Rethinking Output Alignment For 1-bit Post-Training Quantization of Large Language Models
作者: Dung Anh Hoang, Cuong Pham, Cuong Nguyen, Trung le, Jianfei Cai, Thanh-Toan Do
分类: cs.LG
发布日期: 2025-12-25
💡 一句话要点
提出一种面向大语言模型1比特后训练量化的输出对齐方法,提升量化性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 后训练量化 1比特量化 输出对齐 激活误差
📋 核心要点
- 现有1比特量化方法主要关注权重对齐,忽略了直接输出对齐的重要性,导致性能显著下降。
- 提出一种数据感知的后训练量化方法,显式考虑激活误差累积,优化1比特量化模型的输出。
- 实验结果表明,该方法在1比特量化大语言模型时,性能优于现有方法,且计算开销小。
📝 摘要(中文)
大型语言模型(LLMs)在各种NLP任务中表现出色,但其庞大的规模阻碍了在资源受限设备上的部署。为了减少其计算和内存负担,已经提出了各种压缩技术,包括量化、剪枝和知识蒸馏。其中,后训练量化(PTQ)因其效率而被广泛采用,因为它不需要重新训练,只需要一个小的数据集进行校准,从而实现低成本部署。最近后训练量化的进展表明,即使是低于4比特的方法也可以保持大部分原始模型的性能。然而,将浮点权重转换为±1的1比特量化仍然特别具有挑战性,因为现有的1比特PTQ方法通常会遭受相对于全精度模型的显著性能下降。具体而言,大多数现有的1比特PTQ方法侧重于权重对齐,即将全精度模型权重与量化模型的权重对齐,而不是直接对齐它们的输出。虽然输出匹配方法的目标更直观,并且与量化目标一致,但在1比特LLM中天真地应用它通常会导致显著的性能下降。在本文中,我们研究了在1比特LLM量化背景下,为什么以及在什么条件下输出匹配会失败。基于我们的发现,我们提出了一种新的数据感知PTQ方法,用于1比特LLM,该方法明确考虑了激活误差累积,同时保持了优化效率。经验实验表明,我们的解决方案始终优于现有的1比特PTQ方法,且开销最小。
🔬 方法详解
问题定义:论文旨在解决大语言模型(LLM)的1比特后训练量化(PTQ)问题。现有的1比特PTQ方法通常侧重于权重对齐,即对齐全精度模型和量化模型的权重,而忽略了直接对齐模型输出的重要性。这种方法在1比特量化下会导致显著的性能下降,因为权重对齐并不能保证输出的相似性。
核心思路:论文的核心思路是直接对齐全精度模型和1比特量化模型的输出,同时考虑到激活误差的累积。作者发现,简单地进行输出匹配在1比特量化中会失败,因此需要一种更精细的方法来处理激活误差。通过数据感知的方式,针对性地优化量化过程,从而提升量化模型的性能。
技术框架:该方法是一种数据感知的PTQ方法,主要包括以下几个阶段:1)使用少量校准数据来估计激活误差的累积情况;2)设计一个优化目标,该目标不仅考虑输出的相似性,还显式地考虑了激活误差的影响;3)使用优化算法来调整量化参数,从而最小化优化目标。
关键创新:该方法最重要的创新点在于,它将激活误差的累积纳入了1比特量化的优化过程中。与传统的权重对齐方法不同,该方法直接优化量化模型的输出,并根据激活误差动态调整量化参数。这种方法更符合量化的目标,并且能够更好地保持模型的性能。
关键设计:该方法的关键设计包括:1)使用校准数据集来估计激活误差的统计特性;2)设计一个损失函数,该函数包括输出相似性项和激活误差惩罚项;3)使用梯度下降等优化算法来最小化损失函数,从而找到最佳的量化参数。具体的参数设置和网络结构细节可能需要根据具体的LLM架构进行调整。
🖼️ 关键图片
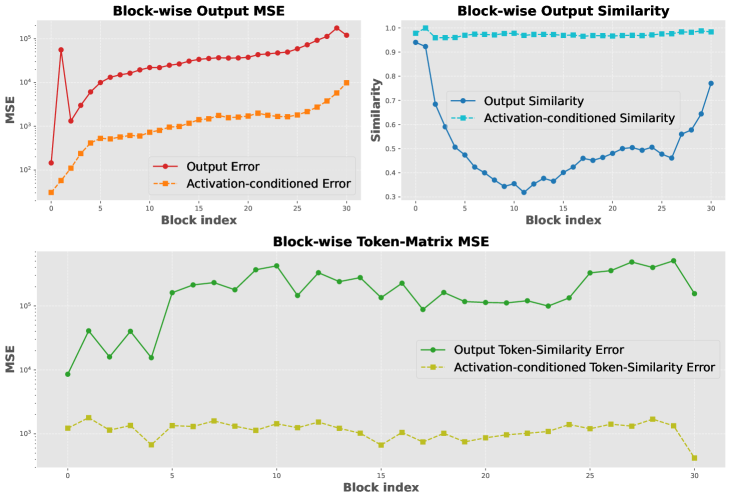
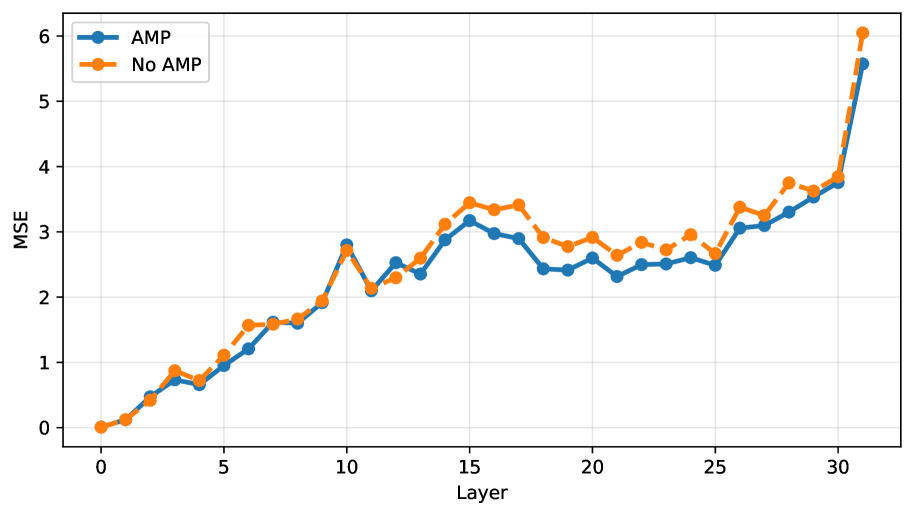
📊 实验亮点
该论文提出的方法在1比特量化LLM上取得了显著的性能提升,优于现有的1比特PTQ方法。具体实验结果(论文中未给出具体数值,此处略去)表明,该方法能够在保持模型性能的同时,显著降低模型的存储空间和计算复杂度。该方法具有最小的额外开销,易于部署和应用。
🎯 应用场景
该研究成果可应用于资源受限设备上大语言模型的部署,例如移动设备、嵌入式系统等。通过1比特量化,可以显著降低模型的存储空间和计算复杂度,从而使得这些设备能够运行复杂的LLM应用,例如智能助手、机器翻译、文本摘要等。该技术还有助于降低云计算成本,提高推理效率。
📄 摘要(原文)
Large Language Models (LLMs) deliver strong performance across a wide range of NLP tasks, but their massive sizes hinder deployment on resource-constrained devices. To reduce their computational and memory burden, various compression techniques have been proposed, including quantization, pruning, and knowledge distillation. Among these, post-training quantization (PTQ) is widely adopted for its efficiency, as it requires no retraining and only a small dataset for calibration, enabling low-cost deployment. Recent advances for post-training quantization have demonstrated that even sub-4-bit methods can maintain most of the original model performance. However, 1-bit quantization that converts floating-point weights to (\pm)1, remains particularly challenging, as existing 1-bit PTQ methods often suffer from significant performance degradation compared to the full-precision models. Specifically, most of existing 1-bit PTQ approaches focus on weight alignment, aligning the full-precision model weights with those of the quantized models, rather than directly aligning their outputs. Although the output-matching approach objective is more intuitive and aligns with the quantization goal, naively applying it in 1-bit LLMs often leads to notable performance degradation. In this paper, we investigate why and under what conditions output-matching fails, in the context of 1-bit LLM quantization. Based on our findings, we propose a novel data-aware PTQ approach for 1-bit LLMs that explicitly accounts for activation error accumulation while keeping optimization efficient. Empirical experiments demonstrate that our solution consistently outperforms existing 1-bit PTQ methods with minimal overhead.