Fuzzwise: Intelligent Initial Corpus Generation for Fuzzing
作者: Hridya Dhulipala, Xiaokai Rong, Aashish Yadavally, Tien N. Nguyen
分类: cs.SE, cs.LG
发布日期: 2025-12-24
💡 一句话要点
FuzzWise:利用LLM智能生成模糊测试初始语料库,提升测试效率
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 模糊测试 初始语料库生成 大型语言模型 代码覆盖率 软件安全 多智能体系统 预测模型
📋 核心要点
- 传统模糊测试方法在初始语料库生成阶段效率低下,需要生成大量种子后进行最小化,耗费资源。
- FuzzWise利用LLM构建多智能体框架,一个生成测试用例,另一个预测代码覆盖率,无需实际执行即可评估种子质量。
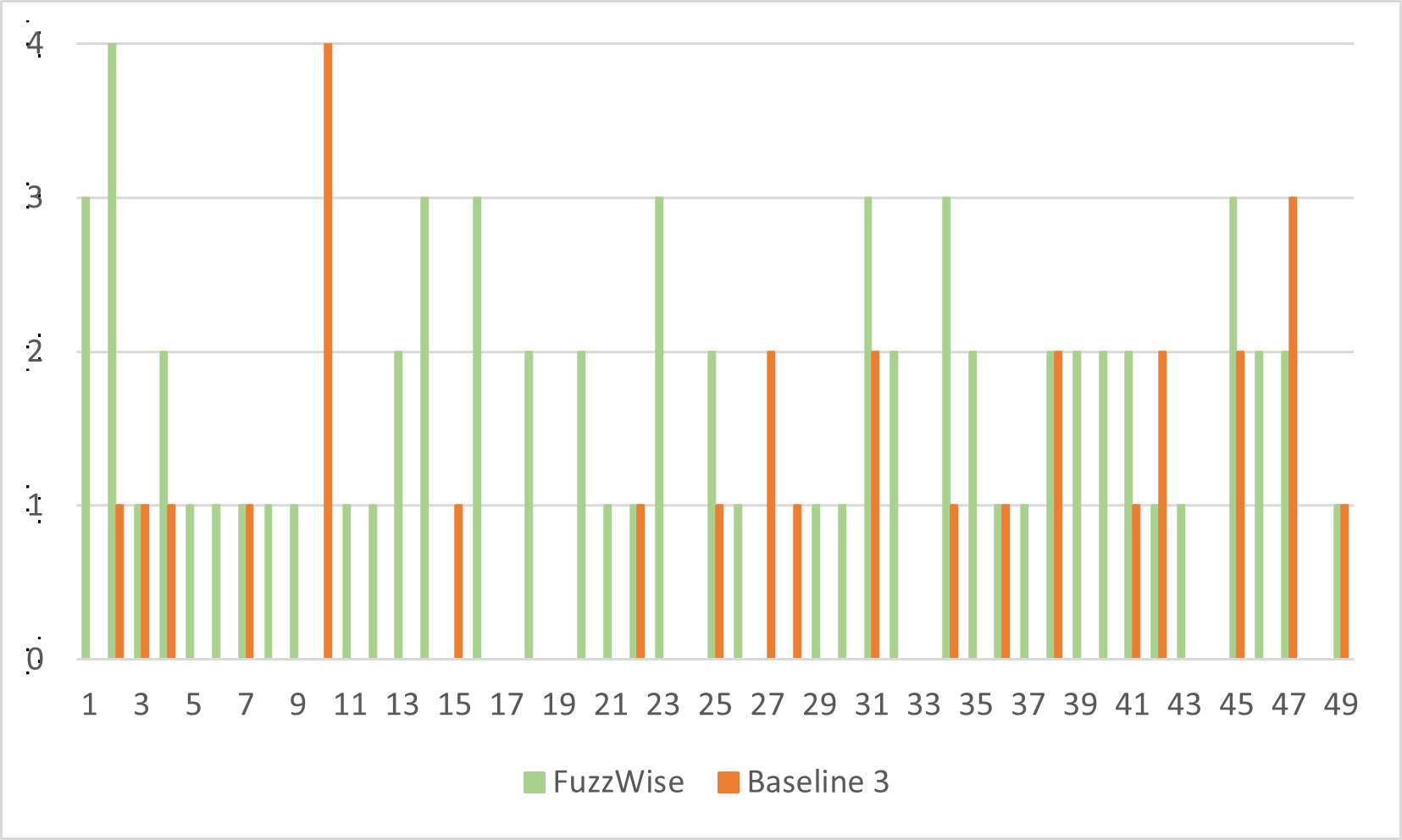
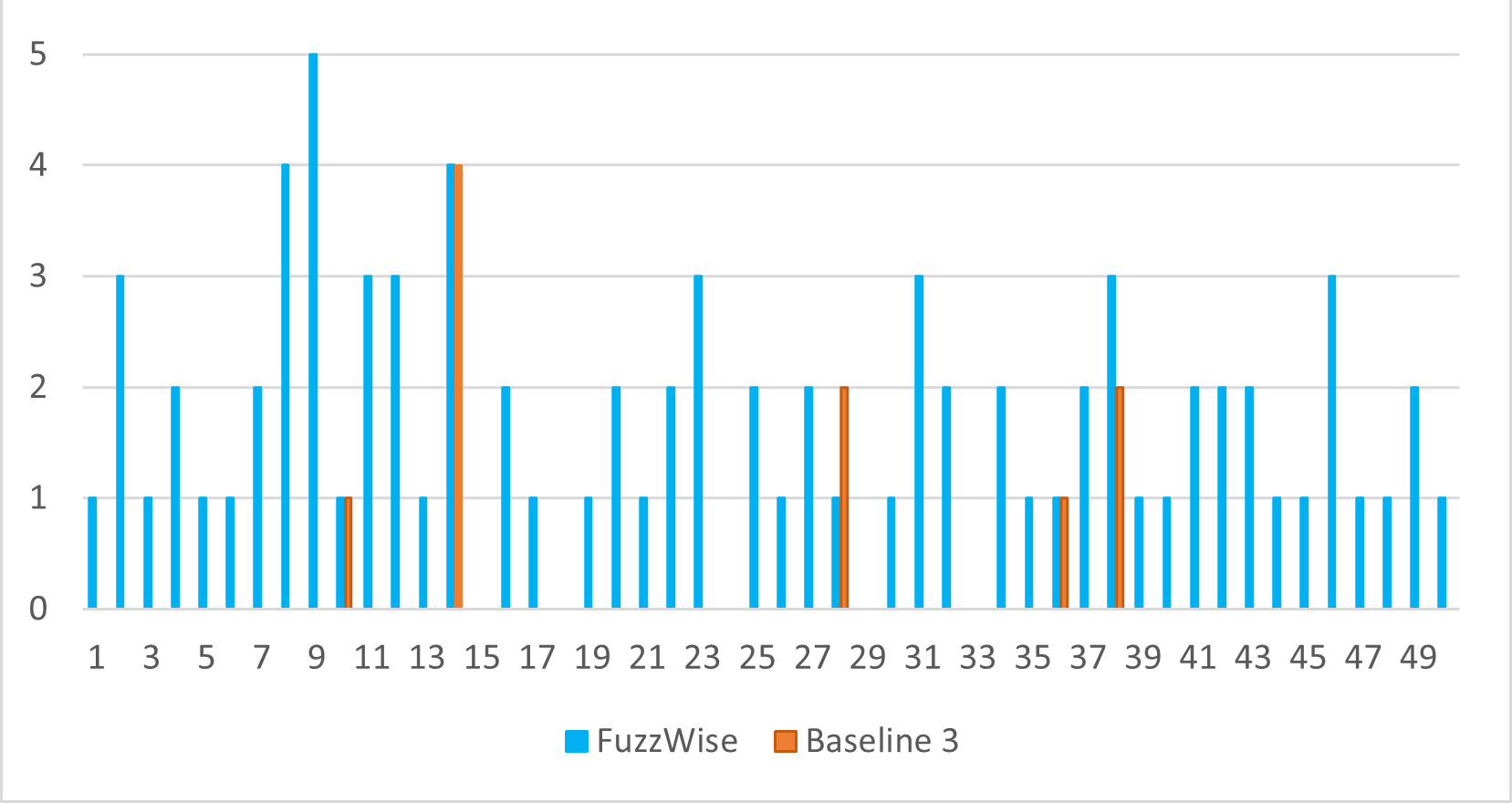
- 实验表明,FuzzWise能以更少的测试用例实现更高的代码覆盖率,触发更多错误,且更省时高效。
📝 摘要(中文)
本文提出FuzzWise,一种用于模糊测试的智能初始语料库生成方法。与分别进行大规模语料库生成和后续最小化不同,FuzzWise将二者整合为一个过程,以生成最佳的初始种子语料库(ICS)。FuzzWise利用基于大型语言模型(LLM)的多智能体框架。第一个LLM智能体为目标程序生成测试用例。第二个LLM智能体,作为预测代码覆盖率模块,评估每个生成的测试用例是否能增强当前语料库的整体覆盖率。这种简化的流程允许立即评估每个新生成的测试种子对整体覆盖率的贡献。FuzzWise采用LLM进行预测,无需实际执行,从而节省计算资源和时间,尤其是在不希望甚至不可能执行的情况下。实验评估表明,FuzzWise生成的测试用例明显少于基线方法。尽管测试用例数量较少,但FuzzWise实现了较高的代码覆盖率,并触发了比基线方法更多的运行时错误。此外,它在生成初始语料库时更省时、覆盖率更高,能捕获更多错误。
🔬 方法详解
问题定义:在基于变异的灰盒模糊测试中,为初始语料库生成高质量的输入种子对于有效的模糊测试至关重要。现有方法通常分为两个阶段:首先生成一个庞大的语料库,然后对其进行最小化。这种分离的方式效率较低,并且可能无法找到最优的初始语料库。痛点在于计算资源消耗大,时间成本高,尤其是在执行代价昂贵或不可行的情况下。
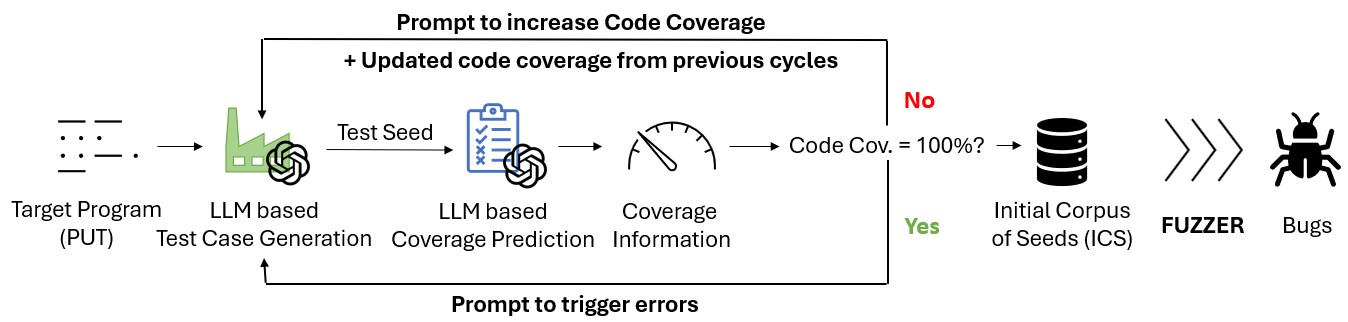
核心思路:FuzzWise的核心思路是将语料库生成和最小化整合为一个统一的过程,利用大型语言模型(LLM)来预测测试用例的代码覆盖率,从而避免实际执行。通过这种方式,可以快速评估每个新生成的测试种子对整体覆盖率的贡献,并选择最有价值的种子加入初始语料库。这样设计的目的是提高效率,减少资源消耗,并更快地发现潜在的错误。
技术框架:FuzzWise采用多智能体框架,包含两个主要的LLM智能体。第一个智能体负责生成测试用例,它根据目标程序的输入格式和语义,生成各种可能的输入。第二个智能体充当预测代码覆盖率模块,它分析生成的测试用例,并预测其对当前语料库的覆盖率提升。该预测基于LLM对代码结构的理解和对测试用例执行路径的推断。整个流程是迭代的:生成测试用例 -> 预测覆盖率 -> 选择有价值的种子 -> 更新语料库 -> 循环。
关键创新:FuzzWise最重要的技术创新点在于使用LLM进行预测性代码覆盖率评估,从而避免了实际执行测试用例。这与传统的模糊测试方法形成了鲜明对比,传统方法需要实际执行测试用例才能确定其覆盖率。通过LLM的预测能力,FuzzWise可以在不运行程序的情况下,快速筛选出有价值的种子,大大提高了效率。
关键设计:FuzzWise的关键设计包括LLM的选择和训练、预测覆盖率的算法、以及种子选择策略。LLM需要具备强大的代码理解和生成能力。预测覆盖率的算法可能涉及分析测试用例的代码结构、识别关键分支和路径、以及预测这些分支和路径是否会被覆盖。种子选择策略则需要平衡覆盖率的提升和语料库的大小,避免过度膨胀。
🖼️ 关键图片
📊 实验亮点
实验结果表明,FuzzWise生成的测试用例数量明显少于基线方法,但在代码覆盖率和运行时错误触发方面表现更优。具体来说,FuzzWise在更短的时间内实现了更高的代码覆盖率,并发现了更多的漏洞。这证明了FuzzWise在生成初始语料库方面的效率和有效性。
🎯 应用场景
FuzzWise可应用于各种软件安全测试场景,尤其适用于执行代价高昂或不可行的程序,例如嵌入式系统、网络协议和大型复杂软件。通过智能生成高质量的初始语料库,FuzzWise能够显著提高模糊测试的效率和效果,减少漏洞发现的时间和成本,从而提升软件的整体安全性。未来,该方法有望扩展到更多类型的程序和测试场景,并与其他安全分析技术相结合。
📄 摘要(原文)
In mutation-based greybox fuzzing, generating high-quality input seeds for the initial corpus is essential for effective fuzzing. Rather than conducting separate phases for generating a large corpus and subsequently minimizing it, we propose FuzzWise which integrates them into one process to generate the optimal initial corpus of seeds (ICS). FuzzWise leverages a multi-agent framework based on Large Language Models (LLMs). The first LLM agent generates test cases for the target program. The second LLM agent, which functions as a predictive code coverage module, assesses whether each generated test case will enhance the overall coverage of the current corpus. The streamlined process allows each newly generated test seed to be immediately evaluated for its contribution to the overall coverage. FuzzWise employs a predictive approach using an LLM and eliminates the need for actual execution, saving computational resources and time, particularly in scenarios where the execution is not desirable or even impossible. Our empirical evaluation demonstrates that FuzzWise generates significantly fewer test cases than baseline methods. Despite the lower number of test cases, FuzzWise achieves high code coverage and triggers more runtime errors compared to the baselines. Moreover, it is more time-efficient and coverage-efficient in producing an initial corpus catching more errors.