Semiparametric Preference Optimization: Your Language Model is Secretly a Single-Index Model
作者: Nathan Kallus
分类: cs.LG, cs.AI, econ.EM, stat.ML
发布日期: 2025-12-26 (更新: 2026-02-02)
🔗 代码/项目: GITHUB
💡 一句话要点
提出半参数偏好优化方法,解决LLM偏好对齐中链接函数未知问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 偏好对齐 大型语言模型 半参数模型 单指标模型 奖励函数 策略优化 链接函数
📋 核心要点
- 现有LLM偏好对齐方法依赖于预定义的链接函数,可能因函数设定错误导致奖励偏差和策略错位。
- 论文提出半参数单指标模型,无需预先指定链接函数,通过策略相关的指标捕获偏好依赖关系。
- 该方法开发了对未知链接鲁棒的偏好优化算法,并在LLM对齐任务上验证了其有效性。
📝 摘要(中文)
将大型语言模型(LLM)与偏好数据对齐通常假设观察到的偏好和潜在奖励之间存在已知的链接函数(例如,logistic Bradley-Terry链接)。这种链接函数的错误设定会偏差推断出的奖励,并使学习到的策略错位。本文研究了在未知和不受限制的链接函数下的偏好对齐。我们证明了在策略类中,受f-散度约束的奖励最大化的可实现性会诱导一个半参数单指标二元选择模型,其中一个标量策略相关的指标捕获了所有对演示的依赖,而剩余的偏好分布是不受限制的。与计量经济学中假设该模型具有可识别的有限维结构参数并估计它们不同,我们专注于奖励函数隐式的策略学习,分析了到最优策略的误差,并允许不可识别的非参数指标。我们开发了对未知链接具有鲁棒性的偏好优化算法,并证明了在通用函数复杂度度量方面的收敛性保证。我们在LLM对齐上进行了实证演示。代码可在https://github.com/causalml/spo/ 获取。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)偏好对齐方法通常假设观察到的偏好和潜在奖励之间存在一个已知的链接函数,例如logistic Bradley-Terry模型。然而,这种链接函数的选择往往是主观的,如果选择不当,会导致推断出的奖励函数出现偏差,进而影响学习到的策略的性能。因此,如何在链接函数未知的情况下进行有效的偏好对齐是一个重要的挑战。
核心思路:论文的核心思路是利用半参数单指标模型来解决链接函数未知的问题。该模型将策略相关的指标作为所有偏好依赖的载体,而偏好分布的剩余部分则不受限制。通过这种方式,模型不再依赖于预先设定的链接函数,而是从数据中学习偏好关系。
技术框架:该方法的技术框架主要包括以下几个步骤:首先,假设在策略类中,受f-散度约束的奖励最大化是可实现的。然后,证明这种可实现性会诱导一个半参数单指标二元选择模型。接着,开发对未知链接具有鲁棒性的偏好优化算法。最后,分析算法到最优策略的误差,并允许不可识别的非参数指标。
关键创新:该方法最重要的技术创新点在于它避免了对链接函数的预先设定,而是通过半参数单指标模型来学习偏好关系。与传统的计量经济学方法不同,该方法不假设模型具有可识别的有限维结构参数,而是专注于奖励函数隐式的策略学习。
关键设计:关键设计包括:1) 使用f-散度约束来控制奖励函数的范围;2) 开发对未知链接具有鲁棒性的偏好优化算法,例如基于梯度下降或进化算法的优化方法;3) 分析算法的收敛性,并提供理论保证。
🖼️ 关键图片
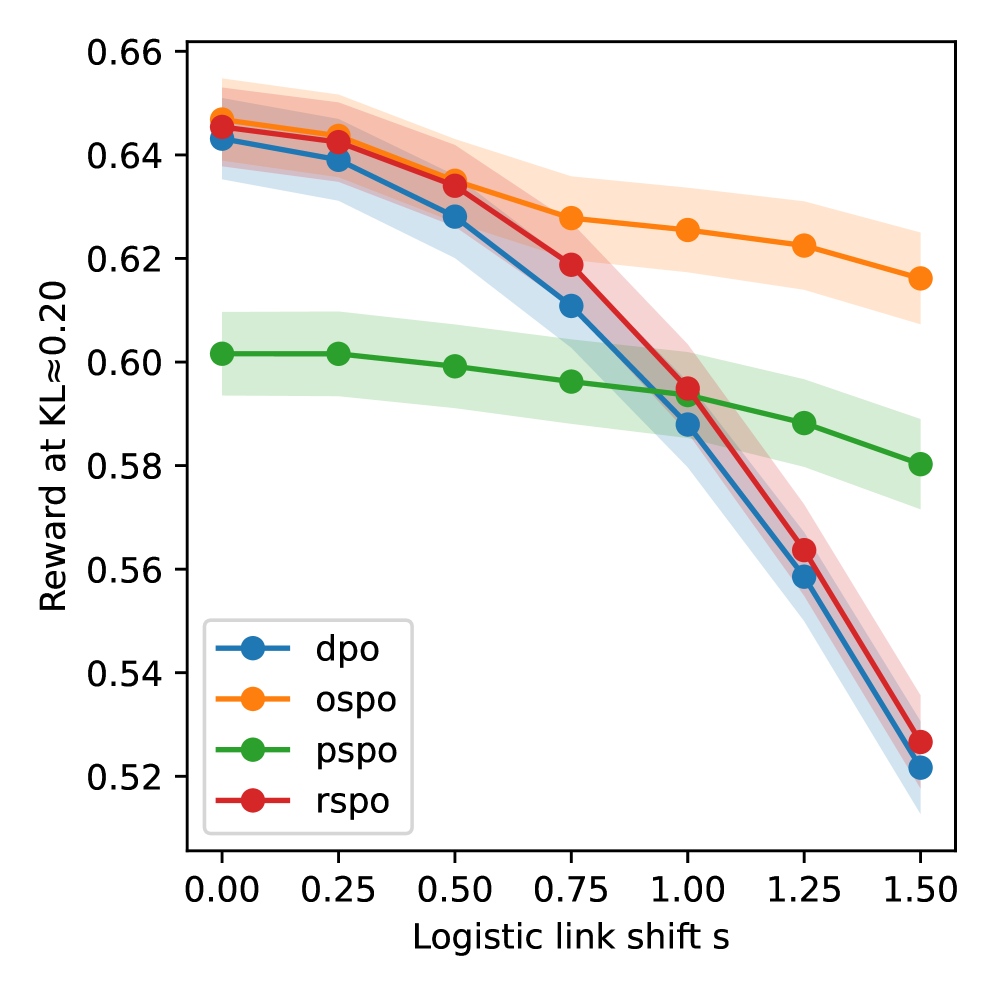
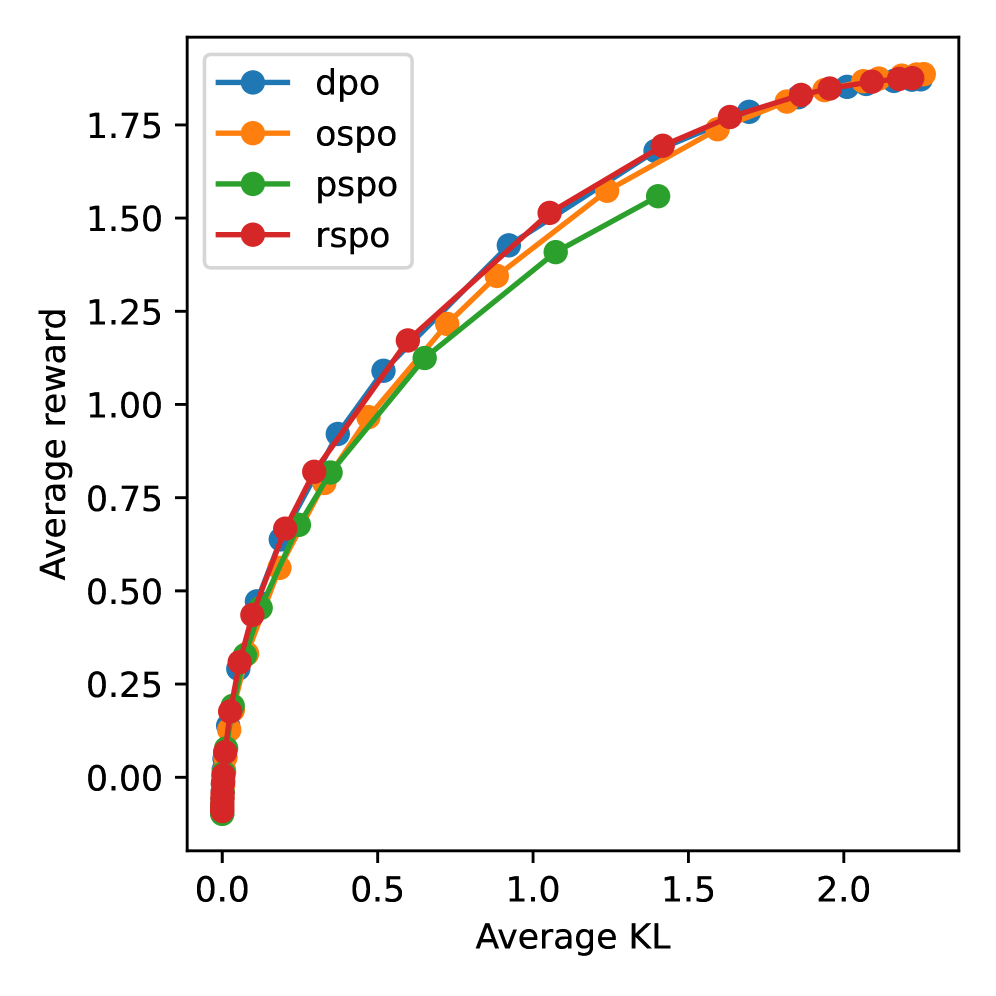

📊 实验亮点
论文在LLM对齐任务上进行了实证研究,验证了所提出的半参数偏好优化方法的有效性。实验结果表明,该方法在未知链接函数的情况下,能够有效地学习到与用户偏好对齐的策略,并且具有良好的收敛性和鲁棒性。具体的性能数据和对比基线在论文中进行了详细的展示。
🎯 应用场景
该研究成果可广泛应用于需要对齐语言模型偏好的各种场景,例如对话系统、文本生成、推荐系统等。通过避免对链接函数的预先设定,可以提高偏好对齐的鲁棒性和准确性,从而提升用户体验和系统性能。该方法还可应用于其他机器学习领域,例如排序学习和推荐系统,以解决链接函数未知或难以建模的问题。
📄 摘要(原文)
Aligning large language models (LLMs) to preference data typically assumes a known link function between observed preferences and latent rewards (e.g., a logistic Bradley-Terry link). Misspecification of this link can bias inferred rewards and misalign learned policies. We study preference alignment under an unknown and unrestricted link function. We show that realizability of $f$-divergence-constrained reward maximization in a policy class induces a semiparametric single-index binary choice model, where a scalar policy-dependent index captures all dependence on demonstrations and the remaining preference distribution is unrestricted. Rather than assuming this model has identifiable finite-dimensional structural parameters and estimating them, as in econometrics, we focus on policy learning with the reward function implicit, analyzing error to the optimal policy and allowing for unidentifiable nonparametric indices. We develop preference optimization algorithms robust to the unknown link and prove convergence guarantees in terms of generic function complexity measures. We demonstrate this empirically on LLM alignment. Code is available at https://github.com/causalml/spo/