Masking Teacher and Reinforcing Student for Distilling Vision-Language Models
作者: Byung-Kwan Lee, Yu-Chiang Frank Wang, Ryo Hachiuma
分类: cs.LG, cs.AI, cs.CV
发布日期: 2025-12-23
💡 一句话要点
提出Masters框架,通过掩码教师模型和强化学生模型,实现视觉-语言模型的有效蒸馏。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 知识蒸馏 强化学习 模型压缩 掩码学习
📋 核心要点
- 现有视觉-语言模型体积庞大,难以部署在资源受限设备上,而直接蒸馏由于师生模型差距过大,效果不佳。
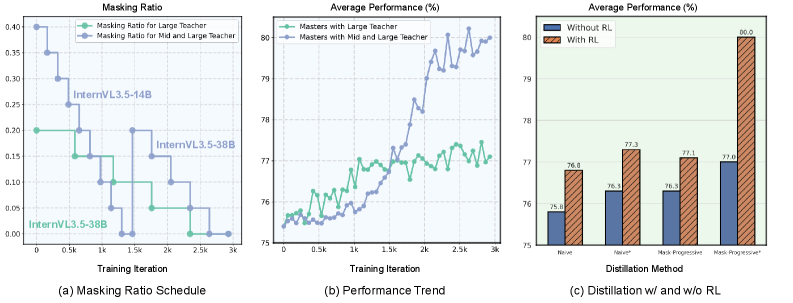
- Masters框架通过掩码教师模型降低复杂度,并采用渐进式恢复策略,使学生模型能够平滑稳定地学习。
- Masters采用离线强化学习,利用预生成的教师模型响应进行指导,避免了在线思考-回答过程的计算开销。
📝 摘要(中文)
大规模视觉-语言模型(VLMs)最近在多模态理解方面取得了显著进展,但其庞大的规模使其难以部署在移动或边缘设备上。这就需要紧凑而强大的VLMs,能够有效地从强大的大型教师模型中学习。然而,由于它们巨大的尺寸差距,从大型教师模型向小型学生模型提炼知识仍然具有挑战性:学生模型通常无法重现教师模型复杂的高维表示,导致学习不稳定和性能下降。为了解决这个问题,我们提出了Masters(Masking Teacher and Reinforcing Student),一个掩码渐进强化学习(RL)蒸馏框架。Masters首先掩盖教师模型的非主导权重以降低不必要的复杂性,然后在训练过程中逐步恢复教师模型,从而逐渐增加其容量。这种策略使学生模型能够以平滑和稳定的方式从教师模型中学习更丰富的表示。为了进一步完善知识转移,Masters集成了离线RL阶段,并具有两个互补的奖励:一个衡量生成响应正确性的准确性奖励,以及一个量化从教师模型到学生模型转移响应的难易程度的蒸馏奖励。与计算成本高昂且生成冗长响应的在线思考-回答RL范式不同,我们的离线RL利用来自掩码教师模型的预生成响应。这些提供了丰富而有效的指导,使学生模型能够在不需要思考-回答过程的情况下实现强大的性能。
🔬 方法详解
问题定义:论文旨在解决将大型视觉-语言模型(VLM)的知识有效迁移到小型学生模型的问题。现有方法直接蒸馏时,由于师生模型容量差距过大,学生模型难以学习教师模型复杂的高维表示,导致性能下降和训练不稳定。
核心思路:论文的核心思路是通过逐步降低教师模型的复杂度,并采用强化学习的方式引导学生模型学习。具体来说,首先通过掩码操作降低教师模型的复杂度,然后逐步恢复教师模型的容量,使学生模型能够平滑地学习。同时,利用离线强化学习,通过预生成的教师模型响应来指导学生模型的训练。
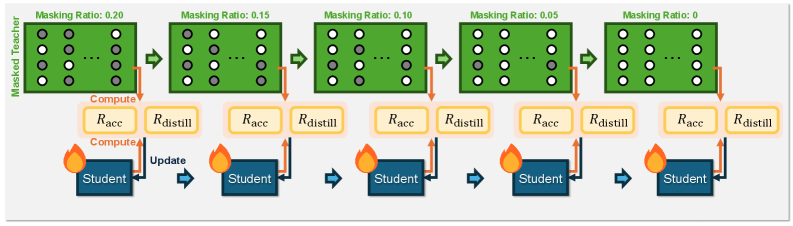
技术框架:Masters框架包含两个主要阶段:掩码教师模型和强化学生模型。首先,对教师模型进行掩码操作,移除非重要的权重,降低模型复杂度。然后,利用掩码后的教师模型生成响应,并使用这些响应作为离线强化学习的训练数据。在强化学习阶段,学生模型通过最大化准确率奖励和蒸馏奖励来学习教师模型的知识。蒸馏奖励衡量了学生模型模仿教师模型响应的难易程度。
关键创新:该论文的关键创新在于提出了掩码渐进强化学习的蒸馏框架。与传统的蒸馏方法相比,该方法能够更好地处理师生模型容量差距过大的问题。此外,该论文还提出了利用离线强化学习进行知识迁移的方法,避免了在线思考-回答过程的计算开销。
关键设计:在掩码阶段,论文使用权重幅度作为重要性指标,移除幅度较小的权重。在强化学习阶段,论文设计了准确率奖励和蒸馏奖励,分别衡量学生模型的正确性和模仿能力。蒸馏奖励的具体形式可以是KL散度或MSE损失等。此外,论文还采用了渐进式恢复策略,逐步增加教师模型的容量。
🖼️ 关键图片

📊 实验亮点
论文提出的Masters框架在多个视觉-语言任务上取得了显著的性能提升。实验结果表明,与传统的蒸馏方法相比,Masters框架能够更好地将知识从大型教师模型迁移到小型学生模型,并在保持模型体积较小的同时,显著提高模型的准确率和效率。具体性能数据在论文中给出。
🎯 应用场景
该研究成果可应用于将大型视觉-语言模型部署到资源受限的设备上,例如移动设备、嵌入式系统和边缘服务器。这使得在这些设备上运行复杂的视觉-语言任务成为可能,例如图像描述、视觉问答和多模态检索。此外,该方法还可以用于加速视觉-语言模型的训练,并提高模型的泛化能力。
📄 摘要(原文)
Large-scale vision-language models (VLMs) have recently achieved remarkable multimodal understanding, but their massive size makes them impractical for deployment on mobile or edge devices. This raises the need for compact yet capable VLMs that can efficiently learn from powerful large teachers. However, distilling knowledge from a large teacher to a small student remains challenging due to their large size gap: the student often fails to reproduce the teacher's complex, high-dimensional representations, leading to unstable learning and degraded performance. To address this, we propose Masters (Masking Teacher and Reinforcing Student), a mask-progressive reinforcement learning (RL) distillation framework. Masters first masks non-dominant weights of the teacher to reduce unnecessary complexity, then progressively restores the teacher by gradually increasing its capacity during training. This strategy allows the student to learn richer representations from the teacher in a smooth and stable manner. To further refine knowledge transfer, Masters integrates an offline RL stage with two complementary rewards: an accuracy reward that measures the correctness of the generated responses, and a distillation reward that quantifies the ease of transferring responses from teacher to student. Unlike online think-answer RL paradigms that are computationally expensive and generate lengthy responses, our offline RL leverages pre-generated responses from masked teachers. These provide rich yet efficient guidance, enabling students to achieve strong performance without requiring the think-answer process.