Gaussian-Mixture-Model Q-Functions for Policy Iteration in Reinforcement Learning
作者: Minh Vu, Konstantinos Slavakis
分类: cs.LG
发布日期: 2025-12-21
备注: This work has been submitted to the IEEE for possible publication
💡 一句话要点
提出基于高斯混合模型Q函数的策略迭代强化学习方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 策略迭代 Q函数 高斯混合模型 黎曼优化
📋 核心要点
- 传统强化学习方法在处理复杂问题时,Q函数的近似精度和计算效率面临挑战。
- 论文提出使用高斯混合模型(GMM)直接近似Q函数,并在黎曼流形上优化GMM参数。
- 实验表明,该方法在多个基准测试中表现出竞争力,甚至优于现有方法,且计算成本更低。
📝 摘要(中文)
本文提出了一种新颖的函数近似方法,将高斯混合模型(GMMs)直接用作Q函数损失的替代。这种参数化模型,称为GMM-QFs,具有强大的表示能力,可以证明它们是广泛函数类上的通用逼近器。GMM-QFs进一步嵌入到贝尔曼残差中,其可学习参数(固定数量的混合权重,以及高斯均值向量和协方差矩阵)通过黎曼流形上的优化从数据中推断出来。这种参数空间的几何视角自然地将黎曼优化融入到标准策略迭代框架的策略评估步骤中。论文建立了严格的理论结果,并且数值实验表明,即使在没有访问经验数据的情况下,GMM-QFs也能提供有竞争力的性能,并且在某些情况下,优于一系列基准强化学习任务中的最先进方法,同时保持比依赖经验数据的深度学习方法小得多的计算量。
🔬 方法详解
问题定义:传统强化学习中,Q函数的精确估计至关重要,但使用传统函数近似方法(如线性函数或神经网络)在高维状态空间中存在表示能力不足或计算复杂度过高的问题。尤其是在策略迭代过程中,策略评估需要反复更新Q函数,效率成为瓶颈。现有方法通常依赖大量的经验数据,计算资源消耗大。
核心思路:论文的核心在于使用高斯混合模型(GMM)来直接近似Q函数。GMM具有良好的函数逼近能力,并且其参数可以通过优化方法进行学习。通过将Q函数表示为GMM,可以将策略评估问题转化为GMM参数的优化问题。此外,论文利用黎曼流形优化,考虑了GMM参数空间的几何结构,从而更有效地进行参数更新。
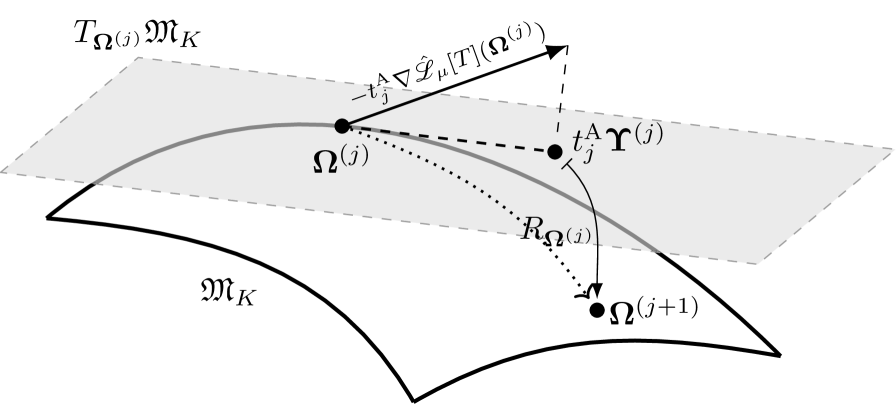
技术框架:整体框架遵循策略迭代的范式,包括策略评估和策略改进两个阶段。在策略评估阶段,使用GMM-QF来近似Q函数,并通过最小化贝尔曼残差来更新GMM的参数。参数更新过程在黎曼流形上进行,利用黎曼优化算法。在策略改进阶段,根据更新后的Q函数来更新策略。整个过程迭代进行,直到策略收敛。
关键创新:最重要的创新点在于将GMM作为Q函数的直接近似,并结合黎曼优化来更新GMM参数。与传统的Q函数近似方法相比,GMM-QF具有更强的表示能力和更高的计算效率。黎曼优化考虑了GMM参数空间的几何结构,能够更有效地进行参数更新,避免了传统梯度下降方法可能遇到的问题。
关键设计:GMM-QF的关键参数包括混合成分的数量、每个高斯成分的均值向量和协方差矩阵。损失函数采用贝尔曼残差的平方和,用于衡量Q函数的近似误差。黎曼优化算法的选择和参数设置对算法的性能有重要影响。论文可能采用了特定的黎曼优化算法,并针对GMM参数空间进行了优化。
🖼️ 关键图片


📊 实验亮点
实验结果表明,GMM-QF在多个基准强化学习任务中表现出竞争力,甚至优于现有方法。特别是在某些任务中,GMM-QF在没有访问经验数据的情况下,也能取得与依赖经验数据的深度学习方法相当甚至更好的性能。此外,GMM-QF的计算量明显小于深度学习方法,验证了其高效性。
🎯 应用场景
该研究成果可应用于资源受限的强化学习场景,例如机器人控制、自动驾驶和游戏AI等。由于GMM-QF具有较小的计算 footprint,因此特别适合在嵌入式系统或移动设备上部署。此外,该方法在没有大量经验数据的情况下也能取得较好的性能,因此可以应用于探索成本较高的环境中。
📄 摘要(原文)
Unlike their conventional use as estimators of probability density functions in reinforcement learning (RL), this paper introduces a novel function-approximation role for Gaussian mixture models (GMMs) as direct surrogates for Q-function losses. These parametric models, termed GMM-QFs, possess substantial representational capacity, as they are shown to be universal approximators over a broad class of functions. They are further embedded within Bellman residuals, where their learnable parameters -- a fixed number of mixing weights, together with Gaussian mean vectors and covariance matrices -- are inferred from data via optimization on a Riemannian manifold. This geometric perspective on the parameter space naturally incorporates Riemannian optimization into the policy-evaluation step of standard policy-iteration frameworks. Rigorous theoretical results are established, and supporting numerical tests show that, even without access to experience data, GMM-QFs deliver competitive performance and, in some cases, outperform state-of-the-art approaches across a range of benchmark RL tasks, all while maintaining a significantly smaller computational footprint than deep-learning methods that rely on experience data.