Co-GRPO: Co-Optimized Group Relative Policy Optimization for Masked Diffusion Model
作者: Renping Zhou, Zanlin Ni, Tianyi Chen, Zeyu Liu, Yang Yue, Yulin Wang, Yuxuan Wang, Jingshu Liu, Gao Huang
分类: cs.LG, cs.AI, cs.CV
发布日期: 2025-12-25
备注: 17 pages, 6 figures
💡 一句话要点
提出Co-GRPO,协同优化Masked Diffusion Model及其解码策略,提升生成质量。
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion)
关键词: Masked Diffusion Model 生成模型 马尔可夫决策过程 策略优化 协同优化 推理调度 轨迹优化
📋 核心要点
- MDM推理依赖多步迭代和解码策略,但传统训练采用单步BERT式目标,忽略了推理过程中的轨迹级优化。
- Co-GRPO将MDM生成建模为MDP,联合优化模型参数和推理调度策略,实现训练与推理的对齐。
- 实验表明,Co-GRPO在多个基准测试中显著提升了生成质量,验证了其有效性。
📝 摘要(中文)
近年来,Masked Diffusion Models (MDMs) 在视觉、语言和跨模态生成方面展现出巨大潜力。然而,MDM的训练和推理过程存在显著差异。MDM推理是一个多步迭代过程,不仅受模型本身控制,还受各种调度策略(例如,每步解码多少个token)支配。相比之下,MDM通常使用简化的单步BERT式目标进行训练,该目标掩盖一部分token并同时预测所有token。这种步级简化从根本上将训练范式与推理的轨迹级性质分离,导致推理调度策略在训练期间从未得到优化。本文提出了Co-GRPO,它将MDM生成重新定义为一个统一的马尔可夫决策过程(MDP),该过程共同包含模型和推理调度。通过在轨迹级别应用Group Relative Policy Optimization,Co-GRPO在共享奖励下协同优化模型参数和调度参数,而无需通过多步生成过程进行昂贵的反向传播。这种整体优化使训练与推理更加彻底地对齐,并显着提高生成质量。在四个基准测试(ImageReward、HPS、GenEval和DPG-Bench)上的实验结果证明了该方法的有效性。
🔬 方法详解
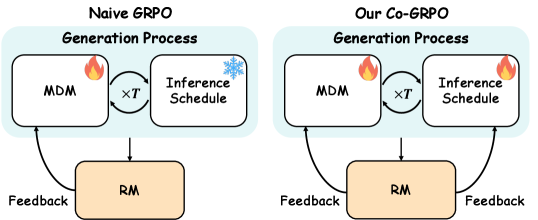
问题定义:Masked Diffusion Models (MDMs) 在生成任务中表现出色,但其训练和推理过程存在不一致性。训练通常采用单步BERT式目标,而推理是多步迭代过程,依赖于解码策略。这种差异导致训练过程中无法优化推理调度,影响生成质量。现有方法缺乏对模型和解码策略的协同优化。
核心思路:Co-GRPO的核心思路是将MDM的生成过程建模为一个马尔可夫决策过程(MDP),从而能够同时优化模型参数和推理调度策略。通过将两者纳入统一的框架,Co-GRPO旨在弥合训练和推理之间的差距,使模型在训练过程中能够学习到更优的解码轨迹。
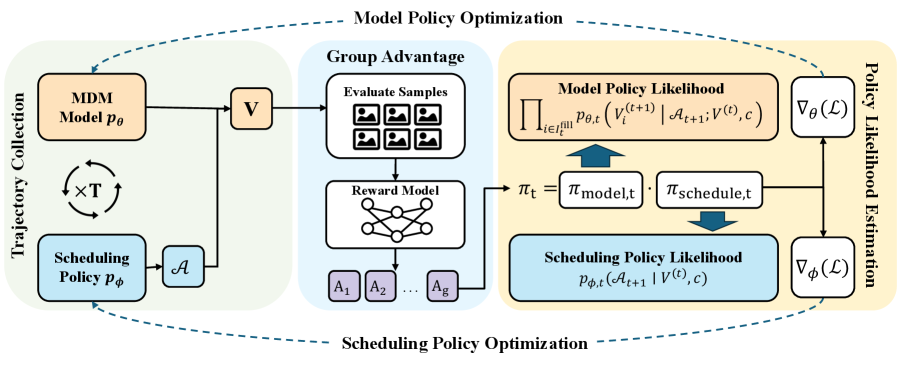
技术框架:Co-GRPO的技术框架主要包含以下几个部分:1) 将MDM生成过程形式化为MDP,其中状态是当前已解码的token序列,动作是选择下一个要解码的token集合以及相应的解码策略。2) 使用Group Relative Policy Optimization (GRPO) 算法,在轨迹级别优化模型参数和调度参数。3) 设计一个共享奖励函数,用于评估生成结果的质量,并指导模型和调度策略的优化。
关键创新:Co-GRPO的关键创新在于:1) 将MDM生成过程建模为MDP,从而能够同时优化模型和调度策略。2) 采用Group Relative Policy Optimization (GRPO) 算法,避免了通过多步生成过程进行昂贵的反向传播。3) 提出了一种协同优化框架,能够有效地对齐训练和推理过程。
关键设计:Co-GRPO的关键设计包括:1) MDP的状态空间、动作空间和奖励函数的定义。状态空间包含已解码的token序列,动作空间包含选择下一个要解码的token集合以及相应的解码策略。奖励函数用于评估生成结果的质量,例如使用ImageReward、HPS等指标。2) GRPO算法的具体实现,包括如何构建策略网络、如何计算梯度以及如何更新模型参数和调度参数。3) 模型和调度策略的参数化方式,例如使用神经网络来表示模型,并使用可学习的参数来控制解码策略。
🖼️ 关键图片

📊 实验亮点
Co-GRPO在ImageReward、HPS、GenEval和DPG-Bench四个基准测试上进行了评估,实验结果表明,Co-GRPO能够显著提高生成质量。例如,在ImageReward基准测试中,Co-GRPO相比基线方法取得了显著的性能提升,证明了其有效性。具体提升幅度在论文中有详细数据。
🎯 应用场景
Co-GRPO具有广泛的应用前景,可用于图像生成、文本生成、跨模态生成等领域。通过协同优化模型和解码策略,可以显著提高生成质量,生成更逼真、更符合用户需求的图像和文本。该方法还可以应用于其他序列生成任务,例如机器翻译、语音合成等,具有重要的实际价值和未来影响。
📄 摘要(原文)
Recently, Masked Diffusion Models (MDMs) have shown promising potential across vision, language, and cross-modal generation. However, a notable discrepancy exists between their training and inference procedures. In particular, MDM inference is a multi-step, iterative process governed not only by the model itself but also by various schedules that dictate the token-decoding trajectory (e.g., how many tokens to decode at each step). In contrast, MDMs are typically trained using a simplified, single-step BERT-style objective that masks a subset of tokens and predicts all of them simultaneously. This step-level simplification fundamentally disconnects the training paradigm from the trajectory-level nature of inference, leaving the inference schedules never optimized during training. In this paper, we introduce Co-GRPO, which reformulates MDM generation as a unified Markov Decision Process (MDP) that jointly incorporates both the model and the inference schedule. By applying Group Relative Policy Optimization at the trajectory level, Co-GRPO cooperatively optimizes model parameters and schedule parameters under a shared reward, without requiring costly backpropagation through the multi-step generation process. This holistic optimization aligns training with inference more thoroughly and substantially improves generation quality. Empirical results across four benchmarks-ImageReward, HPS, GenEval, and DPG-Bench-demonstrate the effectiveness of our approach. For more details, please refer to our project page: https://co-grpo.github.io/ .