Horizon Reduction as Information Loss in Offline Reinforcement Learning
作者: Uday Kumar Nidadala, Venkata Bhumika Guthi
分类: cs.LG
发布日期: 2025-12-25
备注: 13 pages, 3 figures
💡 一句话要点
揭示离线强化学习中Horizon Reduction导致信息损失的根本原因与结构性失效模式
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 离线强化学习 Horizon Reduction 信息损失 策略识别 马尔可夫决策过程
📋 核心要点
- 离线强化学习中,Horizon Reduction虽能提升扩展性,但其理论基础薄弱,可能导致信息损失。
- 论文将Horizon Reduction形式化为固定长度轨迹学习,证明即使数据无限,最优策略也可能无法识别。
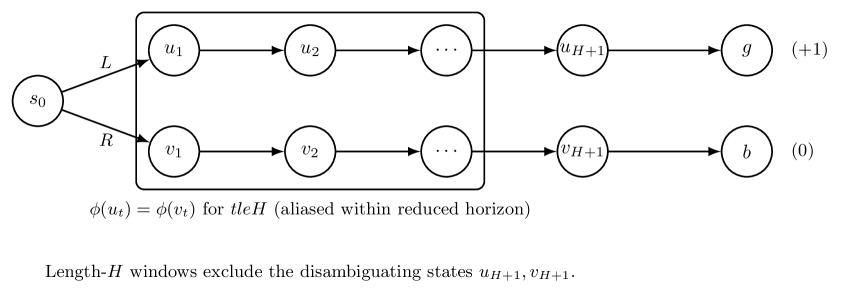
- 通过反例MDP,论文揭示了前缀无法区分性、目标错误规范和表示混叠三种结构性失效模式。
📝 摘要(中文)
Horizon reduction是离线强化学习(RL)中常用的设计策略,旨在缓解长程信用分配问题,提高稳定性,并通过截断rollout、窗口训练或分层分解来实现可扩展学习。尽管最近的经验证据表明,horizon reduction可以改善具有挑战性的离线RL基准测试的扩展性,但其理论含义仍不完善。本文表明,horizon reduction可能导致离线RL中根本且不可恢复的信息损失。我们将horizon reduction形式化为从固定长度轨迹段中学习,并证明在此范例和任何限制为固定长度轨迹段的学习接口下,即使具有无限数据和完美的函数逼近,最优策略也可能在统计上与次优策略无法区分。通过一组最小的反例马尔可夫决策过程(MDP),我们确定了三种不同的结构性失效模式:(i)导致可识别性失败的前缀无法区分性,(ii)由截断回报引起的客观目标错误规范,以及(iii)离线数据集支持和表示混叠。我们的结果建立了horizon reduction可以安全使用的必要条件,并强调了仅靠算法改进无法克服的内在局限性,补充了保守目标和分布偏移的算法工作,这些工作解决了离线RL难度的不同方面。
🔬 方法详解
问题定义:离线强化学习中,Horizon Reduction作为一种常用策略,旨在解决长程信用分配问题并提高学习效率。然而,现有方法缺乏对Horizon Reduction内在理论局限性的深入理解,导致在某些情况下,即使拥有大量离线数据,也无法学习到最优策略。现有方法未能充分考虑Horizon Reduction可能引入的信息损失,以及由此产生的策略识别问题。
核心思路:论文的核心思路是将Horizon Reduction形式化为从固定长度轨迹片段中学习的过程,并以此为基础分析其对策略学习的影响。通过理论分析和反例构建,揭示了Horizon Reduction可能导致的信息损失和策略识别失败。这种形式化方法使得可以更清晰地理解Horizon Reduction的内在局限性,并为安全使用Horizon Reduction提供了理论指导。
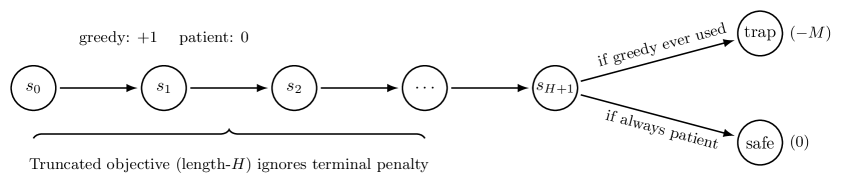
技术框架:论文的技术框架主要包括以下几个部分:首先,对Horizon Reduction进行形式化定义,将其视为从固定长度轨迹片段中学习的过程。其次,构建了一系列最小的反例马尔可夫决策过程(MDP),用于展示Horizon Reduction可能导致的结构性失效模式。这些反例MDP的设计旨在突出Horizon Reduction在不同场景下的局限性。最后,通过理论证明,阐述了在固定长度轨迹片段学习范式下,最优策略与次优策略可能在统计上无法区分的条件。
关键创新:论文的关键创新在于:(1) 首次从理论上揭示了Horizon Reduction在离线强化学习中可能导致的信息损失和策略识别失败问题。(2) 通过构建一系列最小的反例MDP,清晰地展示了Horizon Reduction可能导致的结构性失效模式,包括前缀无法区分性、目标错误规范和表示混叠。(3) 提出了Horizon Reduction可以安全使用的必要条件,为离线强化学习算法的设计提供了理论指导。
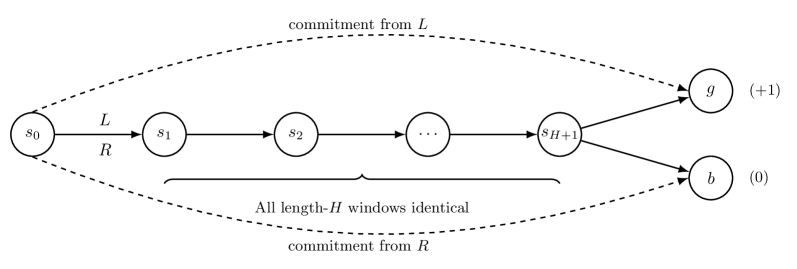
关键设计:论文的关键设计在于反例MDP的构建。这些MDP被精心设计,以突出Horizon Reduction在不同场景下的局限性。例如,通过设计具有相同前缀但不同后续状态的MDP,展示了前缀无法区分性问题。此外,论文还通过理论分析,推导出了在固定长度轨迹片段学习范式下,最优策略与次优策略无法区分的条件,为理解Horizon Reduction的局限性提供了理论依据。
🖼️ 关键图片
📊 实验亮点
论文通过理论分析和反例MDP,证明了Horizon Reduction可能导致信息损失和策略识别失败。具体而言,论文揭示了前缀无法区分性、目标错误规范和表示混叠三种结构性失效模式。这些结果表明,即使拥有无限数据和完美的函数逼近,Horizon Reduction也可能无法学习到最优策略,强调了算法设计中需要考虑Horizon Reduction的内在局限性。
🎯 应用场景
该研究成果可应用于机器人控制、自动驾驶、推荐系统等领域,帮助工程师在离线强化学习中更安全有效地使用Horizon Reduction策略。通过理解Horizon Reduction的局限性,可以避免因信息损失而导致的次优策略,并设计更鲁棒的离线强化学习算法。该研究还有助于推动离线强化学习理论的发展,为解决实际应用中的挑战提供理论指导。
📄 摘要(原文)
Horizon reduction is a common design strategy in offline reinforcement learning (RL), used to mitigate long-horizon credit assignment, improve stability, and enable scalable learning through truncated rollouts, windowed training, or hierarchical decomposition (Levine et al., 2020; Prudencio et al., 2023; Park et al., 2025). Despite recent empirical evidence that horizon reduction can improve scaling on challenging offline RL benchmarks, its theoretical implications remain underdeveloped (Park et al., 2025). In this paper, we show that horizon reduction can induce fundamental and irrecoverable information loss in offline RL. We formalize horizon reduction as learning from fixed-length trajectory segments and prove that, under this paradigm and any learning interface restricted to fixed-length trajectory segments, optimal policies may be statistically indistinguishable from suboptimal ones even with infinite data and perfect function approximation. Through a set of minimal counterexample Markov decision processes (MDPs), we identify three distinct structural failure modes: (i) prefix indistinguishability leading to identifiability failure, (ii) objective misspecification induced by truncated returns, and (iii) offline dataset support and representation aliasing. Our results establish necessary conditions under which horizon reduction can be safe and highlight intrinsic limitations that cannot be overcome by algorithmic improvements alone, complementing algorithmic work on conservative objectives and distribution shift that addresses a different axis of offline RL difficulty (Fujimoto et al., 2019; Kumar et al., 2020; Gulcehre et al., 2020).