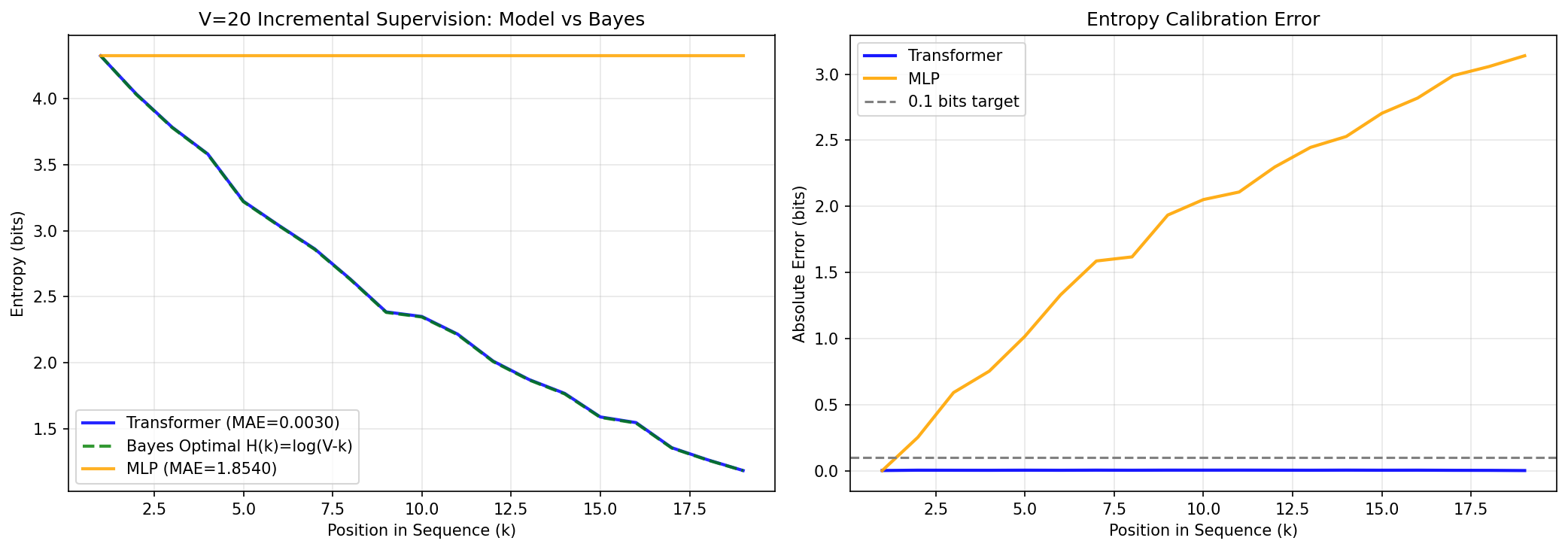
Transformer模型通常表现出在上下文中进行贝叶斯推理的能力,但由于自然数据缺乏解析后验以及大型模型将推理与记忆混淆,因此无法严格验证。本文构建了“贝叶斯风洞”——一种真实后验以闭合形式已知且记忆不可能发生的可控环境。在这种环境中,小型Transformer以$10^{-3}$-$10^{-4}$比特的精度重现贝叶斯后验,而容量匹配的MLP则失败几个数量级,从而建立了清晰的架构分离。在双射消除和隐马尔可夫模型(HMM)状态跟踪两个任务中,我们发现Transformer通过一致的几何机制实现贝叶斯推理:残差流作为信念基底,前馈网络执行后验更新,注意力提供内容可寻址路由。几何诊断揭示了正交键基、渐进式查询-键对齐以及由后验熵参数化的低维值流形。在训练过程中,该流形展开,而注意力模式保持稳定,这是一种近期梯度分析预测的“帧-精度解离”。总而言之,这些结果表明,分层注意力通过几何设计实现贝叶斯推理,解释了注意力的必要性和扁平架构的失败。贝叶斯风洞为将小型、可验证系统与大型语言模型中观察到的推理现象进行机械连接奠定了基础。
🔬 方法详解
问题定义:现有方法难以验证Transformer是否真正进行贝叶斯推理,因为自然数据缺乏解析后验,并且大型模型容易通过记忆来解决问题,而非真正的推理。这使得我们无法区分Transformer是在进行贝叶斯推理,还是仅仅在记忆训练数据。
核心思路:本文的核心思路是构建一个可控的环境,即“贝叶斯风洞”,在这个环境中,真实的后验概率是已知的,并且可以排除模型通过记忆来解决问题的可能性。通过观察Transformer在这一环境中的表现,可以更清晰地了解其是否以及如何进行贝叶斯推理。
技术框架:该研究的技术框架主要包括以下几个部分:1) 构建“贝叶斯风洞”,设计具有已知解析后验的特定任务,例如双射消除和隐马尔可夫模型(HMM)状态跟踪。2) 使用小型Transformer模型和容量匹配的MLP模型在这些任务上进行训练和测试。3) 通过几何诊断工具,分析Transformer内部的表示和计算过程,例如残差流、注意力模式和值流形。4) 比较Transformer和MLP在重现贝叶斯后验方面的性能,并分析其差异。
关键创新:该研究的关键创新在于:1) 提出了“贝叶斯风洞”的概念,为研究模型的贝叶斯推理能力提供了一个可控的环境。2) 揭示了Transformer通过几何机制实现贝叶斯推理,包括残差流作为信念基底,前馈网络执行后验更新,注意力提供内容可寻址路由。3) 发现了“帧-精度解离”现象,即训练过程中值流形展开,而注意力模式保持稳定。
关键设计:在“贝叶斯风洞”的设计中,关键在于确保后验概率的解析可计算性,并排除记忆的可能性。在Transformer模型的设计中,使用了标准的多头注意力机制和残差连接。实验中,对Transformer和MLP进行了容量匹配,以确保公平比较。损失函数采用交叉熵损失,优化器采用Adam。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在“贝叶斯风洞”中,小型Transformer能够以$10^{-3}$-$10^{-4}$比特的精度重现贝叶斯后验,而容量匹配的MLP则失败几个数量级。这表明Transformer在贝叶斯推理方面具有显著的架构优势。此外,几何诊断揭示了Transformer内部的几何机制,为理解其推理过程提供了新的视角。
🎯 应用场景
该研究成果有助于理解大型语言模型中的推理机制,并为设计更高效、更可靠的AI系统提供指导。潜在应用领域包括:开发具有更强推理能力的AI助手、改进机器人导航和决策系统、以及在金融和医疗等领域进行更准确的风险评估和预测。
📄 摘要(原文)
Transformers often appear to perform Bayesian reasoning in context, but verifying this rigorously has been impossible: natural data lack analytic posteriors, and large models conflate reasoning with memorization. We address this by constructing \emph{Bayesian wind tunnels} -- controlled environments where the true posterior is known in closed form and memorization is provably impossible. In these settings, small transformers reproduce Bayesian posteriors with $10^{-3}$-$10^{-4}$ bit accuracy, while capacity-matched MLPs fail by orders of magnitude, establishing a clear architectural separation. Across two tasks -- bijection elimination and Hidden Markov Model (HMM) state tracking -- we find that transformers implement Bayesian inference through a consistent geometric mechanism: residual streams serve as the belief substrate, feed-forward networks perform the posterior update, and attention provides content-addressable routing. Geometric diagnostics reveal orthogonal key bases, progressive query-key alignment, and a low-dimensional value manifold parameterized by posterior entropy. During training this manifold unfurls while attention patterns remain stable, a \emph{frame-precision dissociation} predicted by recent gradient analyses. Taken together, these results demonstrate that hierarchical attention realizes Bayesian inference by geometric design, explaining both the necessity of attention and the failure of flat architectures. Bayesian wind tunnels provide a foundation for mechanistically connecting small, verifiable systems to reasoning phenomena observed in large language models.