MiST: Understanding the Role of Mid-Stage Scientific Training in Developing Chemical Reasoning Models
作者: Andres M Bran, Tong Xie, Shai Pranesh, Jeffrey Meng, Xuan Vu Nguyen, Jeremy Goumaz, David Ming Segura, Ruizhi Xu, Dongzhan Zhou, Wenjie Zhang, Bram Hoex, Philippe Schwaller
分类: cs.LG, cond-mat.mtrl-sci
发布日期: 2025-12-24 (更新: 2026-01-26)
💡 一句话要点
提出MiST:通过中阶段科学训练提升化学推理模型性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 化学推理 大型语言模型 强化学习 中阶段训练 潜在可解性
📋 核心要点
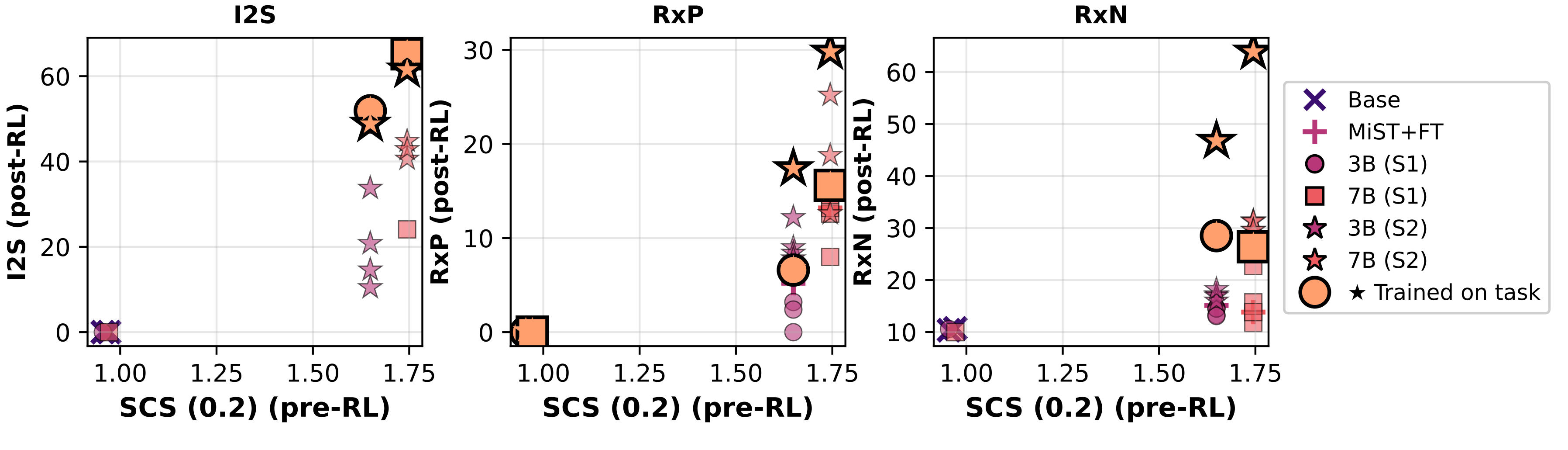
- 现有方法在利用强化学习提升化学推理能力时,受限于模型自身的“潜在可解性”,即模型需具备初步的正确答案预测能力。
- 论文提出中阶段科学训练(MiST),通过数据混合、持续预训练和监督微调,提升模型对化学知识的掌握和符号处理能力。
- 实验表明,MiST能显著提升模型在有机反应命名和无机材料生成等任务上的准确率,并生成可解释的推理过程。
📝 摘要(中文)
大型语言模型可以通过基于规则的奖励进行在线微调来发展推理能力。然而,最近的研究表明一个关键约束:强化学习只有在基础模型已经为正确答案分配了不可忽略的概率时才能成功——我们称之为“潜在可解性”。本文研究了化学推理能力的出现,以及这些先决条件对化学的意义。我们确定了基于强化学习的化学推理的两个必要条件:1) 符号能力,2) 潜在的化学知识。我们提出了中阶段科学训练(MiST):一套满足这些条件的中阶段训练技术,包括使用SMILES/CIF感知预处理的数据混合、在29亿tokens上继续预训练,以及在10亿tokens上进行监督微调。这些步骤将3B和7B模型的潜在可解性得分提高了高达1.8倍,并使强化学习能够将有机反应命名的前1准确率从10.9%提高到63.9%,并将无机材料生成的前1准确率从40.6%提高到67.4%。在其他具有挑战性的化学任务中也观察到了类似的结果,同时产生了可解释的推理轨迹。我们的结果定义了化学推理训练的明确先决条件,并强调了中阶段训练在解锁推理能力方面的更广泛作用。
🔬 方法详解
问题定义:现有的大型语言模型在化学推理任务中,即使通过强化学习进行微调,也往往难以取得理想效果。这是因为强化学习的成功依赖于模型本身已经具备一定的“潜在可解性”,即模型需要对正确的化学知识有一定的先验概率。现有方法缺乏有效提升模型潜在可解性的手段,导致强化学习无法充分发挥作用。
核心思路:论文的核心思路是通过中阶段科学训练(MiST)来提升模型的潜在可解性。MiST旨在使模型具备符号能力和潜在的化学知识,从而为后续的强化学习奠定基础。通过数据混合、持续预训练和监督微调等手段,让模型更好地理解和运用化学领域的知识。
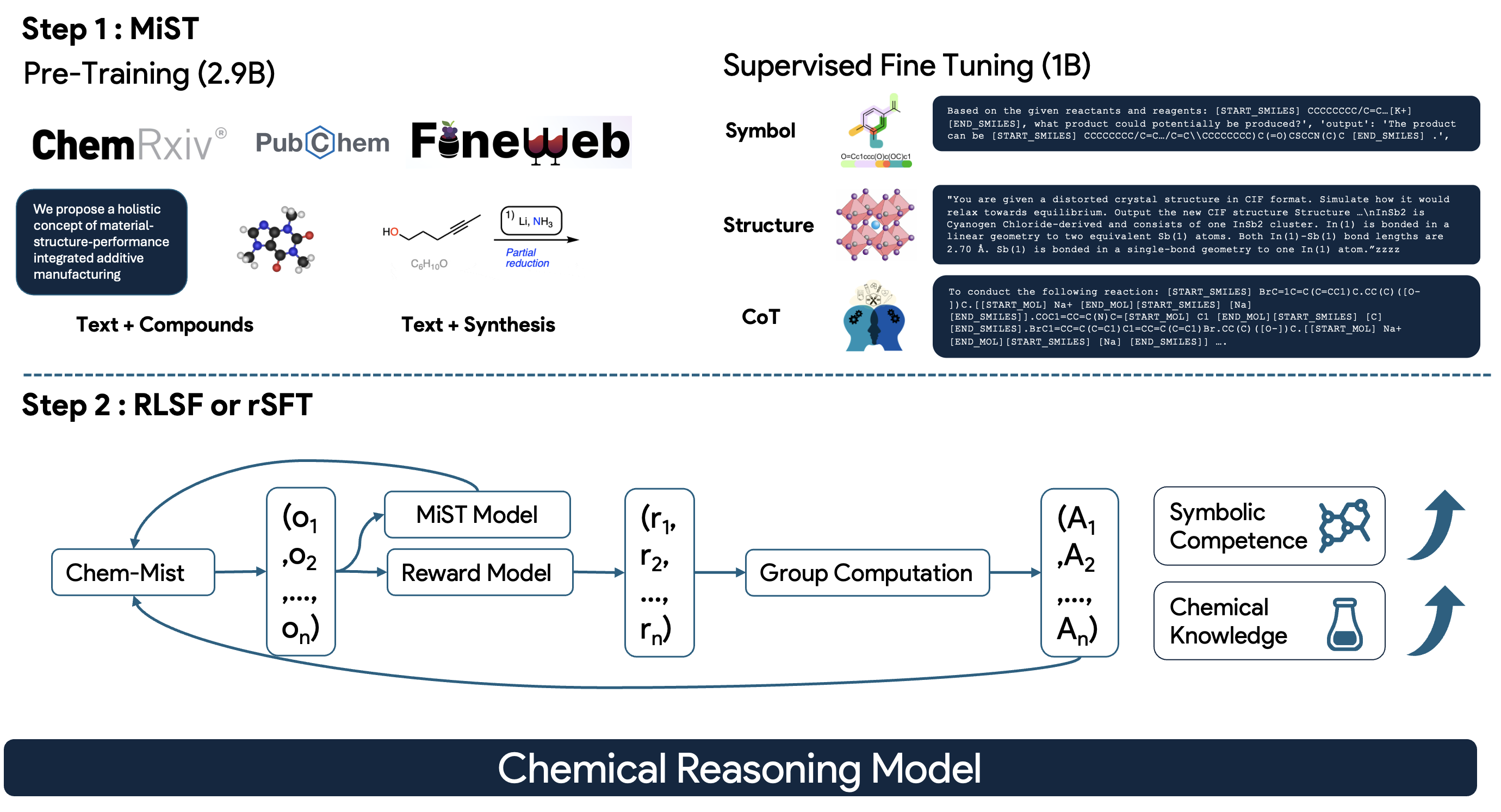
技术框架:MiST框架主要包含三个阶段:1) 数据混合与预处理:将SMILES和CIF格式的化学数据与通用文本数据混合,并进行SMILES/CIF感知的预处理,以增强模型对化学结构的理解。2) 持续预训练:在29亿个tokens上进行持续预训练,进一步提升模型对化学知识的掌握。3) 监督微调:在10亿个tokens上进行监督微调,使模型能够更好地完成特定的化学推理任务。
关键创新:MiST的关键创新在于提出了“中阶段科学训练”的概念,并将其应用于化学推理模型的训练。与传统的端到端训练方法不同,MiST强调在强化学习之前,通过一系列有针对性的训练步骤,提升模型的潜在可解性。这种方法能够更有效地利用强化学习的优势,从而取得更好的性能。
关键设计:在数据混合阶段,论文采用了SMILES/CIF感知的预处理方法,例如对SMILES字符串进行规范化和增强。在持续预训练阶段,论文采用了Masked Language Modeling (MLM) 目标,并调整了masking策略,以更好地适应化学数据的特点。在监督微调阶段,论文采用了交叉熵损失函数,并对模型进行了充分的调优。
🖼️ 关键图片
📊 实验亮点
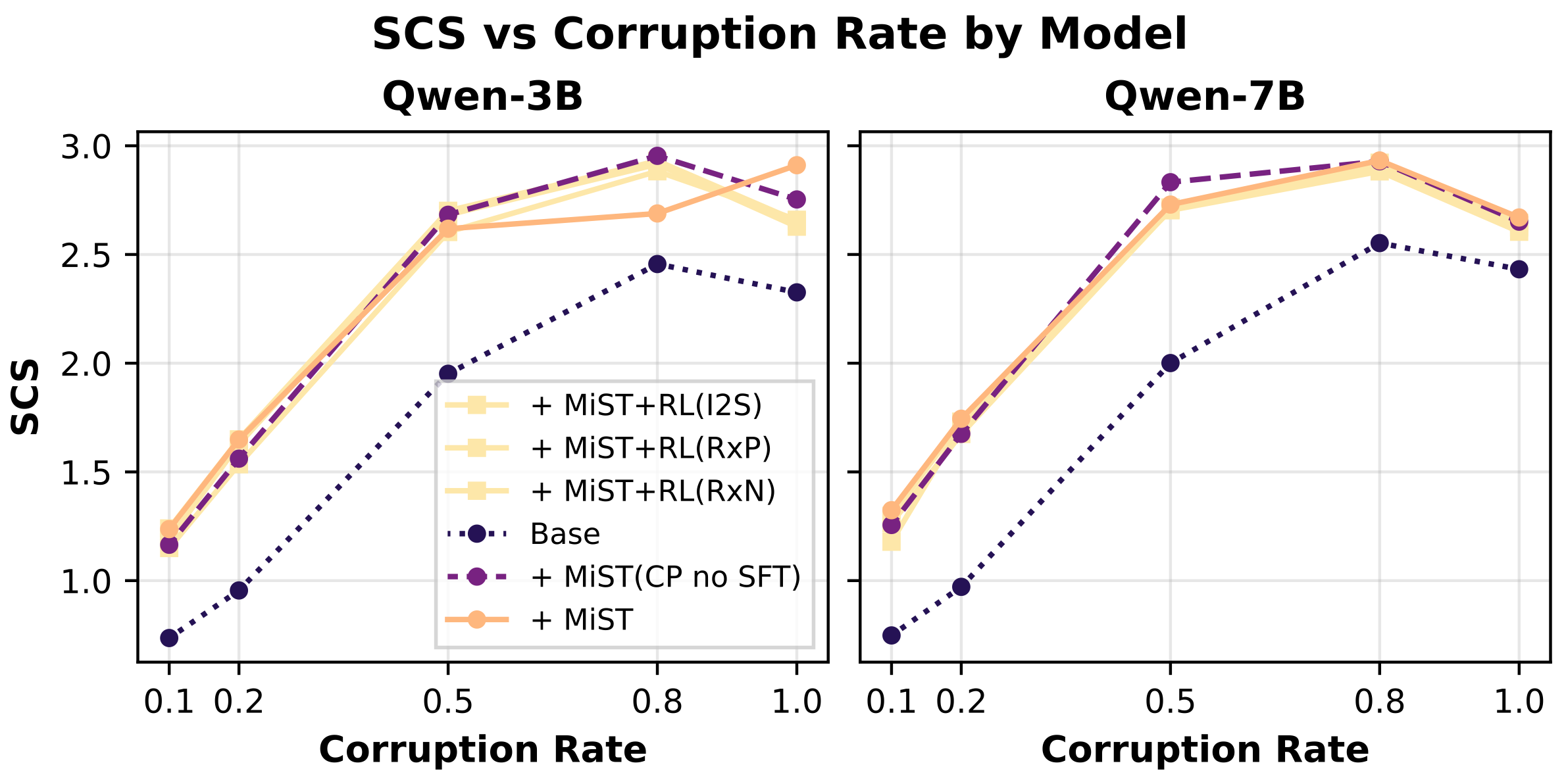
实验结果表明,MiST能够显著提升模型的化学推理能力。在有机反应命名任务中,MiST将top-1准确率从10.9%提升到63.9%。在无机材料生成任务中,MiST将top-1准确率从40.6%提升到67.4%。此外,MiST还能够生成可解释的推理轨迹,有助于理解模型的决策过程。
🎯 应用场景
该研究成果可应用于化学领域的多个方面,例如有机反应预测、新材料设计、药物发现等。通过提升化学推理模型的性能,可以加速化学研究的进程,降低实验成本,并发现新的化学知识。此外,该研究提出的中阶段训练方法也为其他科学领域的模型训练提供了借鉴。
📄 摘要(原文)
Large Language Models can develop reasoning capabilities through online fine-tuning with rule-based rewards. However, recent studies reveal a critical constraint: reinforcement learning succeeds only when the base model already assigns non-negligible probability to correct answers -- a property we term 'latent solvability'. This work investigates the emergence of chemical reasoning capabilities and what these prerequisites mean for chemistry. We identify two necessary conditions for RL-based chemical reasoning: 1) Symbolic competence, and 2) Latent chemical knowledge. We propose mid-stage scientific training (MiST): a set of mid-stage training techniques to satisfy these, including data-mixing with SMILES/CIF-aware pre-processing, continued pre-training on 2.9B tokens, and supervised fine-tuning on 1B tokens. These steps raise the latent-solvability score on 3B and 7B models by up to 1.8x, and enable RL to lift top-1 accuracy from 10.9 to 63.9% on organic reaction naming, and from 40.6 to 67.4% on inorganic material generation. Similar results are observed for other challenging chemical tasks, while producing interpretable reasoning traces. Our results define clear prerequisites for chemical reasoning training and highlight the broader role of mid-stage training in unlocking reasoning capabilities.