Temporal Visual Semantics-Induced Human Motion Understanding with Large Language Models
作者: Zheng Xing, Weibing Zhao
分类: cs.LG, cs.CV
发布日期: 2025-12-24
💡 一句话要点
提出基于大语言模型的时间视觉语义引导的人体运动分割方法
🎯 匹配领域: 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人体运动分割 大语言模型 时间视觉语义 子空间聚类 无监督学习
📋 核心要点
- 现有无监督人体运动分割方法忽略了时间语义信息,限制了分割性能。
- 利用大语言模型提取连续帧的时间视觉语义,并将其融入子空间聚类框架中。
- 实验结果表明,该方法在多个基准数据集上超越了现有最先进的方法。
📝 摘要(中文)
本文提出了一种利用大语言模型(LLM)增强子空间聚类性能的无监督人体运动分割(HMS)方法。传统方法忽略了时间语义探索在HMS中的作用。本文利用从人体运动序列中提取的时间视觉语义(TVS),借助LLM的图像到文本能力,将从连续帧中提取的文本运动信息融入到子空间聚类框架中。通过查询LLM判断连续帧是否描述相同的运动,并基于其响应学习时间邻域信息。进而,开发了一种TVS集成的子空间聚类方法,将子空间嵌入与时间正则化器相结合,使每个帧与其时间邻域共享相似的子空间嵌入。此外,基于具有时间约束的子空间嵌入执行分割,该约束诱导每个帧与其时间邻域分组。引入了一个反馈框架,基于分割输出持续优化子空间嵌入。实验结果表明,该方法在四个人体运动基准数据集上优于现有方法。
🔬 方法详解
问题定义:论文旨在解决无监督人体运动分割问题。现有方法,特别是基于子空间聚类的方法,忽略了人体运动序列中蕴含的时间语义信息,导致分割精度受限。这些方法没有充分利用连续帧之间的关联性,无法有效区分相似但不同的运动模式。
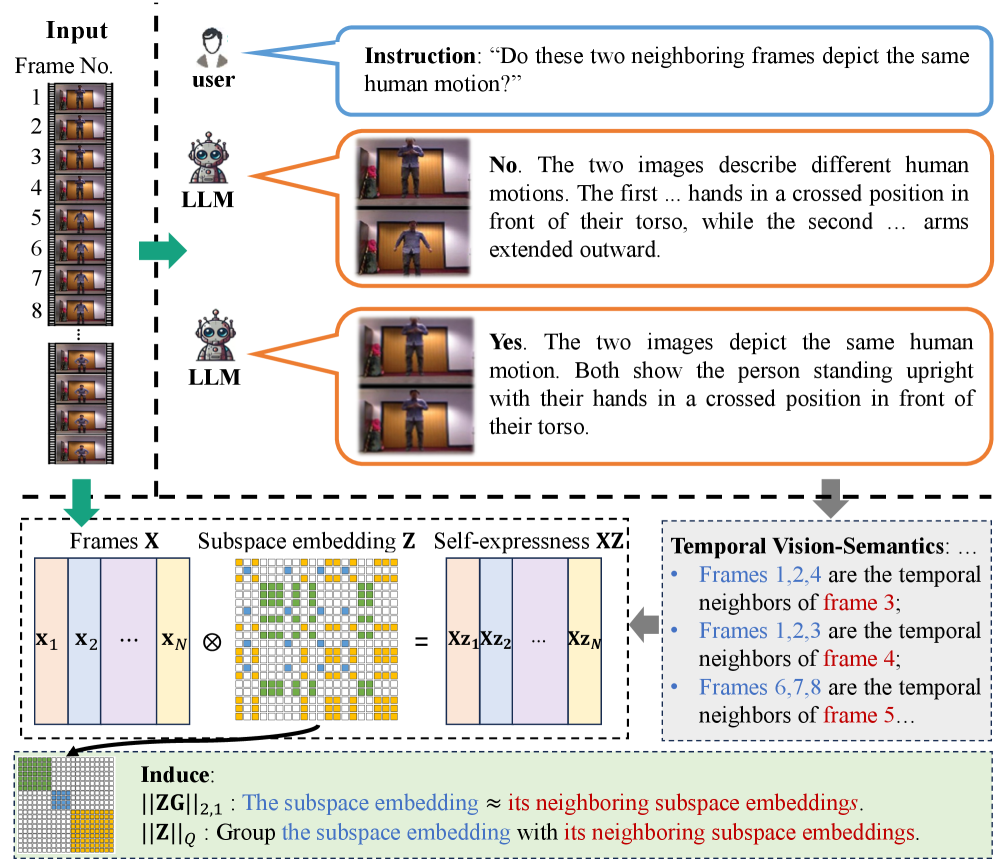
核心思路:论文的核心思路是利用大语言模型(LLM)的图像到文本转换能力,从连续帧中提取时间视觉语义(TVS)。通过LLM理解人体运动序列,获得帧与帧之间的语义关系,并将这些语义信息融入到子空间聚类框架中,从而提升分割性能。
技术框架:整体框架包含以下几个主要阶段:1) 时间视觉语义提取:利用LLM处理连续帧,判断相邻帧是否描述相同的运动。2) 时间邻域信息学习:基于LLM的响应,构建时间邻域图,表示帧与帧之间的语义相似性。3) TVS集成子空间聚类:将子空间嵌入与时间正则化器相结合,鼓励相邻帧共享相似的子空间嵌入。4) 时间约束分割:基于子空间嵌入进行分割,并施加时间约束,鼓励相邻帧被划分到同一类别。5) 反馈优化:根据分割结果,持续优化子空间嵌入。
关键创新:最重要的创新点在于将大语言模型引入到人体运动分割任务中,利用LLM提取时间视觉语义,弥补了传统方法忽略时间信息的不足。通过时间正则化器和时间约束,有效地将时间语义信息融入到子空间聚类框架中,提升了分割精度。
关键设计:论文的关键设计包括:1) 使用LLM判断连续帧是否描述相同运动的具体prompt设计。2) 时间正则化器的具体形式,如何将时间邻域信息融入到子空间嵌入中。3) 时间约束分割的具体实现,如何保证相邻帧被划分到同一类别。4) 反馈优化机制,如何根据分割结果调整子空间嵌入。
🖼️ 关键图片

📊 实验亮点
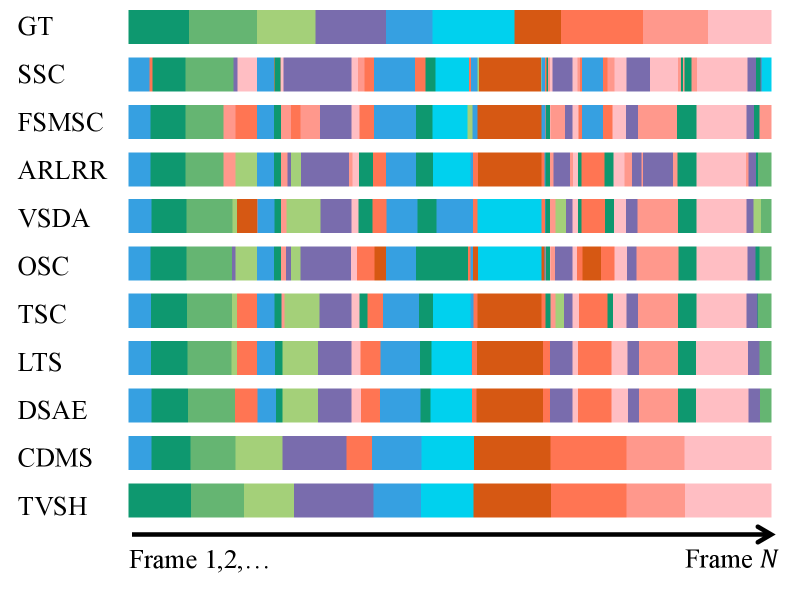
实验结果表明,该方法在四个人体运动基准数据集上均取得了优于现有最先进方法的效果。具体提升幅度未知,但论文强调了其显著的性能优势。通过引入大语言模型提取时间视觉语义,该方法能够更准确地分割人体运动,验证了其有效性。
🎯 应用场景
该研究成果可应用于视频监控、人机交互、运动分析等领域。例如,在视频监控中,可以自动分割和识别不同的人体运动行为,提高监控效率。在人机交互中,可以更准确地理解用户的运动意图,实现更自然的人机交互。在运动分析中,可以对运动员的运动姿态进行精细分割和分析,辅助运动训练。
📄 摘要(原文)
Unsupervised human motion segmentation (HMS) can be effectively achieved using subspace clustering techniques. However, traditional methods overlook the role of temporal semantic exploration in HMS. This paper explores the use of temporal vision semantics (TVS) derived from human motion sequences, leveraging the image-to-text capabilities of a large language model (LLM) to enhance subspace clustering performance. The core idea is to extract textual motion information from consecutive frames via LLM and incorporate this learned information into the subspace clustering framework. The primary challenge lies in learning TVS from human motion sequences using LLM and integrating this information into subspace clustering. To address this, we determine whether consecutive frames depict the same motion by querying the LLM and subsequently learn temporal neighboring information based on its response. We then develop a TVS-integrated subspace clustering approach, incorporating subspace embedding with a temporal regularizer that induces each frame to share similar subspace embeddings with its temporal neighbors. Additionally, segmentation is performed based on subspace embedding with a temporal constraint that induces the grouping of each frame with its temporal neighbors. We also introduce a feedback-enabled framework that continuously optimizes subspace embedding based on the segmentation output. Experimental results demonstrate that the proposed method outperforms existing state-of-the-art approaches on four benchmark human motion datasets.