nncase: An End-to-End Compiler for Efficient LLM Deployment on Heterogeneous Storage Architectures
作者: Hui Guo, Qihang Zheng, Chenghai Huo, Dongliang Guo, Haoqi Yang, Yang Zhang
分类: cs.DC, cs.LG
发布日期: 2025-12-25
🔗 代码/项目: GITHUB
💡 一句话要点
nncase:用于异构存储架构上高效LLM部署的端到端编译器
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 编译器 异构计算 自动化优化 E-graph 代码生成 模型部署
📋 核心要点
- 现有编译器在异构内存架构上部署LLM时,面临工作流程碎片化和适配成本高等挑战。
- nncase采用基于e-graph的项重写引擎,全局探索计算和数据移动策略,缓解阶段顺序问题。
- 实验结果表明,nncase在Qwen3系列模型上超越MLC LLM和Intel IPEX,CPU性能媲美llama.cpp。
📝 摘要(中文)
大型语言模型(LLM)的高效部署受到内存架构异构性的阻碍,传统的编译器面临着工作流程碎片化和高昂的适配成本。本文提出了nncase,一个开源的端到端编译框架,旨在统一跨不同目标的优化。nncase的核心是基于e-graph的项重写引擎,它可以缓解阶段顺序问题,从而实现计算和数据移动策略的全局探索。该框架集成了三个关键模块:Auto Vectorize用于适应异构计算单元,Auto Distribution用于搜索具有成本感知通信优化的并行策略,以及Auto Schedule用于最大化片上缓存局部性。此外,buffer-aware Codegen阶段确保了高效的内核实例化。评估表明,nncase在Qwen3系列模型上优于主流框架如MLC LLM和Intel IPEX,并在CPU上实现了与手工优化的llama.cpp相当的性能,证明了自动化编译对于高性能LLM部署的可行性。源代码可在https://github.com/kendryte/nncase获取。
🔬 方法详解
问题定义:现有编译器在异构存储架构上部署大型语言模型时,由于内存架构的异构性,面临着工作流程碎片化和高昂的适配成本。传统的编译流程难以充分利用不同硬件的特性,导致性能瓶颈。此外,优化策略的选择和顺序(phase ordering problem)对最终性能影响很大,人工调优成本高昂。
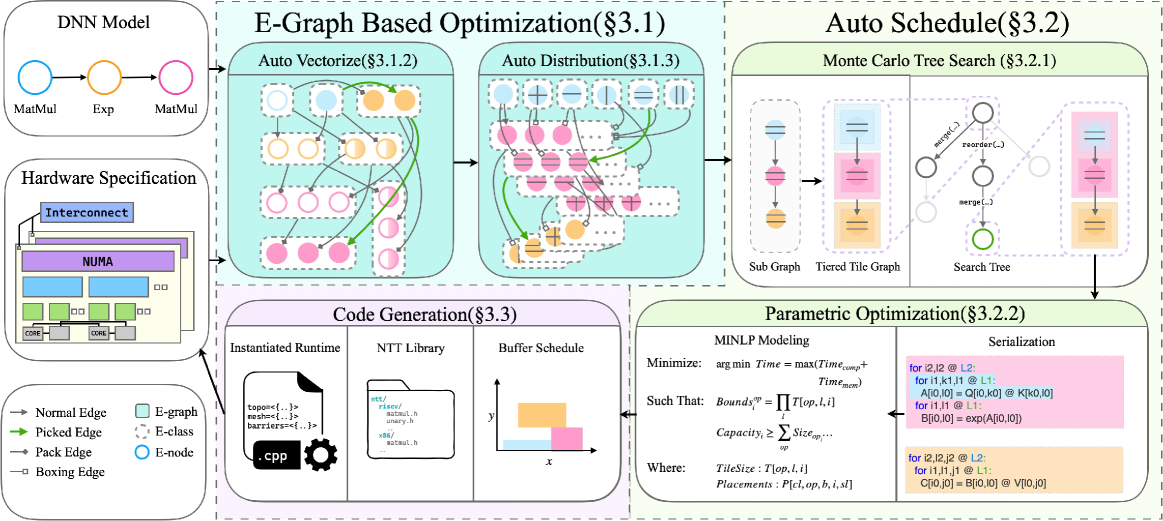
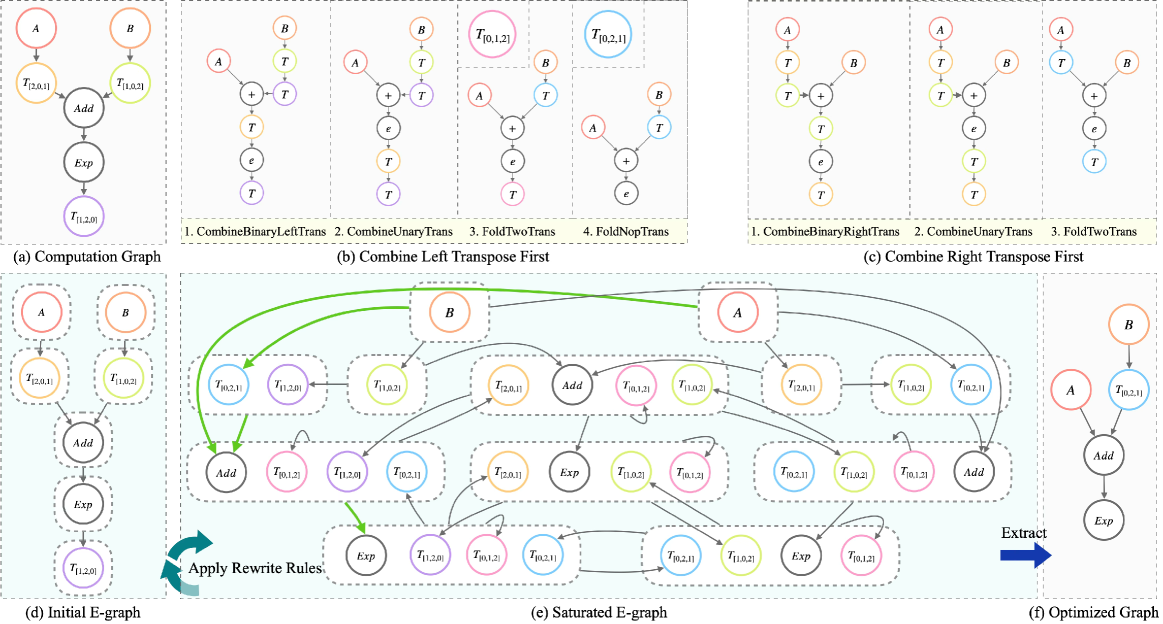
核心思路:nncase的核心思路是构建一个端到端的编译框架,通过统一的优化流程来解决异构存储架构上的LLM部署问题。它采用基于e-graph的项重写引擎,将不同的优化策略表示为图上的节点,通过搜索和重写操作,自动探索最优的计算和数据移动策略,从而缓解阶段顺序问题。
技术框架:nncase框架包含以下主要模块:1) Auto Vectorize:根据目标硬件的向量化能力,自动将计算操作向量化,以提高计算效率。2) Auto Distribution:搜索最优的并行策略,并进行成本感知的通信优化,以减少数据传输开销。3) Auto Schedule:通过循环分块、数据重排等技术,最大化片上缓存的局部性,以减少访存延迟。4) Buffer-aware Codegen:生成高效的内核代码,并进行buffer管理,以提高内存利用率。
关键创新:nncase最重要的技术创新在于其基于e-graph的项重写引擎。传统的编译器通常采用固定的优化流程,难以适应不同的硬件和模型。而nncase的e-graph引擎可以将不同的优化策略表示为图上的节点,通过搜索和重写操作,自动探索最优的优化组合。这种方法可以有效地缓解阶段顺序问题,并提高编译器的自适应能力。
关键设计:nncase的关键设计包括:1) e-graph的构建和维护:如何有效地表示和更新e-graph,以支持高效的搜索和重写操作。2) 成本模型的建立:如何准确地评估不同优化策略的性能,以便选择最优的策略。3) 搜索算法的设计:如何高效地搜索e-graph,以找到最优的优化组合。4) 代码生成器的优化:如何生成高效的内核代码,并进行buffer管理。
🖼️ 关键图片

📊 实验亮点
nncase在Qwen3系列模型上优于主流框架MLC LLM和Intel IPEX。在CPU上,nncase实现了与手工优化的llama.cpp相当的性能,证明了自动化编译对于高性能LLM部署的可行性。这些结果表明,nncase能够有效地利用异构存储架构的特性,并生成高效的内核代码。
🎯 应用场景
nncase可应用于各种需要高性能LLM部署的场景,例如边缘计算设备、移动设备和服务器。通过自动化编译优化,nncase可以降低LLM部署的门槛,使更多开发者能够轻松地将LLM应用到实际场景中。该研究有助于推动LLM在各个领域的广泛应用,例如智能助手、自然语言处理和机器翻译。
📄 摘要(原文)
The efficient deployment of large language models (LLMs) is hindered by memory architecture heterogeneity, where traditional compilers suffer from fragmented workflows and high adaptation costs. We present nncase, an open-source, end-to-end compilation framework designed to unify optimization across diverse targets. Central to nncase is an e-graph-based term rewriting engine that mitigates the phase ordering problem, enabling global exploration of computation and data movement strategies. The framework integrates three key modules: Auto Vectorize for adapting to heterogeneous computing units, Auto Distribution for searching parallel strategies with cost-aware communication optimization, and Auto Schedule for maximizing on-chip cache locality. Furthermore, a buffer-aware Codegen phase ensures efficient kernel instantiation. Evaluations show that nncase outperforms mainstream frameworks like MLC LLM and Intel IPEX on Qwen3 series models and achieves performance comparable to the hand-optimized llama.cpp on CPUs, demonstrating the viability of automated compilation for high-performance LLM deployment. The source code is available at https://github.com/kendryte/nncase.