When Less is More: 8-bit Quantization Improves Continual Learning in Large Language Models
作者: Michael S. Zhang, Rishi A. Ruia, Arnav Kewalram, Saathvik Dharmapuram, Utkarsh Sharma, Kevin Zhu
分类: cs.LG, cs.AI
发布日期: 2025-12-22
🔗 代码/项目: GITHUB
💡 一句话要点
量化提升大语言模型持续学习能力:INT8优于FP16
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 持续学习 量化 大语言模型 灾难性遗忘 重放缓冲区
📋 核心要点
- 持续学习中,灾难性遗忘是关键挑战,尤其是在模型量化后,性能会显著下降。
- 论文核心思想是利用量化引入的噪声作为正则化手段,抑制模型对新任务的过拟合,从而提升持续学习性能。
- 实验表明,INT8量化模型在持续学习中表现优于FP16,尤其是在代码生成任务上,且小比例重放缓冲区即可显著提升性能。
📝 摘要(中文)
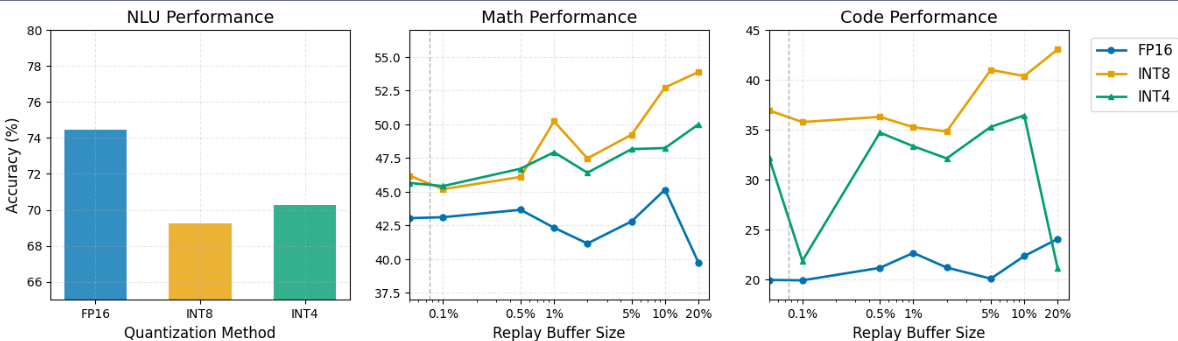
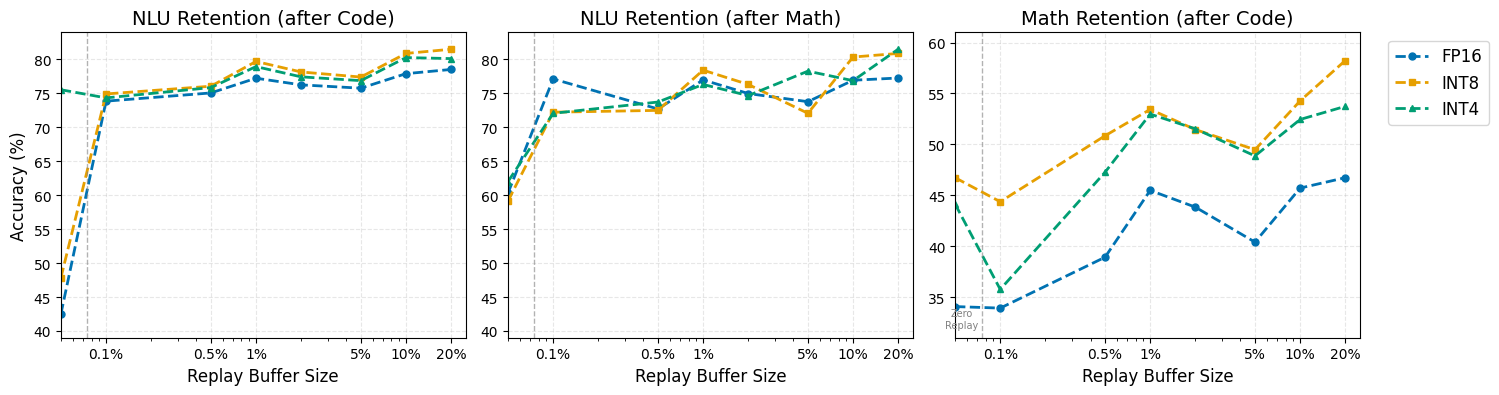
灾难性遗忘是持续学习中的一个根本挑战,尤其是在模型被量化以提高部署效率时。本文系统地研究了大型语言模型中量化精度(FP16、INT8、INT4)和重放缓冲区策略之间的相互作用,揭示了意想不到的动态。虽然FP16在初始任务性能上表现出色(在NLU上达到74.44%),但我们观察到在后续任务中出现了显著的反转:量化模型在最终任务的前向准确率上比FP16高出8-15%,其中INT4在代码生成方面的性能几乎是FP16的两倍(40% vs 20%)。至关重要的是,即使是最小的重放缓冲区(0.1%)也能显著提高保留率——在数学训练后,所有精度级别的NLU保留率从45%提高到65%——其中INT8始终在学习可塑性和知识保留之间实现最佳平衡。我们假设量化引起的噪声充当隐式正则化,防止高精度模型过度拟合新任务梯度。这些发现挑战了传统观念,即更高的精度总是更可取的,而是表明INT8量化既提供了计算效率,又提供了卓越的持续学习动态。我们的结果为在持续学习场景中部署压缩模型提供了实用的指导:小型重放缓冲区(1-2%)足以用于NLU任务,而数学和代码则受益于中等缓冲区(5-10%),并且量化模型需要比FP16更少的重放才能实现相当的保留率。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在持续学习过程中,由于灾难性遗忘导致的性能下降问题。现有方法,如FP16高精度模型,虽然在初始任务上表现良好,但在后续任务中容易过拟合,导致性能显著下降。量化模型虽然计算效率高,但其在持续学习中的表现未被充分研究。
核心思路:论文的核心思路是利用量化过程引入的噪声作为一种隐式的正则化手段。这种噪声可以防止模型过度拟合新任务的梯度,从而提高模型在持续学习过程中的知识保留能力。作者认为,适当的量化精度(如INT8)可以在学习新知识和保持旧知识之间取得更好的平衡。
技术框架:论文采用标准的持续学习框架,包括多个连续的任务训练阶段。模型首先在初始任务上进行训练,然后依次在后续任务上进行训练。在每个任务训练阶段,模型使用不同的量化精度(FP16、INT8、INT4)进行训练,并结合不同大小的重放缓冲区来缓解灾难性遗忘。实验评估了模型在每个任务上的性能,以及在所有任务训练完成后,模型在初始任务上的保留率。
关键创新:论文最重要的技术创新点在于发现量化精度对持续学习性能的影响存在非单调关系。传统观点认为,更高的精度总是更好,但论文表明,在持续学习中,适当的量化精度(如INT8)可以提供更好的性能。这种现象的原因是量化噪声可以作为一种隐式的正则化手段,防止模型过拟合。
关键设计:论文的关键设计包括:1) 系统地研究了不同量化精度(FP16、INT8、INT4)对持续学习性能的影响;2) 探索了不同大小的重放缓冲区对缓解灾难性遗忘的作用;3) 实验评估了模型在不同任务上的性能,以及在所有任务训练完成后,模型在初始任务上的保留率。论文还分析了量化噪声对模型训练的影响,并提出了量化噪声作为正则化手段的假设。
🖼️ 关键图片
📊 实验亮点
实验结果表明,INT8量化模型在持续学习中表现优于FP16模型,尤其是在代码生成任务上,INT4的性能几乎是FP16的两倍(40% vs 20%)。即使是最小的重放缓冲区(0.1%)也能显著提高保留率,例如在数学训练后,所有精度级别的NLU保留率从45%提高到65%。INT8在学习可塑性和知识保留之间实现了最佳平衡。
🎯 应用场景
该研究成果可应用于各种需要持续学习的场景,例如:智能客服、自动驾驶、机器人等。通过使用量化模型和适当的重放缓冲区,可以在保证计算效率的同时,提高模型在不断变化的环境中的适应能力。该研究有助于开发更高效、更鲁棒的持续学习系统。
📄 摘要(原文)
Catastrophic forgetting poses a fundamental challenge in continual learning, particularly when models are quantized for deployment efficiency. We systematically investigate the interplay between quantization precision (FP16, INT8, INT4) and replay buffer strategies in large language models, revealing unexpected dynamics. While FP16 achieves superior initial task performance (74.44% on NLU), we observe a striking inversion on subsequent tasks: quantized models outperform FP16 by 8-15% on final task forward accuracy, with INT4 achieving nearly double FP16's performance on Code generation (40% vs 20%). Critically, even minimal replay buffers (0.1%) dramatically improve retention - increasing NLU retention after Math training from 45% to 65% across all precision levels - with INT8 consistently achieving the optimal balance between learning plasticity and knowledge retention. We hypothesize that quantization-induced noise acts as implicit regularization, preventing the overfitting to new task gradients that plagues high-precision models. These findings challenge the conventional wisdom that higher precision is always preferable, suggesting instead that INT8 quantization offers both computational efficiency and superior continual learning dynamics. Our results provide practical guidelines for deploying compressed models in continual learning scenarios: small replay buffers (1-2%) suffice for NLU tasks, while Math and Code benefit from moderate buffers (5-10%), with quantized models requiring less replay than FP16 to achieve comparable retention. Code is available at https://github.com/Festyve/LessIsMore.