A Survey of Freshness-Aware Wireless Networking with Reinforcement Learning
作者: Alimu Alibotaiken, Suyang Wang, Oluwaseun T. Ajayi, Yu Cheng
分类: cs.LG, eess.SY
发布日期: 2025-12-24
💡 一句话要点
综述:基于强化学习的面向信息新鲜度的无线网络研究
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 信息年龄 强化学习 无线网络 数据新鲜度 AoI B5G 6G
📋 核心要点
- 现有研究缺乏对信息新鲜度(AoI)在无线网络中作为统一学习问题的深入探讨,限制了对新兴无线系统新鲜度优化的有效性。
- 该综述从AoI角度出发,系统地研究了强化学习在无线网络新鲜度优化中的应用,并提出了一个以策略为中心的分类框架。
- 该研究总结了RL驱动的新鲜度控制的最新进展,并指出了延迟决策、随机变异性和跨层设计等方面的挑战,为未来研究奠定基础。
📝 摘要(中文)
信息年龄(AoI)已成为现代无线系统中数据新鲜度的核心指标。然而,现有的综述要么侧重于经典的AoI公式,要么泛泛地讨论无线网络中的强化学习(RL),而没有将新鲜度作为一个统一的学习问题来解决。为了弥补这一差距,本综述专门从AoI和广义新鲜度优化的角度考察RL。我们将AoI及其变体组织成原生、基于函数和面向应用的三大类,从而更清晰地了解如何在B5G和6G系统中对新鲜度进行建模。在此基础上,我们引入了一种以策略为中心的分类法,反映了与新鲜度最相关的决策,包括更新控制RL、介质访问RL、风险敏感RL和多智能体RL。这种结构为理解学习如何支持采样、调度、轨迹规划、介质访问和分布式协调提供了一个连贯的框架。我们进一步综合了RL驱动的新鲜度控制的最新进展,并强调了与延迟决策过程、随机变异性和跨层设计相关的开放挑战。目标是为下一代无线网络中基于学习的新鲜度优化建立一个统一的基础。
🔬 方法详解
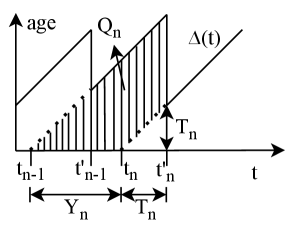
问题定义:现有无线网络研究中,信息年龄(AoI)作为衡量数据新鲜度的关键指标,但缺乏将AoI与强化学习(RL)相结合的系统性研究。现有的综述要么侧重于传统的AoI公式,要么宽泛地讨论RL在无线网络中的应用,未能将新鲜度作为一个统一的学习问题进行建模和优化。这导致了在B5G和6G等新兴无线系统中,难以有效地利用RL来提升数据的新鲜度。
核心思路:本综述的核心思路是将强化学习(RL)与信息年龄(AoI)相结合,构建一个统一的框架,用于在无线网络中优化数据的新鲜度。通过对AoI进行分类,并提出以策略为中心的RL分类法,该综述旨在为研究人员提供一个清晰的视角,了解如何利用RL来解决与新鲜度相关的各种问题,例如采样、调度、轨迹规划、介质访问和分布式协调。
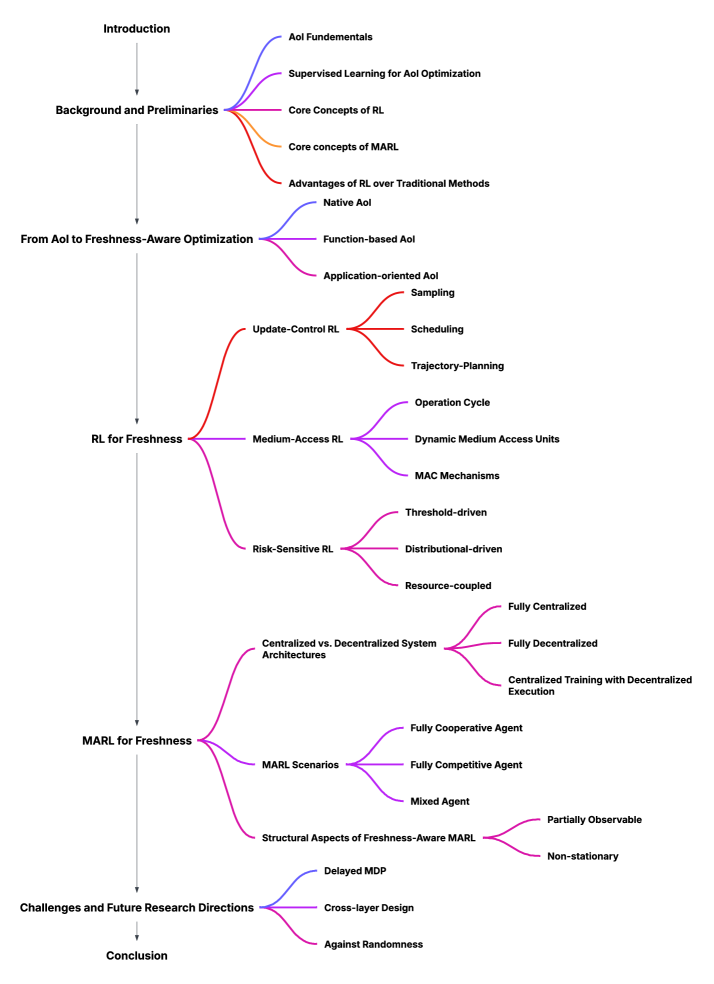
技术框架:该综述的技术框架主要包括三个部分:首先,对AoI及其变体进行分类,将其组织成原生、基于函数和面向应用的三大类。其次,提出一种以策略为中心的RL分类法,包括更新控制RL、介质访问RL、风险敏感RL和多智能体RL。最后,综合了RL驱动的新鲜度控制的最新进展,并指出了开放挑战。整个框架旨在为基于学习的新鲜度优化提供一个统一的基础。
关键创新:该综述的关键创新在于提出了一个以策略为中心的RL分类法,该分类法反映了与新鲜度最相关的决策。与传统的RL分类方法不同,该分类法更加关注如何利用RL来控制更新、访问介质、处理风险和进行多智能体协调,从而更有效地优化数据的新鲜度。此外,该综述还系统地总结了RL驱动的新鲜度控制的最新进展,并指出了未来的研究方向。
关键设计:该综述并没有涉及具体的参数设置或网络结构,而是侧重于对现有研究进行分类和总结。关键的设计在于对AoI和RL的分类方法,以及对未来研究方向的展望。例如,在AoI分类中,区分了原生、基于函数和面向应用的三种类型,从而更清晰地了解如何在不同的场景下对新鲜度进行建模。在RL分类中,提出了更新控制RL、介质访问RL、风险敏感RL和多智能体RL等四种类型,从而更有效地利用RL来解决与新鲜度相关的各种问题。
🖼️ 关键图片

📊 实验亮点
该综述系统地整理了基于强化学习的无线网络新鲜度优化方法,并从AoI和策略两个维度进行了分类,为研究人员提供了一个清晰的框架。此外,该综述还指出了延迟决策过程、随机变异性和跨层设计等方面的挑战,为未来的研究方向提供了有价值的参考。
🎯 应用场景
该研究成果可应用于各种需要高数据新鲜度的无线网络场景,例如:物联网(IoT)传感器网络、实时监控系统、自动驾驶车辆通信、以及工业自动化等。通过利用强化学习优化数据的新鲜度,可以提升系统的性能和可靠性,并为未来的6G网络设计提供指导。
📄 摘要(原文)
The age of information (AoI) has become a central measure of data freshness in modern wireless systems, yet existing surveys either focus on classical AoI formulations or provide broad discussions of reinforcement learning (RL) in wireless networks without addressing freshness as a unified learning problem. Motivated by this gap, this survey examines RL specifically through the lens of AoI and generalized freshness optimization. We organize AoI and its variants into native, function-based, and application-oriented families, providing a clearer view of how freshness should be modeled in B5G and 6G systems. Building on this foundation, we introduce a policy-centric taxonomy that reflects the decisions most relevant to freshness, consisting of update-control RL, medium-access RL, risk-sensitive RL, and multi-agent RL. This structure provides a coherent framework for understanding how learning can support sampling, scheduling, trajectory planning, medium access, and distributed coordination. We further synthesize recent progress in RL-driven freshness control and highlight open challenges related to delayed decision processes, stochastic variability, and cross-layer design. The goal is to establish a unified foundation for learning-based freshness optimization in next-generation wireless networks.