LLMBoost: Make Large Language Models Stronger with Boosting
作者: Zehao Chen, Tianxiang Ai, Yifei Li, Gongxun Li, Yuyang Wei, Wang Zhou, Guanghui Li, Bin Yu, Zhijun Chen, Hailong Sun, Fuzhen Zhuang, Jianxin Li, Deqing Wang, Yikun Ban
分类: cs.LG, cs.AI
发布日期: 2025-12-26
💡 一句话要点
LLMBoost:通过Boosting方法增强大型语言模型性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 集成学习 Boosting 跨模型注意力 链式训练
📋 核心要点
- 现有LLM集成方法通常将模型视为黑盒,忽略了模型内部表示和交互,限制了性能提升。
- LLMBoost通过跨模型注意力、链式训练和近并行推理,显式利用LLM中间状态,实现分层错误纠正和知识迁移。
- 实验表明,LLMBoost在常识推理和算术推理任务上,显著提升了准确率,并降低了推理延迟。
📝 摘要(中文)
本文提出了一种新颖的集成微调框架LLMBoost,旨在打破现有LLM集成方法将模型视为黑盒的局限性。LLMBoost显式地利用LLM的中间状态,受到boosting范式的启发,包含三个关键创新:跨模型注意力机制,使后续模型能够访问和融合先前模型的隐藏状态,从而促进分层错误纠正和知识转移;链式训练范式,通过误差抑制目标逐步微调连接的模型,确保每个模型纠正其前任模型的错误预测,同时最小化额外的计算;近乎并行的推理范式,逐层流水线化跨模型的隐藏状态,实现接近单模型解码的推理效率。论文还建立了LLMBoost的理论基础,证明了在有界校正假设下,顺序集成保证单调改进。在常识推理和算术推理任务上的大量实验表明,LLMBoost能够持续提高准确率,同时降低推理延迟。
🔬 方法详解
问题定义:现有的大型语言模型集成方法通常将各个模型视为黑盒,仅仅组合它们的输入或最终输出,而忽略了模型内部丰富的中间层表示以及模型之间的交互信息。这种做法限制了集成学习的潜力,无法充分利用不同模型的优势来纠正彼此的错误。因此,如何有效地利用LLM的中间状态,实现更高效、更强大的模型集成是本文要解决的核心问题。
核心思路:LLMBoost的核心思路是借鉴boosting算法的思想,通过构建一个由多个LLM组成的链式结构,让每个后续模型都专注于纠正先前模型的错误。具体来说,LLMBoost通过跨模型注意力机制,允许后续模型访问并融合先前模型的隐藏状态,从而实现分层错误纠正和知识迁移。此外,LLMBoost还设计了一种链式训练范式,以误差抑制为目标,逐步微调连接的模型,确保每个模型都能有效地纠正其前任模型的错误预测。
技术框架:LLMBoost的整体框架包含三个主要组成部分:1) 跨模型注意力机制:允许后续模型访问并融合先前模型的隐藏状态。2) 链式训练范式:以误差抑制为目标,逐步微调连接的模型。3) 近并行推理范式:逐层流水线化跨模型的隐藏状态,实现高效推理。在训练阶段,首先训练第一个模型,然后依次训练后续模型,每个模型都以前一个模型的输出作为输入,并利用跨模型注意力机制来访问前一个模型的隐藏状态。在推理阶段,采用近并行推理范式,逐层流水线化跨模型的隐藏状态,从而提高推理效率。
关键创新:LLMBoost的关键创新在于其显式地利用了LLM的中间状态,并通过跨模型注意力机制实现了模型之间的信息交互。与传统的黑盒集成方法不同,LLMBoost能够充分利用不同模型的优势,实现更高效的错误纠正和知识迁移。此外,LLMBoost的链式训练范式和近并行推理范式也为模型集成带来了更高的效率和可扩展性。
关键设计:LLMBoost的关键设计包括:1) 跨模型注意力机制:采用标准的注意力机制,将先前模型的隐藏状态作为Key和Value,当前模型的隐藏状态作为Query,计算注意力权重,并将加权后的隐藏状态融合到当前模型的隐藏状态中。2) 误差抑制损失函数:设计了一种特殊的损失函数,鼓励后续模型专注于纠正先前模型的错误预测。3) 近并行推理范式:通过流水线化跨模型的隐藏状态,实现了接近单模型解码的推理效率。具体的参数设置和网络结构取决于所使用的LLM架构。
🖼️ 关键图片


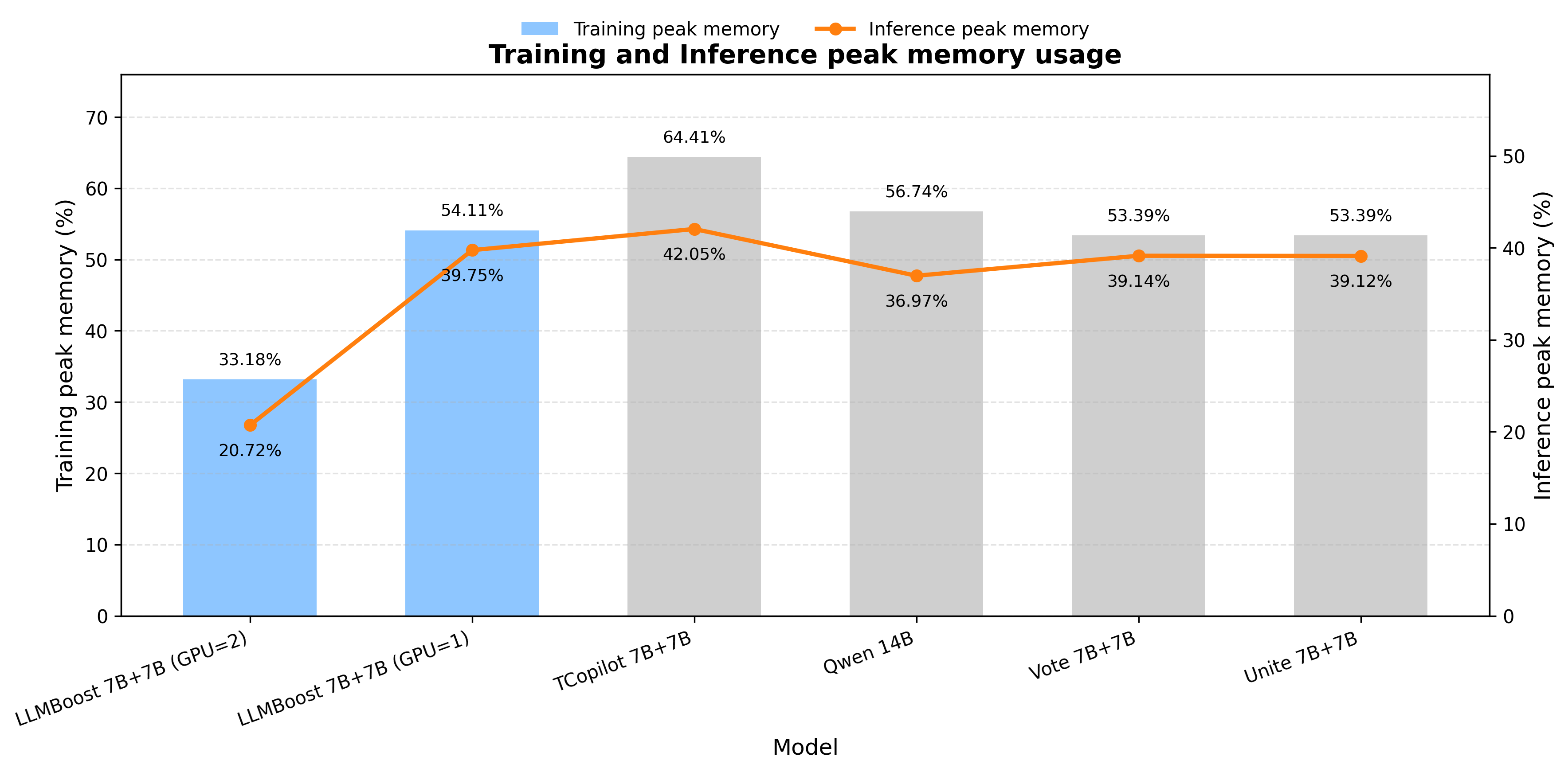
📊 实验亮点
LLMBoost在常识推理和算术推理任务上取得了显著的性能提升。在多个数据集上,LLMBoost的准确率均超过了现有的基线方法,并且在某些情况下,提升幅度达到了5%以上。此外,LLMBoost的推理延迟也显著降低,接近单模型解码的效率。这些实验结果充分证明了LLMBoost的有效性和优越性。
🎯 应用场景
LLMBoost具有广泛的应用前景,可以应用于各种需要高性能和高效率的自然语言处理任务,例如:智能客服、机器翻译、文本摘要、问答系统等。通过LLMBoost,可以显著提升这些应用的性能,并降低推理延迟,从而提高用户体验。此外,LLMBoost还可以作为一种通用的模型集成框架,应用于其他领域,例如:计算机视觉、语音识别等。
📄 摘要(原文)
Ensemble learning of LLMs has emerged as a promising alternative to enhance performance, but existing approaches typically treat models as black boxes, combining the inputs or final outputs while overlooking the rich internal representations and interactions across models.In this work, we introduce LLMBoost, a novel ensemble fine-tuning framework that breaks this barrier by explicitly leveraging intermediate states of LLMs. Inspired by the boosting paradigm, LLMBoost incorporates three key innovations. First, a cross-model attention mechanism enables successor models to access and fuse hidden states from predecessors, facilitating hierarchical error correction and knowledge transfer. Second, a chain training paradigm progressively fine-tunes connected models with an error-suppression objective, ensuring that each model rectifies the mispredictions of its predecessor with minimal additional computation. Third, a near-parallel inference paradigm design pipelines hidden states across models layer by layer, achieving inference efficiency approaching single-model decoding. We further establish the theoretical foundations of LLMBoost, proving that sequential integration guarantees monotonic improvements under bounded correction assumptions. Extensive experiments on commonsense reasoning and arithmetic reasoning tasks demonstrate that LLMBoost consistently boosts accuracy while reducing inference latency.