dUltra: Ultra-Fast Diffusion Language Models via Reinforcement Learning
作者: Shirui Chen, Jiantao Jiao, Lillian J. Ratliff, Banghua Zhu
分类: cs.LG, cs.AI
发布日期: 2025-12-24
💡 一句话要点
提出dUltra,通过强化学习加速扩散语言模型并行解码,提升推理效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 扩散语言模型 强化学习 并行解码 策略优化 文本生成
📋 核心要点
- 现有掩码扩散语言模型并行解码速度慢,难以超越自回归模型。
- dUltra利用强化学习,学习最优的token unmasking策略,加速并行解码过程。
- 实验表明,dUltra在数学推理和代码生成任务上,显著提升了效率和准确率。
📝 摘要(中文)
本文提出dUltra,一个基于强化学习的框架,用于加速掩码扩散语言模型(MDLM)的并行token生成。现有MDLM即使采用复杂的采样策略,其解码速度也与自回归模型加推测解码方案相当,优势不明显。现有的基于蒸馏的加速方法(dParallel, d3LLM)在基础模型生成的轨迹上微调MDLM,这可能导致微调期间的策略偏移,并将性能限制在基础模型的样本质量上。dUltra基于Group Relative Policy Optimization (GRPO),采用on-policy强化学习,学习高效并行解码的unmasking策略。dUltra引入一个unmasking planner head,预测每个token在独立伯努利分布下的unmasking可能性。我们联合优化基础扩散LLM和unmasking order planner,使用结合可验证奖励、蒸馏奖励和unmasking步骤数量的奖励信号。在数学推理和代码生成任务中,dUltra改进了准确率-效率的权衡,超越了最先进的启发式和蒸馏基线,朝着实现自回归模型之上的“扩散霸权”迈进。
🔬 方法详解
问题定义:论文旨在解决掩码扩散语言模型(MDLM)推理速度慢的问题。现有MDLM虽然具备并行生成token的潜力,但由于解码策略的限制,实际速度提升有限,甚至不如自回归模型加推测解码。现有的蒸馏方法依赖于基础模型的样本,存在策略偏移和性能上限问题。
核心思路:论文的核心思路是利用强化学习,学习一个最优的unmasking策略,从而在保证生成质量的前提下,最大化并行解码的效率。通过学习每个token的unmasking概率,模型可以智能地选择哪些token应该被优先解码,从而减少迭代次数,加速生成过程。
技术框架:dUltra框架包含一个基础扩散语言模型和一个unmasking planner head。基础扩散语言模型负责生成文本,unmasking planner head负责预测每个token的unmasking概率。整个框架采用on-policy强化学习进行训练,使用Group Relative Policy Optimization (GRPO)算法。训练过程中,模型通过最大化奖励信号来学习最优策略。奖励信号由三部分组成:可验证奖励(衡量生成文本的质量)、蒸馏奖励(模仿基础模型的行为)和unmasking步骤数量(鼓励更少的迭代次数)。
关键创新:dUltra的关键创新在于使用强化学习来优化MDLM的解码策略。与现有的启发式方法和蒸馏方法不同,dUltra采用on-policy学习,避免了策略偏移问题,并且能够直接优化解码效率。Unmasking planner head的设计使得模型能够自适应地选择unmasking的token,从而实现更高效的并行解码。
关键设计:Unmasking planner head预测每个token在独立伯努利分布下的unmasking概率。奖励函数的设计至关重要,它需要平衡生成质量、与基础模型的相似度和解码效率。具体来说,可验证奖励可以使用任务相关的指标(例如,代码生成的编译成功率),蒸馏奖励可以使用KL散度来衡量生成文本与基础模型输出的差异,unmasking步骤数量可以直接作为负奖励。GRPO算法用于稳定训练过程,避免策略崩溃。
🖼️ 关键图片
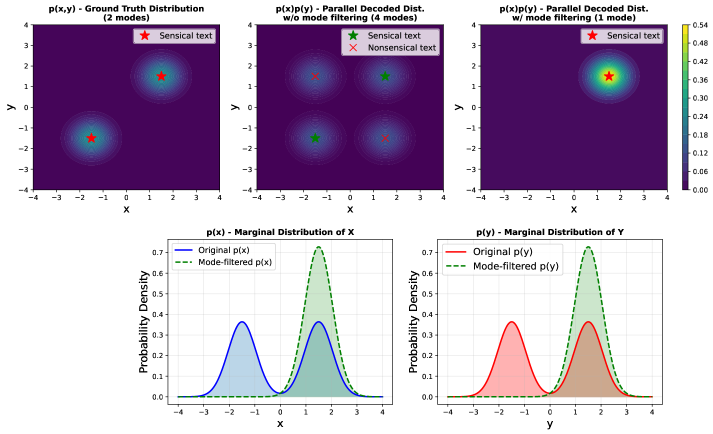

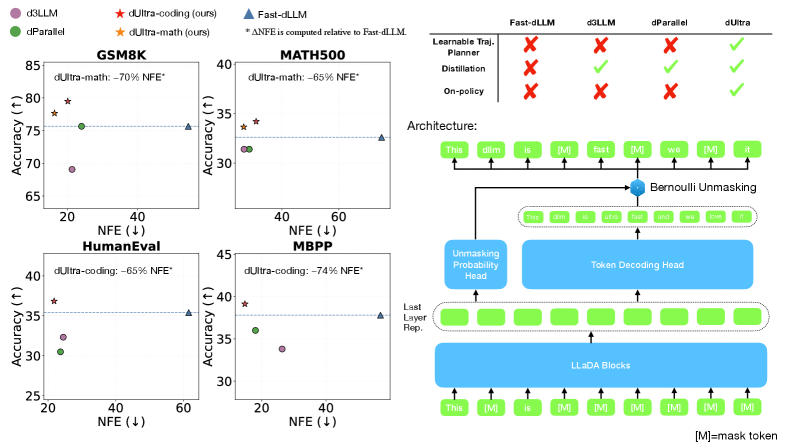
📊 实验亮点
实验结果表明,dUltra在数学推理和代码生成任务上显著优于现有的启发式和蒸馏基线。例如,在代码生成任务中,dUltra在保证编译成功率的前提下,显著减少了解码步骤,实现了更高的效率。与最先进的基线相比,dUltra在准确率和效率之间取得了更好的平衡。
🎯 应用场景
dUltra具有广泛的应用前景,可以应用于各种需要快速文本生成的场景,例如代码生成、机器翻译、文本摘要等。通过提高扩散语言模型的推理效率,dUltra可以降低计算成本,并使得这些模型能够部署在资源受限的设备上。此外,dUltra的强化学习框架也可以推广到其他类型的生成模型中。
📄 摘要(原文)
Masked diffusion language models (MDLMs) offer the potential for parallel token generation, but most open-source MDLMs decode fewer than 5 tokens per model forward pass even with sophisticated sampling strategies. As a result, their sampling speeds are often comparable to AR + speculative decoding schemes, limiting their advantage over mainstream autoregressive approaches. Existing distillation-based accelerators (dParallel, d3LLM) finetune MDLMs on trajectories generated by a base model, which can become off-policy during finetuning and restrict performance to the quality of the base model's samples. We propose \texttt{dUltra}, an on-policy reinforcement learning framework based on Group Relative Policy Optimization (GRPO) that learns unmasking strategies for efficient parallel decoding. dUltra introduces an unmasking planner head that predicts per-token unmasking likelihoods under independent Bernoulli distributions. We jointly optimize the base diffusion LLM and the unmasking order planner using reward signals combining verifiable reward, distillation reward, and the number of unmasking steps. Across mathematical reasoning and code generation tasks, dUltra improves the accuracy--efficiency trade-off over state-of-the-art heuristic and distillation baselines, moving towards achieving ``diffusion supremacy'' over autoregressive models.